支付宝交易行为数据分析
数据集介绍:
该数据集可在合鲸社区获取,具体记录了支付宝交易行为相关数据,包括交易id、订单类型、交易类型、交易金额等字段。
数据及项目链接:点击进入
数据集大小:(79791, 28)
数据说明:
| 字段名 | 数据类型 | 字段描述 | 示例值 |
|---|---|---|---|
| id | String | 每产生一次交易就会生成一项独一字符串 | 2429838 |
| uuid | String | 每产生一次交易就会生成一项独一字符串 | de9a2ff8-fcf6-479e-9872-c513814837db |
| alipay_account_uuid | String | 支付宝用户uuid | 6eb9cd05-9ba7-408f-9591-f1d8c1658b58 |
| alipay_order_no | String | 支付宝订单号 | 2012042328668262 |
| merchant_order_no | String | 商业订单编号 | T200P1072190597338537 |
| order_type | String | 订单类型 | TRADE |
| order_status | String | 订单状态 | TRADE_FINISH |
| owner_user_id | String | 所有者用户id | 2088511141397640 |
| owner_logon_id | String | 所有者登录id | min*@sina.com |
| owner_name | String | 用户姓名 | * 圳千里驹电子商务有限公司 |
| opposite_user_id | String | 交易对方id | 2088602067793880 |
| opposite_name | String | 交易对方名字 | * 承文 |
| 银行关联 | String | 银行关联 | 招商银行 |
| opposite_logon_id | String | 交易对方登录id | 136** 5556 |
| partner_id | String | 合作伙伴id | 2088511216940210 |
| order_title | String | 支付宝交易商品名称 | 网易产品 |
| type | String | 交易类型 | 转账 |
| 二级 | String | 二级消费类型 | 花费充值 |
| total_amount | Price | 订单总金额,单位为元,精确到小数点后两位 | 18.8 |
| service_charge | String | 交易手续费等服务费 | 0 |
| order_from | String | 订单来源 | TAOBAO |
| create_time | String | 交易重建时间 | 11/10/14 20:49 |
| modified_time | String | 交易修改时间 | 11/25/14 20:50 |
| date | String | date | 9 |
| in_out_type | String | 交易支出或收入 | out |
| insert_time | String | insert time | 10/14/15 16:21 |
| update_time | String | update time | 10/14/15 16:21 |
| 工作日 | String | 交易时间为工作日或周末 | 工作日 |
分析思路
1、数据字段探索
- 该数据集字段较多,首先需要探索一些数据字段的具体含义及所包含的类型值、是否有缺失等。
2、数据处理
- 主要是缺失值、时间字段等的处理。
3、具体用户行为分析
- 通过字段可以简单了解到支付宝用户的交易行为比较关键的几点主要是交易类型、交易来源、交易内容和交易时间,所以用户行为的分析主要关注于这四个方面。
4、用户分类
- 根据用户的不同类型探索对应行为喜好等,以更好对不同用户进行服务。
具体分析:
一、数据字段探索
1、先弄清楚数据集结构及其各字段的含义确定后续数据集的处理关键以及分析方向。
import pandas as pd
# 读取数据
data = pd.read_excel(r'/home/mw/input/zhifubao9423/支付宝数据源.xlsx')
# 查看每一列的数据信息了解字段
for column in data.columns:
print("字段 ", column, ":")
print("部分字段值:", data[column].unique()[0:8])
print("字段值数量:", data[column].unique().shape[0])
print("字段缺失值情况:", data[column].isnull().sum(), "\n")
- 部分字段情况:
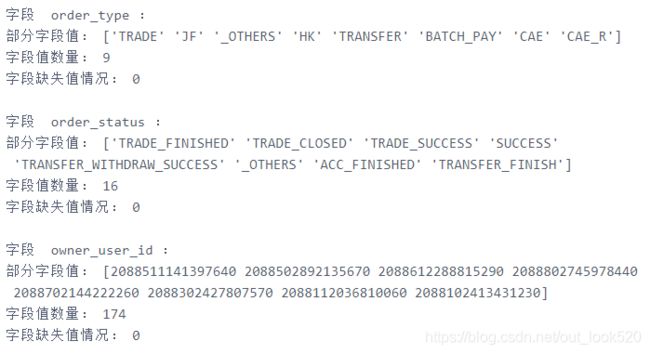
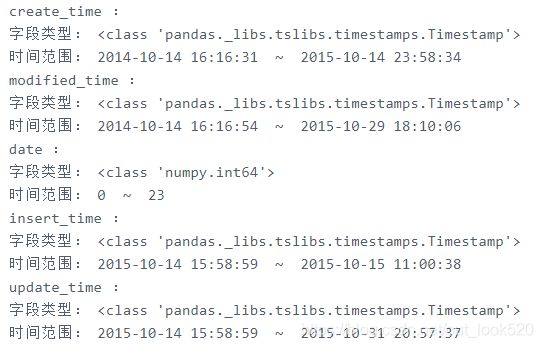
- 相关时间字段探索
time = data[['create_time', 'modified_time', 'date', 'insert_time', 'update_time']]
for column in time.columns:
print(column, ":")
print("字段类型:", type(time[column][0]))
print("时间范围:", time[column].min(), " ~ ", time[column].max())
-
字段探索分析
1)数据缺失情况分析:
严重缺失字段:银行关联(77324、缺失严重,无法进行准确的相关分析,可删除该字段)、二级(64488、二级分类只针对部分商品,可考虑合并到分类信息中或重点分析商品分类)
一般缺失字段:merchant_order_no(9423)、owner_login_id(28008)、owner_name(17265)、opposite_user_id(2266)、opposite_name(1091)、opposite_logon_id(21272)、partner_id(30788)、order_title(18)、type(文本分类结果)(18)
这些有缺失值的字段大多为用户、商品编号或交易对方的基本信息,对具体用户交易行为分析的必要性不大,可不用处理
2)字段根据其含义及分析重要性可分为两类:用户行为分析关键字段和其他
用户行为分析关键字段:- order_type:订单类型,包含 [‘TRADE’、‘JF’、‘OTHERS’、‘HK’、‘TANSFER’、‘BATCHPAY’、‘CAE’、‘CAER’、‘PEERPAY’] 九类订单类型
- order_status:订单状态,包含16种订单状态(交易完成、交易关闭、代付成功、等待卖家发货等)
- owner_name:用户姓名,可用于分类用户,企业用户或个人用户
- order_title(支付宝交易商品名称):交易商品名称
- type(文本分类结果):交易商品类别
- total_amount:交易总金额
- order_from:订单来源,包括 [‘ALIPAY’, ‘OTHER’, ‘TAOBAO’] 三大主要来源
- create_time:订单创建时间
- in_out_type:交易类型,支出或收入
- 工作日:工作日或周末交易
其他:主要包括用户基本信息、商品编码信息、交易对方基本信息等,与用户行为分析无太大关系
3)关于时间字段,可以看到时间字段都是Timestamp类型的,无需进行时间格式转换,关键时间在于订单创建时间,可构造订单创建月份、季度、星期等字段进行时间序列的分析。订单创建时间分布在2014年10月14日 - 2015年10月14日之间,刚好一年时间,可以探索这一年时间的订单分布情况
二、数据处理
- 提取前面总结的关键字段信息,并对时间字段进行构造
key_data = pd.DataFrame({
'订单类型': data['order_type'],
'订单状态': data['order_status'],
'用户姓名': data['owner_name'],
'交易商品名称': data['order_title(支付宝交易商品名称)'],
'交易商品类别': data['type(文本分类结果)'],
'交易总金额': data['total_amount'],
'订单来源': data['order_from'],
'订单创建时间': data['create_time'],
'交易类型': data['in_out_type'],
'交易时段': data['工作日']
})
key_data['订单创建时点'] = [h.hour for h in key_data['订单创建时间']]
key_data['订单创建月份'] = [m.month for m in key_data['订单创建时间']]
key_data['订单创建周'] = [w.weekday_name for w in key_data['订单创建时间']]
key_data

