第十八章 Spark数据倾斜调优整理(图解+生产实战)
- Spark数据倾斜调优图解

- 数据倾斜后果:
- ①Spark任务OOM异常退出;
- ②拖慢整个任何的执行
1、MR执行流程 VS Spark执行流程
1.1、MR执行流程
- 核心思想:大问题拆分成多个小问题,然后分布式的并行执行,每个MR程序分成两个阶段

1.2、Spark执行流程
- 核心思想:大问题拆分成多个小问题,然后分布式的并行执行,每个Spark程序链式调用的时候根据业务情况分成N个阶段

2、数据倾斜是什么
- 数据倾斜:并行处理的数据集中,某一部分(如Spark 或 Kafka 的一个 Partition)的数据显著多于其它部分,从而使得该部分的处理速度成为整个数据集处理的瓶颈。
2.1、数据倾斜发生现象
(1)大部分情况:大部分任务都很快执行完,用时也相差无几,但个别Task执行耗时很长,整个应用程序一直处于99%左右 的状态。

(2)小部分情况:Driver或者Excecor发生OOM。
①Driver发生OOM:
java.lang.OutOfMemoryError: Not enough memory to build and broadcast
②Executor发生OOM:
java.lang.OutOfMemoryError: Java heap space at java.util.Arrays.copyOf
java.lang.OutOfMemoryError: Java heap space at java.lang.reflect.Array.newInstance
2.2、数据倾斜发生原理
-
倾斜原理:按照 key 进行聚合或 join 等操作。此时如果某个 key 对应的数据量特别大导致在shuffle后的task分配过多的数据。
-
业务范例:hello world的数据统计
hello 这个 key,在三个节点上对应了总共 7 条数据,这些数据都会被拉 取到同一个task中进行处理;而world 和 you 这两个 key 分别才对应 1 条数据,所以另外两个 task 只 要分别处理 1 条数据即可。此时第一个 task 的运行时间可能是另外两个 task 的 7 倍,而整个 stage 的 运行速度也由运行最慢的那个 task 所决定。
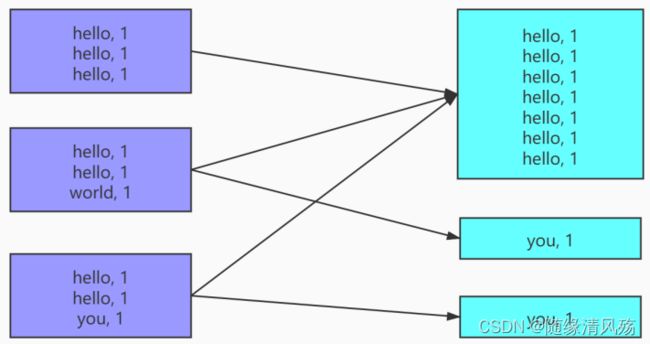
总结:数据倾斜发生的本质,就是在执行多阶段的计算的时候,中间的shuffle策略可能导致分发到下 游Task的数据量不均匀,进而导致下游Task执行时长的不一致。不完全均匀是正常的,但是如果相差 太大,那么就产生性能问题了。
2.3、数据倾斜危害
1、整体耗时过大(整个任务的完成由执行时间最长的那个Task决定)
2、应用程序可能异常退出(某个Task执行时处理的数据量远远大于正常节点,则需要的资源容易出现瓶颈, 当资源不足,则应用程序OOM退出)
3、资源闲置(处理等待状态的Task资源得不到及时的释放,处于闲置浪费状态)
3、数据倾斜调优思路
- 最终目的:Spark 中的同一个 stage 中的多个 Task 处理的数据量大小几乎是一致的。
- 调优思路
- 数据源优化
- 数据分发shuffl优化
3.1、避免数据源倾斜 - HDFS
- 含义:对于不可切分文件可能出现数据倾斜,对于可切分文件,一般来说,不存在数据倾斜问题。
(1)可切分文件: 基本上不会! 默认数据块大小:128M
(2)不可切分文件: 源文件不均匀,最终导致分布式引用程序计算产生数据倾斜
- 日志:每一个小时生成一个日志文件
3.2、避免数据倾斜 - Kafka
- 分发策略:使用随机/轮询策略,不要使用范围/哈希策略
(1)Kafka不是计算引擎,只是一个用来在流式项目架构中起削峰填谷作用的消息中转平台,所以为保证一个 Topic的分布式平衡,尽量不要使用Hash散列或者是跟业务有关的自定义分区规则等方式来进行数据分区,否 则会造成下游消费者一开始就产生了数据倾斜。 (2)Kafka尽量使用随机,轮询等不会造成数据倾斜的数据分区规则
3.3、定位倾斜Task
- 根本原因:数据倾斜产生的原因,就是两个 stage 中的 shuffle 过程导致的,定位导致Shuffle 算子即可。
- 注意事项:spark的执行,按照suffle算子分成多个stage来执行。
如果 Spark Application 运行过程中,出现数据倾斜,可以通过 web 管理监控界面,查看 各stage 的运行情况,如果某一个 stage 的运行很长,并且这个 stage 的大部分Task都运行很快,则可快速定位相关算子。
- shuffle算子:distinct、groupByKey、reduceByKey、aggergateByKey、join、cogroup、repartition
3.4、定位倾斜key
-
解决方案:采样
-
离线处理:无回放采样
-
流式处理:鱼塘采样
-
(1)无回放采样
①Spark SQL:使用SQL查询,同Hive的放回采样
- 第一步:模糊采样
#采样方式:通过随机数的方式将数据打散分布,之后取前100条
select * from table sort by rand() - 0.5 limit 100;
- 第二步:将采样后的数据进行排序,之后切分10个分区来做
- 第一个分区取最后一条数据,其余分区同理
②5Spark RDD:可以在Spark作业中加入查看 key 分布 的代码,比如 RDD.countByKey(),然后对统计出来的各个key出现的次数,collect/take到客户端打印 一下,就可以看到key的分布情况。
(2)鱼塘采样 - 流式处理,本文不细讲
4、数据倾斜优化方案
- 重点:在 Spark 中,同一个 Stage 的不同 Partition 可以并行处理,而具有依赖关系的不同 Stage 之间是串行处理的。
由于同一个 Stage 内的所有 Task 执行相同的计算,在排除不同计算节点计算能力差异的前提下,不同 Task 之间耗时的差异主要由该 Task 所处理的数据量决定。
4.1、Hive ETL预处理数据
(1)业务场景
数据源Hive表本身分布不均匀导致大量Spark作业数据倾斜
(2)实现思路
通过Hive来进行数据预处理(即通过 Hive ETL 预先对数据按照 key 进行 聚合,或者是预先和其他表进行join),然后在 Spark 作业中针对的数据源就不是原来的 Hive 表了, 而是预处理后的Hive表。此时由于数据已经预先进行过聚合或join操作了,那么在 Spark 作业中也就不 需要使用原先的 shuffle 类算子执行这类操作了。

