Machine Learning HW2
Task:
数据预处理:从原始波形中提取MFCC特征(助教已完成)。
分类任务(Classfication):使用预提取的MFCC特征,进行帧级音素(phoneme)分类。
Dataset & Data Format:
数据集:LibriSpeech (subset of train-clean-100)
数据格式:读取 *.pt 文件为 torch tensors(T, 39)
要求如下:
准确率 |
基准 |
0.45797 |
Simple |
0.69747 |
Medium |
0.75028 |
Strong |
0.82324 |
Boss |
1预处理数据:
一个音素可能覆盖几个帧,依赖于前面和后面的帧,因此,我们连接相邻的音素进行训练以获得更高的准确性。concat_feat函数连接过去和未来的k帧(总共2k+1=n帧),但我们预测中心帧。
# Prepare Data, 以下函数用于concat_feat
def load_feat(path):
feat = torch.load(path)
return feat
def shift(x, n):
if n < 0:
left = x[0].repeat(-n, 1)
right = x[:n]
elif n > 0:
right = x[-1].repeat(n, 1)
left = x[n:]
else:
return x
return torch.cat((left, right), dim=0)
def concat_feat(x, concat_n):
assert concat_n % 2 == 1 # n must be odd
if concat_n < 2:
return x
seq_len, feature_dim = x.size(0), x.size(1)
x = x.repeat(1, concat_n)
x = x.view(seq_len, concat_n, feature_dim).permute(1, 0, 2) # concat_n, seq_len, feature_dim
mid = (concat_n // 2)
for r_idx in range(1, mid + 1):
x[mid + r_idx, :] = shift(x[mid + r_idx], r_idx)
x[mid - r_idx, :] = shift(x[mid - r_idx], -r_idx)
return x.permute(1, 0, 2).view(seq_len, concat_n * feature_dim)
def preprocess_data(split, feat_dir, phone_path, concat_nframes, train_ratio=0.8, train_val_seed=1337):
class_num = 41 # NOTE: pre-computed, should not need change
mode = 'train' if (split == 'train' or split == 'val') else 'test'
label_dict = {}
if mode != 'test':
phone_file = open(os.path.join(phone_path, f'{mode}_labels.txt')).readlines()
for line in phone_file:
line = line.strip('\n').split(' ')
label_dict[line[0]] = [int(p) for p in line[1:]]
if split == 'train' or split == 'val':
# split training and validation data
usage_list = open(os.path.join(phone_path, 'train_split.txt')).readlines()
random.seed(train_val_seed)
random.shuffle(usage_list)
percent = int(len(usage_list) * train_ratio)
usage_list = usage_list[:percent] if split == 'train' else usage_list[percent:]
elif split == 'test':
usage_list = open(os.path.join(phone_path, 'test_split.txt')).readlines()
else:
raise ValueError('Invalid \'split\' argument for dataset: PhoneDataset!')
usage_list = [line.strip('\n') for line in usage_list]
print('[Dataset] - # phone classes: ' + str(class_num) + ', number of utterances for ' + split + ': ' + str(
len(usage_list)))
max_len = 3000000
X = torch.empty(max_len, 39 * concat_nframes)
if mode != 'test':
y = torch.empty(max_len, dtype=torch.long)
idx = 0
for i, fname in tqdm(enumerate(usage_list)):
feat = load_feat(os.path.join(feat_dir, mode, f'{fname}.pt'))
cur_len = len(feat)
feat = concat_feat(feat, concat_nframes)
if mode != 'test':
label = torch.LongTensor(label_dict[fname])
X[idx: idx + cur_len, :] = feat
if mode != 'test':
y[idx: idx + cur_len] = label
idx += cur_len
X = X[:idx, :]
if mode != 'test':
y = y[:idx]
print(f'[INFO] {split} set')
print(X.shape)
if mode != 'test':
print(y.shape)
return X, y
else:
return X2 数据:
Dataset,init负责读数据, getitem 负责在访问数据集时返回数据,len负责返回长度 。
# Define Dataset
class LibriDataset(Dataset):
def __init__(self, X, y= None):
self.data = X
if y is not None:
self.label = torch.LongTensor(y)
else:
self.label = None
def __getitem__(self, idx):
if self.label is not None:
return self.data[idx], self.label[idx]
else:
return self.data[idx]
def __len__(self):
return len(self.data)3 模型:
# Define Model
class BasicBlock(nn.Module):
def __init__(self, input_dim, output_dim):
super(BasicBlock, self).__init__()
self.block = nn.Sequential(
nn.Linear(input_dim, output_dim),
nn.ReLU(),
)
def forward(self, x):
x = self.block(x)
return x
class Classifier(nn.Module):
def __init__(self, input_dim, output_dim=41, hidden_layers=1, hidden_dim=256):
super(Classifier, self).__init__()
self.fc = nn.Sequential(
BasicBlock(input_dim, hidden_dim),
*[BasicBlock(hidden_dim, hidden_dim) for _ in range(hidden_layers)],