三、用户行为分析
- 从支付渠道、订单来源、订单内容、订单时间、时间序列等多方面进行分析。
1、支付渠道分析
支付渠道信息可在订单类型中展示出来,主要支付渠道包含了交易(TRADE),CAE代扣(CAE),代付(PEERPAY),转账到卡(TRANSFER)等。
group1 = key_data.groupby(key_data['订单类型']).agg({'交易总金额': ['count', 'sum', 'mean']})
group1['交易总金额'].sort_values(by='count', ascending=False)

可以看到支付宝用户最主要的支付渠道为交易(TRADE),其次就是CAE代扣(CAE)了。
2、订单来源分析
订单来源主要包括淘宝(TAOBAO)、支付宝(ALIPAY)和其它(OTHER)。
group2 = key_data.groupby(key_data['订单来源']).agg({'交易总金额': ['count', 'sum', 'mean']})
group2['交易总金额'].sort_values(by='count', ascending=False)

可以看到订单的大部分来源是支付宝(ALIPAY),支付宝的成交金额也是最高的。
3、二级分析
分析不同订单类型以及不同订单来源下主要的交易商品类型分布情况。
- 从订单类型即交易渠道出发
group3 = key_data.groupby(['订单类型', '交易商品类别']).agg({'交易总金额': ['count', 'sum', 'mean']})
group3['交易总金额']