- 实现原理:将数据倾斜的发生时机提前,减少数据倾斜次数。
(3)优缺点
- 优点:实现起来简单便捷,效果还非常好,完全规避掉了数据倾斜,Spark作业的性能会大幅度提升。
- 缺点:治标不治本,Hive ETL中还是会发生数据倾斜。
4.2、调整shuffle操作的并行度
(1)业务场景
大量不同的Key被分配到了相同的Task造成该Task数据量过大。
- 注意事项:默认分区规则为Hash散列,有可能不同key会分到相同partition,分配到同一个Task。
(2)实现思路
- SparkSQL:增大spark.sql.shuffle.partitions数量,其值默认200
- SparkRDD:给Shuffle算子传入参数,比如reduceByKey(1000),该参数就设置了这个 shuffle 算子执行时shuffle read task 的数量。

- 实现原理:调整并行度分散同一个 Task的不同 Key,之前由于运气比较差,多个数据比较多的 key 都分布式在同一个 Task 上,如果调整了并行度,极大可能会让这些 key 分布式到不同的 Task,有效缓 解数据倾斜。
(3)优缺点
-
优点:实现起来比较简单,可以有效缓解和减轻数据倾斜的影响。
-
缺点**:适用场景少,只能将分配到 同一Task的不同Key分散开,但对于同一Key倾斜严重的情况该方法并不适用。**
4.3、过滤少数导致倾斜的Key
(1)使用场景
发现导致倾斜的 key 就少数几个,而且对业务没影响。
(2)实现思路
将导致数据倾斜的 key 给过滤掉之后,这些 key 就不会参与计算了,自然不可能产生数据倾斜。
(3)企业实践
有一次发现某一天 Spark 作业在运行的时候突然 OOM 了,追查之后发现,是 Hive 表中的某一个 key 在那天数据异常,导致数据量暴增。因此就采取每次执 行前先进行采样,计算出样本中数据量最大的几个 key 之后,直接在程序中将那些key给过滤掉。
4.4、两阶段聚合 - 倾斜Key聚合需求
(1)业务场景
对RDD执行reduceByKey等聚合类shuffle算子或者在Spark SQL中使用group by语句进行分组聚合时, 比较适用这种方案。
(2)实现思路
- 核心实现思路:进行两阶段聚合。
第一次是局部聚合,先给每个key都打上一个随机数, 比如10以内的随机数,此时原先一样的key就变成不一样的了,比如(hello, 1) (hello, 1) (hello, 1) (hello, 1),就会变成(1_hello, 1) (1_hello, 1) (2_hello, 1) (2_hello, 1)。
第二次是打上随机数后的数据,执行 reduceByKey等聚合操作,进行局部聚合,那么局部聚合结果,就会变成了(1_hello, 2) (2_hello, 2)。然 后将各个key的前缀给去掉,就会变成(hello,2)(hello,2),再次进行全局聚合操作,就可以得到最终结果 了,比如(hello, 4)。