nn.Linear(hidden_dim, output_dim)
)
def forward(self, x):
x = self.fc(x)
return x4 超参数设置:为原始sample
# Hyper-parameters
concat_nframes = 1 # the number of frames to concat with, n must be odd (total 2k+1 = n frames)
train_ratio = 0.8 # the ratio of data used for training, the rest will be used for validation
# training parameters
seed = 0 # random seed
batch_size = 512 # batch size
num_epoch = 5 # the number of training epoch
learning_rate = 0.0001 # learning rate
model_path = './models/HW2/model.ckpt' # the path where the checkpoint will be saved
# model parameters
input_dim = 39 * concat_nframes # the input dim of the model, you should not change the value
hidden_layers = 1 # the number of hidden layers
hidden_dim = 256 # the hidden dim5 准备dataset和model
train_X, train_y = preprocess_data(split='train', feat_dir='./libriphone/feat', phone_path='./libriphone', concat_nframes=concat_nframes, train_ratio=train_ratio)
val_X, val_y = preprocess_data(split='val', feat_dir='./libriphone/feat', phone_path='./libriphone', concat_nframes=concat_nframes, train_ratio=train_ratio)
# get dataset
train_set = LibriDataset(train_X, train_y)
val_set = LibriDataset(val_X, val_y)
# remove raw feature to save memory
del train_X, train_y, val_X, val_y
gc.collect()
# get dataloader
train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=True)
val_loader = DataLoader(val_set, batch_size=batch_size, shuffle=False)
def same_seeds(seed):
torch.manual_seed(seed)
if torch.cuda.is_available():
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
np.random.seed(seed)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
# fix random seed
same_seeds(seed)
# create model, define a loss function, and optimizer
model = Classifier(input_dim=input_dim, hidden_layers=hidden_layers, hidden_dim=hidden_dim).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.AdamW(model.parameters(), lr=learning_rate)6训练
best_acc = 0.0
for epoch in range(num_epoch):
train_acc = 0.0
train_loss = 0.0
val_acc = 0.0
val_loss = 0.0
# training
model.train() # set the model to training mode
for i, batch in enumerate(tqdm(train_loader)):
features, labels = batch
features = features.to(device)
labels = labels.to(device)
optimizer.zero_grad()
outputs = model(features)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
_, train_pred = torch.max(outputs, 1) # get the index of the class with the highest probability
train_acc += (train_pred.detach() == labels.detach()).sum().item()
train_loss += loss.item()
# validation
if len(val_set) > 0:
model.eval() # set the model to evaluation mode
with torch.no_grad():
for i, batch in enumerate(tqdm(val_loader)):
features, labels = batch
features = features.to(device)
labels = labels.to(device)
outputs = model(features)
loss = criterion(outputs, labels)
_, val_pred = torch.max(outputs, 1)
val_acc += (val_pred.cpu() == labels.cpu()).sum().item() # get the index of the class with the highest probability
val_loss += loss.item()
print('[{:03d}/{:03d}] Train Acc: {:3.6f} Loss: {:3.6f} | Val Acc: {:3.6f} loss: {:3.6f}'.format(
epoch + 1, num_epoch, train_acc/len(train_set), train_loss/len(train_loader), val_acc/len(val_set), val_loss/len(val_loader)
))
# if the model improves, save a checkpoint at this epoch
if val_acc > best_acc:
best_acc = val_acc
torch.save(model.state_dict(), model_path)
print('saving model with acc {:.3f}'.format(best_acc/len(val_set)))
else:
print('[{:03d}/{:03d}] Train Acc: {:3.6f} Loss: {:3.6f}'.format(
epoch + 1, num_epoch, train_acc/len(train_set), train_loss/len(train_loader)
))
# if not validating, save the last epoch
if len(val_set) == 0:
torch.save(model.state_dict(), model_path)
print('saving model at last epoch')7 测试
# load data
test_X = preprocess_data(split='test', feat_dir='./libriphone/feat', phone_path='./libriphone', concat_nframes=concat_nframes)