可以看到一些特殊的支付渠道是用于支付特定商品的,TRADE主要用于支付各种生活交易,CAE代扣主要用于一些保险、贷款等的代扣。
- 从交易来源出发
group4 = key_data.groupby(['订单来源', '交易商品类别']).agg({'交易总金额': ['count', 'sum', 'mean']})
group4['交易总金额']
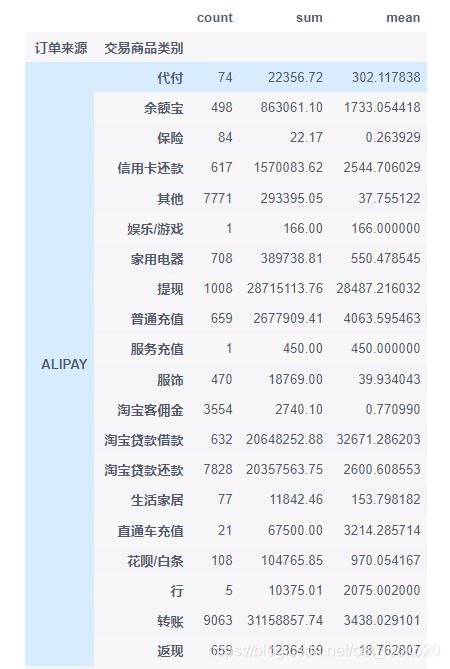
可以看出在ALIPAY在淘宝贷款借款、淘宝贷款还款、信用卡还款、提现、转账等金融服务上占比较高,taobao则在娱乐/游戏模块上占比较高,OTHER在家用电器、服务费用、服饰上占比较高。
4、工作日与否交易情况分析
group5 = key_data.groupby(key_data['交易时段']).agg({'交易总金额': ['count', 'sum']})
df = group5['交易总金额']
df['mean'] = [0, 0]
df['mean']['周末'] = df['sum']['周末'] / 2
df['mean']['工作日'] = df['sum']['工作日'] / 5
df['mean_count'] = [0, 0]
df['mean_count']['周末'] = df['count']['周末'] / 2
df['mean_count']['工作日'] = df['count']['工作日'] / 5
df
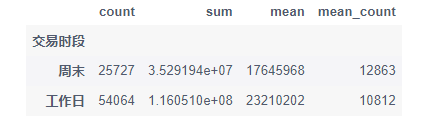
工作日的订单数更多,成交金额也更多,在工作日的日均订单金额也更多,但在周末的订单数会更多一点,说明用户在周末会更活跃,在工作日消费更高,可以在工作日推出更多价格高质量好的商品,在周末做活动或是推出性价比更高的商品,刺激用户消费。
5、时间序列分析
1)整体交易情况分析
分析月订单数、单笔交易平均金额及月订单总金额变化。
import matplotlib.pyplot as plt
# 统计数据
group6 = key_data.groupby(key_data['订单创建月份']).agg({'交易总金额': ['count', 'mean', 'sum']})['交易总金额']
# 设置画布
fig, axes = plt.subplots(1, 1, figsize=(12, 8))
# 绘制月订单数、单笔交易平均金额数柱状图
axes.bar(np.arange(1, 13), group6['count'], color='red', label='月订单数', width=0.35, alpha=0.6)
axes.bar(np.arange(1, 13)+0.35, group6['mean'], color='orange', label='单笔交易平均金额', width=0.35, alpha=0.6)
# 设置标签刻度
axes.set_ylim((0, 13500))
axes.set_ylabel("数值")
axes.set_xlabel("月份")
axes.legend(loc=2)
# 获取右边坐标轴
axes_r = axes.twinx()
# 绘制月订单总金额变化折线
axes_r.plot(np.arange(1, 13), group6['sum'], color='y', linestyle='-', label='月订单总金额', alpha=0.8)
# 添加数值标签
for x, y in enumerate(group6['sum']):
plt.text(x+0.5, y+1e6, "%.e"%y, fontsize=12)
# 设置标签刻度
axes_r.set_ylim((-36000000, 36000000))
axes_r.set_ylabel("月订单总金额")
axes_r.legend(loc=1)
# 设置横坐标、标题
plt.title("支付宝月订单数、单笔交易平均金额及月订单总金额变化情况")
plt.xticks(np.arange(1, 13)+0.15, ['一月', '二月', '三月', '四月', '五月', '六月', '七月', '八月', '九月', '十月', '十一月', '十二月'])
plt.show()

从可视化图像 支付宝订单数、单笔交易平均金额及月订单总金额变化情况 可以看到,九月的订单总金额最高,达到了30,000,000,而月订单数最多的月份是在四月份,结合每月单笔交易平均金额分析可知四月订单数虽为最多的,但其单笔订单平均金额却是最少的,单笔花费额度只有不到500,说明四月的消费很可能都是低水平的,或是四月有许多优惠的促销活动,促进了用户消费,但消费额度并不是很高。而九月,虽说订单数并不可观,但其单笔消费平均金额是最高的,该月用户进行了高水平消费,单笔平均消费可达5300以上,可分析九月主要消费内容进而分析九月消费水平如此高的原因,可在之后的九月推出更多相关的产品服务进一步刺激消费提高消费额度。
2)深入分析九月交易情况
- 订单来源分析
# 统计九月数据
df = key_data[key_data['订单创建月份']==9]
group = df.groupby(df['订单来源']).agg({'交易总金额': ['count', 'sum', 'mean']})['交易总金额']
group.sort_values(by='mean', ascending=False)
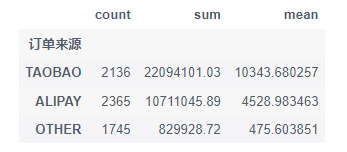
可以看到九月份订单更多来自于ALIPAY,但TAOBAO的订单总金额及单笔平均金额是最高的。
- 订单类型分析
group = df.groupby(df['订单类型']).agg({'交易总金额': ['count', 'sum', 'mean']})['交易总金额']
group.sort_values(by='mean', ascending=False)

可以看到九月份订单类型最多的是交易TRADE类型,交易额在CAE和TRADE类型上有最高交易额,单笔平均金额最高的为CAE_R类型。
- 交易内容分析
group = df.groupby(df['交易商品类别']).agg({'交易总金额': ['count', 'sum', 'mean']})['交易总金额']
group.sort_values(by='mean', ascending=False)

可以看到九月份的高水平消费主要体现在娱乐游戏上,无论是交易总金额还是单笔平均金额都是最高的。
- 综合上述分析,可以知道九月最高交易金额主要依靠于娱乐游戏、借贷款等高金额商品,主要交易来源及订单类型分别为TAOBAO和CAE_R。
3)深入分析4月交易情况
# 获取4月数据
df = key_data[key_data['订单创建月份']==4]
# 关键分析
group = df.groupby(df['订单来源']).agg({'交易总金额': ['count', 'sum', 'mean']})['交易总金额']
print("订单来源分布:")
print(group.sort_values(by='count', ascending=False))
print()
group = df.groupby(df['订单类型']).agg({'交易总金额': ['count', 'sum', 'mean']})['交易总金额']
print("订单类型分布:")
print(group.sort_values(by='count', ascending=False))
print()
group = df.groupby(df['交易商品类别']).agg({'交易总金额': ['count', 'sum', 'mean']})['交易总金额']
print("交易商品类别分布:")
print(group.sort_values(by='count', ascending=False))
print()
group = df.groupby(df['交易类型']).agg({'交易总金额': ['count', 'sum']})['交易总金额']
print("交易类型分布:")
print(group.sort_values(by='count', ascending=False))
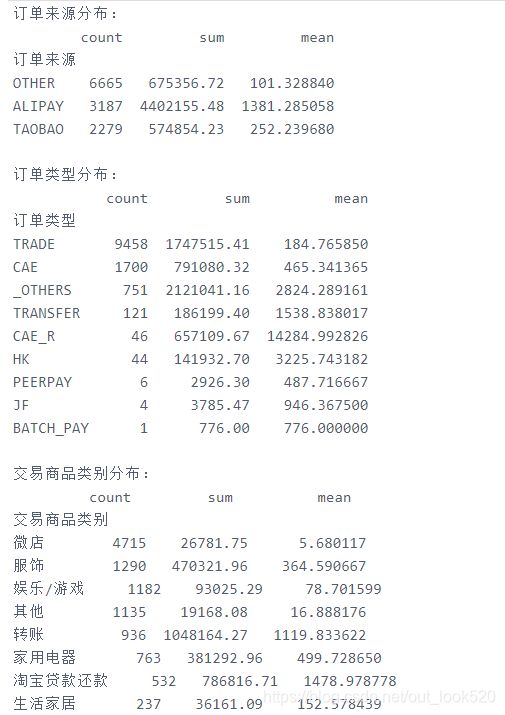
可以看到四月份的订单大多来源于单笔平均金额较低的OTHER,订单类型主要为TRADE,单笔平均金额也是最低的,而单笔金额最高的CAE_R类型订单数并不客观;再看交易商品类别分布可以知道四月主要交易商品为微店、服饰、其他等,交易金额都不是很高,高金额的商品占比并不是很高,交易类型也大多为支出消费。
- 综合上述分析可以知道四月交易数量最多,而交易额最低的原因主要是四月交易类型主要是微店、服饰、其他娱乐游戏等低消费商品,而高消费商品转账、借贷等交易数量较少。
4)每周日订单情况分析
# 获取数据
group7 = key_data.groupby(key_data['订单创建周']).agg({'交易总金额': ['count', 'sum']})['交易总金额']
sort_list = ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday']
group7 = group7.loc[sort_list]
# 绘制统计图
# 设置画布
fig, axes = plt.subplots(1, 1, figsize=(12, 8))
# 绘制日订单数
axes.bar(sort_list, group7['count'], color='red', label='日订单数', width=0.35, alpha=0.6)
# 设置标签刻度
axes.set_ylim((0, 15500))
axes.set_ylabel("日订单数")
axes.set_xlabel("周")
axes.legend(loc=2)
# 获取右边坐标轴
axes_r = axes.twinx()
# 绘制日订单总金额变化折线
axes_r.plot(sort_list, group7['sum'], color='b', linestyle='-', label='日订单总金额', alpha=0.8)
# 添加数值标签
for x, y in enumerate(group7['sum']):
plt.text(x, y+1e6, "%.2e"%y, fontsize=12)
# 设置标签刻度
axes_r.set_ylim((-10000000, 45000000))
axes_r.set_ylabel("日订单总金额")
axes_r.legend(loc=1)
# 设置横坐标、标题
plt.title("支付宝每周日订单数、日订单总金额变化情况")
# plt.xticks(np.arange(1, 13)+0.15, ['一月', '二月', '三月', '四月', '五月', '六月', '七月', '八月', '九月', '十月', '十一月', '十二月'])
plt.show()