test_set = LibriDataset(test_X, None)
test_loader = DataLoader(test_set, batch_size=batch_size, shuffle=False)
# load model
model = Classifier(input_dim=input_dim, hidden_layers=hidden_layers, hidden_dim=hidden_dim).to(device)
model.load_state_dict(torch.load(model_path))
test_acc = 0.0
test_lengths = 0
pred = np.array([], dtype=np.int32)
model.eval()
with torch.no_grad():
for i, batch in enumerate(tqdm(test_loader)):
features = batch
features = features.to(device)
outputs = model(features)
_, test_pred = torch.max(outputs, 1) # get the index of the class with the highest probability
pred = np.concatenate((pred, test_pred.cpu().numpy()), axis=0)
with open('prediction.csv', 'w') as f:
f.write('Id,Class\n')
for i, y in enumerate(pred):
f.write('{},{}\n'.format(i, y))以上为助教提供simple baseline,acc>0.45797

基于助教给的优化提示对这些部分进行优化:
1 将超参concat_nframes增大,训练时接上前后的frame会得到较好的结果,第一次设置为13,注意需要设置为奇数,前后各一半。
# Hyper-parameters
concat_nframes = 13 # the number of frames to concat with, n must be odd (total 2k+1 = n frames)
train_ratio = 0.8 # the ratio of data used for training, the rest will be used for validation2由于初始过于网络架构简单,调整网络架构变宽和变深, 调整hidden-layer和hidden-dim参数。
并在BasicBlock中添加Batch Normalization 和 Dropout模块。
BN通过将每一层网络的输入进行Normalization,保证输入分布的均值与方差固定在一定范围内,减少了网络中的Internal Covariate Shift问题,并在一定程度上缓解了梯度消失,加速了模型收敛;
Dropout模块可以有效避免过拟合;
class BasicBlock(nn.Module):
def __init__(self, input_dim, output_dim):
super(BasicBlock, self).__init__()
self.block = nn.Sequential(
nn.Linear(input_dim, output_dim),
nn.ReLU(),
nn.BatchNorm1d(output_dim, eps=1e-05, momentum=0.1, affine=True),
nn.Dropout(0.35),
)
def forward(self, x):
x = self.block(x)
return x
hidden_layers = 2 # the number of hidden layers
hidden_dim = 1024 # the hidden dim3 增加batch_size和num_epoch:
batch_size = 1024 # batch size
num_epoch = 10第一次优化后,acc提高至0.628;
其中concat n还可以继续增大,优化为n=19,以提高准确率:
# Hyper-parameters
concat_nframes = 19 # the number of frames to concat with, n must be odd (total 2k+1 = n frames)
train_ratio = 0.8 # the ratio of data used for training, the rest will be used for validationOptimizer使用余弦退火学习率:
optimizer = torch.optim.AdamW(model.parameters(), lr=learning_rate,weight_decay=0.01)
scheduler = torch.optim.lr_scheduler.CosineAnnealingWarmRestarts(optimizer,T_0=8,T_mult=2,eta_min = learning_rate/2)使用余弦退火计划设置每个参数组的学习率,余弦退火链接:LINK

其中各个参数的注释如下:
T_0:为我们学习率恢复到初始值的迭代次数(epoch),需要设置;
但学习率恢复到初始值以后,T_0会更新,更新公式为:T_0 = T_0 × T_mult;
T_mult:一个用来更新的参数,默认为1;
eta_min:最小学习率,默认为0;
last_epoch:上一个迭代的索引。默认值:-1;
verbos:如果为True,则为每次更新打印一条消息到stdout。默认值:False;
通过简单的测试代码,可以发现Learning_rates的曲线如图,参考链接: link;
import torch
import torch.nn as nn
from torch.optim.lr_scheduler import CosineAnnealingLR, CosineAnnealingWarmRestarts
import itertools
import matplotlib.pyplot as plt
class Tmodel(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=3, kernel_size=3)
def forward(self, x):
pass
model = Tmodel()
# optimizer = torch.optim.Adam(model.parameters(), lr=0.1)
# scheduler = CosineAnnealingWarmRestarts(optimizer, T_0=5)
learning_rate = 0.0001
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
scheduler = torch.optim.lr_scheduler.CosineAnnealingWarmRestarts(optimizer,T_0=8,T_mult=2,eta_min = learning_rate/2)
print("初始化的学习率:", optimizer.defaults['lr'])
lr_list = [] # 把使用过的lr都保存下来,之后画出它的变化
for epoch in range(1, 31):
# train
optimizer.zero_grad()
optimizer.step()
print("第%d个epoch的学习率:%f" % (epoch, optimizer.param_groups[0]['lr']))
lr_list.append(optimizer.param_groups[0]['lr'])
scheduler.step()
# 画出lr的变化
plt.plot(list(range(1, 31)), lr_list)
plt.xlabel("epoch")
plt.ylabel("lr")
plt.title("learning rate's curve changes as epoch goes on!")
plt.show()
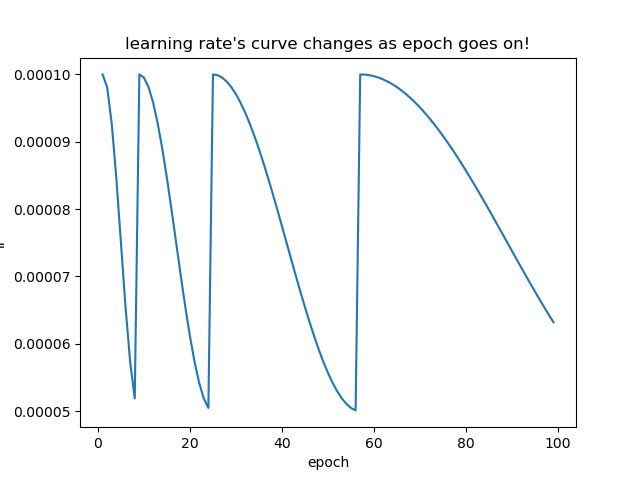
余弦函数中随着x的增加余弦值首先缓慢下降,然后加速下降,再次缓慢下降。这种下降模式能和学习率配合,以一种十分有效的计算方式来产生很好的效果。当执行完Ti个epoch之后就会开始热重启,而下标i就是指的第几次Restart,其中重启是通过重置学习率来模拟。
根据以上优化,acc提高至0.73;