可以看到每周的交易情况中,每天的交易订单数基本上差不多,只有在周六交易数量会多一点,也就是说周六的用户会相对更加活跃,可以在周六推出更多活动,以刺激用户消费;在交易金额上周三的交易金额最为突出,达到其他交易金额的三四倍,说明周三交易水平较高,适于推出更多高价值高价格的商品供用户选择。
5)每天不同时刻交易情况分析
# 每日不同时刻交易情况
group8 = key_data.groupby(key_data['订单创建时点']).agg({'交易总金额': 'count'})['交易总金额']
plt.figure(figsize=(12, 8))
plt.plot(np.arange(0, 24), group8, label='交易数', color='b', alpha=0.8)
plt.xlabel("时间")
plt.ylabel("交易数")
xlabel = [str(x)+"点" for x in range(0, 24)]
plt.xticks(np.arange(0, 24), xlabel)
plt.legend(loc=1)
for x, y in enumerate(group8):
plt.text(x-0.4, y+100, "%s"%y)
plt.title("一天内不同时刻交易情况")
plt.show()
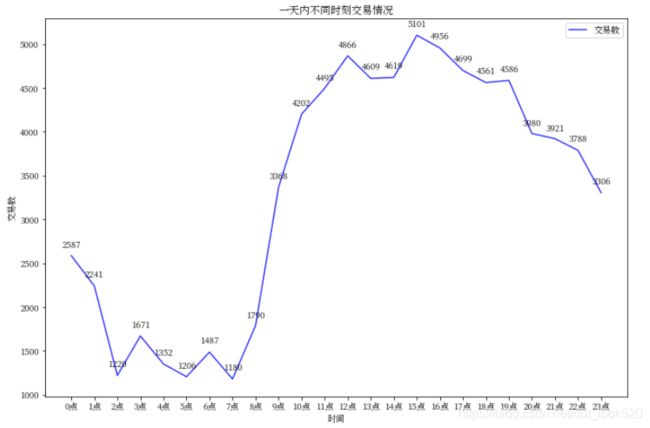
可以看到用户在一天中最活跃的时间主要分布在10:00 ~ 20:00,从早上8:00开始,用户就开始活跃了,到下午15:00用户活跃度达到最高,之后用户活跃度维持在较高水平,但也开始在慢慢下降。
6、交易商品分析
- 交易商品类型交易数占比情况:
# 分析交易商品类型分布
group9 = key_data.groupby(key_data['交易商品类别']).agg({'交易总金额': ['count', 'sum']})['交易总金额']
group = group9.sort_values(by='count', ascending=False)[0:10]
labels = [x for x in group.index]
x=group['count'].values
explode = [0.04, 0.03, 0, 0, 0, 0, 0, 0, 0, 0] # 用于突出显示特定人群
plt.figure(figsize=(12, 8))
plt.pie(x, # 绘图数据
labels=labels, # 添加商品类型标签
explode=explode, # 突出显示特定人群
autopct='%.1f%%', # 设置百分比的格式,这里保留一位小数
pctdistance=0.8, # 设置百分比标签与圆心的距离
labeldistance=1.15, # 设置交易商品类型标签与圆心距离
startangle=180, # 设置饼图的初始角度
wedgeprops={'linewidth':1.5, 'edgecolor':'green'}, # 设置饼图内外边界的属性值
textprops={'fontsize':12, 'color':'k'}, # 设置文字标签的属性值
)
plt.title("交易商品类型交易数占比情况")
plt.show()
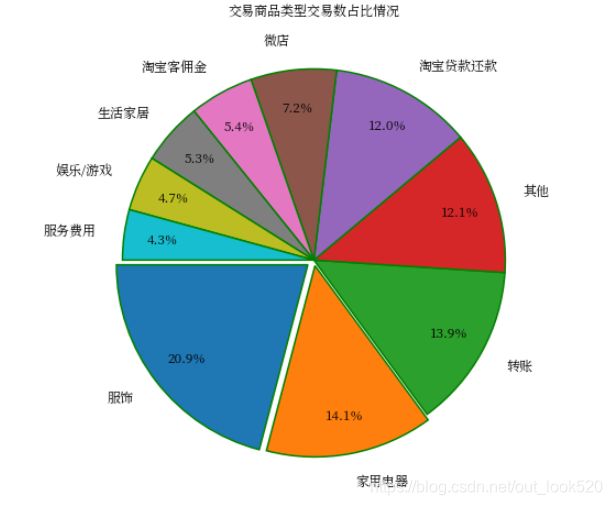
可以看到交易主要商品类型为服饰,占交易数前十类商品的20.9%,之后的家用电器、转账、贷款还款等类型占比差不多,说明支付宝的主要交易商品类型为服饰、家用电器等。
- 交易商品类型交易额占比情况:
group = group9.sort_values(by='sum', ascending=False)[0:10]
labels = [x for x in group.index]
x=group['sum'].values
explode = [0.04, 0.03, 0, 0, 0, 0, 0, 0, 0, 0] # 用于突出显示特定人群
plt.figure(figsize=(12, 8))
plt.pie(x, # 绘图数据
labels=labels, # 添加商品类型标签
explode=explode, # 突出显示特定人群
autopct='%.1f%%', # 设置百分比的格式,这里保留一位小数
pctdistance=0.8, # 设置百分比标签与圆心的距离
labeldistance=1.15, # 设置交易商品类型标签与圆心距离
startangle=180, # 设置饼图的初始角度
wedgeprops={'linewidth':1.5, 'edgecolor':'green'}, # 设置饼图内外边界的属性值
textprops={'fontsize':12, 'color':'k'}, # 设置文字标签的属性值
)
plt.title("交易商品类型交易额占比情况")
plt.show()

支付宝交易额主要来源为商品类型为转账、提现等高消费水平商品,其次贷款、娱乐游戏也占有较高比例
相关建议:
1、可以试着挖掘低占比交易数的商品类型,为该类商品提供更多的交易渠道
2、可以适当增加与高交易额高占比的商品类型的业务交流,扩展其交易客户,增加交易数
3、增加货款借贷业务的渠道和优惠
- 具体交易商品名称词频分析
import jieba
import re
from collections import Counter
from wordcloud import WordCloud
# 停用词获取
stop_words = []
with open(r'/home/mw/work/stop_word.txt',encoding='utf-8',mode='r') as f:
for word in f:
stop_words.append(word.strip())
# 进行分词
with open("商品名称分词.txt", encoding='utf-8', mode='w') as f:
for line in range(key_data.shape[0]):
line = re.sub('[0-9a-zA-Z]', '', str(key_data.loc[line,'交易商品名称'])) # 使用正则表达式对于数字和英文字母进行删除
word = [word for word in jieba.cut(line) if word not in stop_words] # 进行分词
f.write(' '.join(word)+' ')
statistic = Counter()
with open("商品名称分词.txt", encoding='utf-8', mode='r') as f:
a=True
while a:
line = f.read(1024)
words = [word.strip() for word in line.split(' ') if word.strip() != '']
if len(words) <= 5: a=False
tmp = Counter(words)
statistic += tmp
df = pd.DataFrame(statistic.most_common(500))
# 词云绘制,设置字体、背景、大小、颜色
wc = WordCloud(font_path='/home/mw/work/方正粗黑宋简体.ttf', max_words=2000, max_font_size=150,
background_color='white', colormap='Reds_r', scale=15.5)
myText = ' '.join(df.iloc[:, 0])
wc.generate(myText) # 利用文本内容生成词云
plt.imshow(wc)
plt.axis('off')
plt.show()

可以看到支付宝交易商品主要是转账、贷款等,其他一些商品关键词还包括订单、淘宝、捐款等,查看商品名称中包含订单的具体商品后可以知道包含关键词订单的商品大多是一些app上的订单,多为外卖、服务缴费、出行服务等商品,说明支付宝在该系列商品上有很大市场。
四、用户分类
1、用户整体查看
- 查看用户名称信息,了解用户大体分布情况
key_data['用户姓名']

可以看到,用户可以大体分为两大类,一类是公司用户,一类是个人用户。
- 查看各用户的支付宝交易数及交易金额情况
group = key_data.groupby(key_data['用户姓名']).agg({'交易总金额': ['count', 'sum']})['交易总金额']
group.sort_values(by='count', ascending=False)

一年内支付宝最大交易数达到5178,个人用户的交易数更为活跃。
- 消费金额情况
group.sort_values(by='sum', ascending=False)
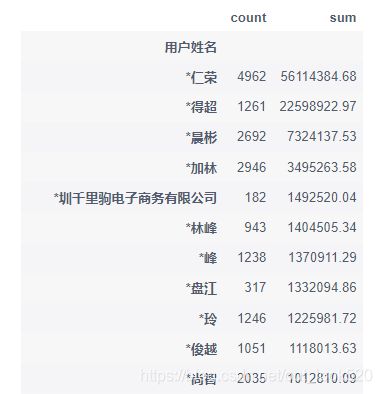
用户交易金额最大达到56114384.68,个人用户的交易金额也都很高,还有一些公司用户的交易水平也很高。
2、将用户分类个人用户和公司用户
公司用户和个人用户的消费目标及消费水平可能不一样,分开分析会有更好的用户定位效果。
company = key_data[key_data['用户姓名'].str.contains('有限公司')==True]
individuals = key_data[key_data['用户姓名'].str.contains('有限公司')==False]
individuals[individuals['用户姓名'].str.len()>=4] # 验证一下个体用户中的用户姓名中是否都是个体姓名
![]()
个体用户分类没有问题,只有一个用户信息为其电话号码,其他均为姓名,该电话号码用户数据只有一条,根据名称来看为活动红包商品,为不影响后续用户分类将该条信息删除后再处理。
# 删除特殊数据
individuals.drop(index=78714, axis=0, inplace=True)
3、分别对个人用户和公司用户进行RFM客户价值分析
支付宝为第三方交易app平台,其主要客户为一些商家或交易app,本数据集主要关于支付宝用户利用支付宝进行交易的行为数据,这里借助RFM模型对用户进行一个分类,得到的分类结果涉及的不同类别的用户主要是交易频次,交易金额、近期使用情况等支付宝交易使用情况,可通过该分类获取到不同类别用户对支付宝交易的粘性、信任度等信息,根据这些信息可针对不同用户设计不同方案,让用户使用支付宝进行交易,放心通过支付宝进行大额交易。
1)处理数据获取用户RFM模型
数据涉及时间为2014.10.14-2015.10.14,将2015年10月15日作为数据采集时间,作为分析客户价值的依据。
- 公司用户数据统计
# 公司用户数据统计
group = company.groupby(by='用户姓名').agg({'交易总金额': ['count', 'sum'], '订单创建时间': 'max'})
# 公司用户交易数不是很高,但其交易金额较高,可对公司用户进行内部的用户分类,针对不同用户制定不同的方案
df1 = group['订单创建时间'].reset_index()
df2 = group['交易总金额'].reset_index()
df_company = pd.merge(df1, df2, on='用户姓名').drop(labels='用户姓名', axis=1)
df_company['max'] = (pd.to_datetime('2015 10 15 00:00:00') - df_company['max']) / np.timedelta64(1, 'D')
df_company.columns = ['R', 'F', 'M']
# 为更好获取用户特征,对于消费频次不大于2,且消费金额不大于1000的用户信息暂不考虑
# df_company = df_company[(df_company['F']>2) & (df_company['M']>1000)]
print("共有", len(df_company), "个公司用户")
df_company.reset_index(drop=True, inplace=True)
df_company

- 个人用户数据统计
# 个人用户数据统计
group = individuals.groupby(by='用户姓名').agg({'交易总金额': ['count', 'sum'], '订单创建时间': 'max'})
print("共有", len(group), "个个人用户")
# 个人用户交易更为频繁,交易金额有高有低,可以用RFM模型进行客户价值的分析
df1 = group['订单创建时间'].reset_index()
df2 = group['交易总金额'].reset_index()
df_individuals = pd.merge(df1, df2, on='用户姓名').drop(labels='用户姓名', axis=1)
df_individuals['max'] = (pd.to_datetime('2015 10 15 00:00:00') - df_individuals['max']) / np.timedelta64(1, 'D')
df_individuals.columns = ['R', 'F', 'M']
df_individuals

2)对两类用户分别进行聚类
- 公司用户数据聚类
from sklearn.cluster import KMeans
# 公司用户进行聚类
# 数据标准化
df_company = (df_company - df_company.mean(axis=0))/(df_company.std(axis=0))
k = 4 # 聚类数
iteration = 500 # 迭代次数
kmodel = KMeans(n_clusters=k, max_iter=iteration)
kmodel.fit(df_company)
# 获取每类聚类类别的数量
r1 = pd.Series(kmodel.labels_).value_counts()
# 获取聚类中心
r2 = pd.DataFrame(kmodel.cluster_centers_)
# 得到各聚类情况
r = pd.concat([r2, r1], axis=1)
r.columns = list(df_company.columns) + [u'聚类数量']
print("聚类分布情况:")
print(r)
# 获取每条数据的聚类类别
r3 = pd.Series(kmodel.labels_, index=df_company.index)
# 合并原数据和对应聚类类别
r = pd.concat([df_company, r3], axis=1)
r.columns = list(df_company.columns) + [u'聚类类别']
print("各数据对于聚类情况:")
print(r)
# 绘制客户类别图表
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei'] # 设置微软雅黑字体
plt.rcParams['axes.unicode_minus'] = False # 避免坐标轴不能正常显示符号
for i in range(k):
if r1[i] == 1:
print("异常数据点:")
print('客户群=%d,聚类数量=%d' %(i, r1[i]))
continue
cls = df_company[r[u'聚类类别']==i]
cls.plot(kind='kde', linewidth=2, subplots=True, sharex=False, figsize=(12, 8))
plt.suptitle('客户群=%d,聚类数量=%d' %(i, r1[i]))
plt.legend()
plt.show()




各类用户特点及建议 :
第0类用户:交易频次高,但交易额少,说明用户经常使用支付宝进行交易,但对支付宝交易的信任度还不够高,极少进行高水平交易,可能是因为服务费也可能是对支付宝安全有所怀疑,可利用问卷调查等手段弄清原因后进行解决。
第1类用户:已不经常使用支付宝进行交易,考虑是否有其他交易平台带走了这部分用户。
第2类用户:最近有过支付宝进行交易,但交易频次和交易金额都不高,该类用户对支付宝交易的信任度还不够高,可能还在尝试使用阶段,可利用免服务费等方法提升用户信任度。
第3类用户:消费频次高、消费金额高,有待提高用户黏性,该类用户只有一条数据,查看数据可知该条数据,F和M都远高于其他数据,R值也只有2.11,该数据为一极值情况,各项数据均很优秀,但由于与其他数据相差太大,所以聚类将其单独分出了。
- 个人用户数据聚类
# 个人用户数据聚类
# 数据标准化
df_individuals = (df_individuals - df_individuals.mean(axis=0))/(df_individuals.std(axis=0))
k = 4 # 聚类数
iteration = 500 # 迭代次数
kmodel = KMeans(n_clusters=k, max_iter=iteration)
kmodel.fit(df_individuals)
# 获取每类聚类类别的数量
r1 = pd.Series(kmodel.labels_).value_counts()
# 获取聚类中心
r2 = pd.DataFrame(kmodel.cluster_centers_)
# 得到各聚类情况
r = pd.concat([r2, r1], axis=1)
r.columns = list(df_individuals.columns) + [u'聚类数量']
print("各聚类分布情况:")
print(r)
# 获取每条数据的聚类类别
r3 = pd.Series(kmodel.labels_, index=df_individuals.index)
# 合并原数据和对应聚类类别
r = pd.concat([df_individuals, r3], axis=1)
r.columns = list(df_individuals.columns) + [u'聚类类别']
print("各数据对于聚类情况:")
print(r)
# 绘制客户类别图表
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei'] # 设置微软雅黑字体
plt.rcParams['axes.unicode_minus'] = False # 避免坐标轴不能正常显示符号
for i in range(k):
if r1[i]==1:
print("异常数据点:")
print('客户群=%d,聚类数量=%d' %(i, r1[i]))
continue
cls = df_individuals[r[u'聚类类别']==i]
cls.plot(kind='kde', linewidth=2, subplots=True, sharex=False, figsize=(12, 8))
plt.suptitle('客户群=%d,聚类数量=%d' %(i, r1[i]))
plt.legend()
plt.show()
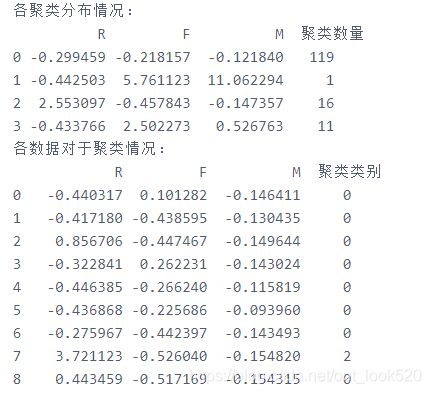


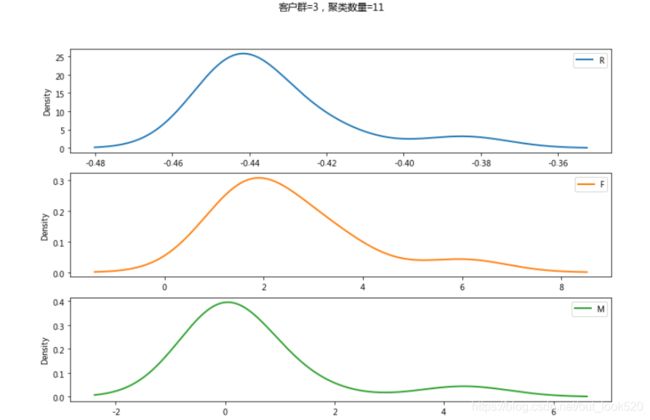
各类用户特点及建议:
第0类用户:已不经常使用支付宝进行交易,考虑是否有其他交易平台带走了这部分用户。
第1类用户:消费频次高、消费金额高,有待提高用户黏性,该类用户只有一条数据,查看数据可知该条数据,F和M都远高于其他数据,R值也只有0.39,该数据为一极值情况,各项数据均很优秀,但由于与其他数据相差太大,所以聚类将其单独分出了。
第2类用户:最近有过支付宝进行交易,但交易频次和交易金额都不高,该类用户对支付宝交易的信任度还不够高,可能还在尝试使用阶段,可利用免服务费等方法提升用户信任度。
第3类用户:交易频次高,但交易额少,说明用户经常使用支付宝进行交易,但对支付宝交易的信任度还不够高,极少进行高水平交易,可能是因为服务费也可能是对支付宝安全有所怀疑,可利用问卷调查等手段弄清原因后进行解决。