- 实现原理:
- ①将原本相同的key通过附加随机前缀的方式,变成多个不同的key,就可以让原本被一个task处理的数据 分散到多个task上去做局部聚合,进而解决单个task处理数据量过多的问题。
- ②接着去除掉随机前缀,再次进行全局聚合,就可以得到最终的结果。
(3)优缺点
- 优点:对于聚合类的shuffle操作导致的数据倾斜,效果是非常不错的。
- 缺点:仅仅适用于聚合类的shuffle操作,适用范围相对较窄。如果是join类的shuffle操作,还得用其他的解决 方案。
4.5、横向拆分 - 少量倾斜Key关联需求
(1)业务场景
如果出现数据倾斜,是因为其中某一个 RDD/Hive 表中的少数几个 key 的数据量过大,而另一个 RDD/Hive 表中的所有 key 都分布比较均匀,而且两个表需要做Join。
(2)实现思路
①对包含少数几个数据量过大的key的那个RDD,通过sample算子采样出一份样本来,然后统计一下每个 key的数量,计算出来数据量最大的是哪几个key。
②然后将这几个key对应的数据从原来的RDD中拆分出来,形成一个单独的RDD,并给每个key都打上n以内的 随机数作为前缀,而不会导致倾斜的大部分key形成另外一个RDD。
③接着将需要join的另一个RDD,也过滤出来那几个倾斜key对应的数据并形成一个单独的RDD,将每条数据 膨胀成n条数据,这n条数据都按顺序附加一个0~n的前缀,不会导致倾斜的大部分key也形成另外一个RDD。
④再**将附加了随机前缀的独立RDD与另一个膨胀n倍的独立RDD进行join,**此时就可以将原先相同的key打散 成n份,分散到多个task中去进行join了。
⑤而另外两个普通的RDD就照常join即可。
⑥最后将两次join的结果使用union算子合并起来即可,就是最终的join结果。
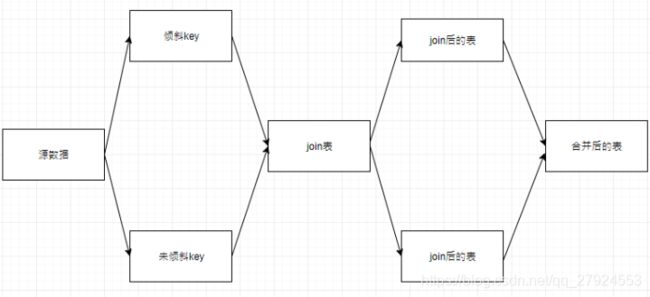
- 实现原理:可以将少数几个 key 分拆成独立 RDD, 并附加随机前缀打散成 n 份去进行join,此时这几个 key 对应的数据就不会集中在少数几个 task 上, 而是分散到多个 task 进行 join 了。
- SQL伪代码
select ...... from a group by a.age where a.age = 18 or a.age = 19
union
select ...... from a group by a.age where a.age != 18 or a.age != 19
- RDD伪代码实现
rdd.filter("a.age = 18 or a.age = 19 ")
rdd.filter("a.age != 18 or a.age != 19 ")
(3)优缺点
- 优点:对于join导致的数据倾斜,如果只是某几个key导致了倾斜,采用该方式可以用最有效的方式打散key进行 join,而且只需要针对少数倾斜key对应的数据进行扩容n倍,不需要对全量数据进行扩容。避免了占用过多 内存。
- 缺点:如果导致倾斜的key特别多的话,比如成千上万个key都导致数据倾斜,那么这种方式也不适合。
4.6、随机前缀+扩容RDD - 大量倾斜Key关联操作
(1)业务场景
而这一种方案是针对有大量倾斜key的情况,没法将部分key拆分出来进行单独处理,因此只能对整个RDD进行数据扩容,对内存资源要求很高。
(2)实现思路
①首先查看 RDD/Hive 表中的数据分布情况,找到那个造成 数据倾斜的 RDD/Hive 表,比如有多个key 都对应了超过1万条数据。
②然后将该RDD的每条数据都打上一个n以内的随机前缀。
③同时对另外一个正常的RDD进行扩容,将每条数据都扩容成n条数据,扩容出来的每条数据都依次打上一个 0~n的前缀。
④最后将两个处理后的RDD进行join即可。

-
实现原理:将原先一样的 key 通过附加随机前缀变成不一样的key,然后就可以将这些处理后的“不同key”分散到多 个task中去处理,而不是让一个task处理大量的相同key。
-
SQL伪代码
#无条件join,笛卡尔积
select a.*,b.* from a,b where 1 = 1
(3)优缺点
- 优点:对join类型的数据倾斜基本都可以处理,而且效果也相对比较显著,性能提升效果非常不错。
- 缺点:该方案更多的是缓解数据倾斜,而不是彻底避免数据倾斜。而且需要对整个RDD进行扩容,对内存资源要求很高。
4.7、map join - 表关联需求(大表Join小表)
(1)业务需求
在对 RDD 使用 join 类操作,或者是在 Spark SQL 中使用 join 语句时,而且 join 操作中的一个 RDD 或 表的数据量比较小(比如几百M或者一两G)。
(2)实现思路
使用MapJoin
①MapReduce任务:在 Mapper 阶段就完成Join操作;
②Spark任务:只用一个 Stage 就执行完了 Join 操作;
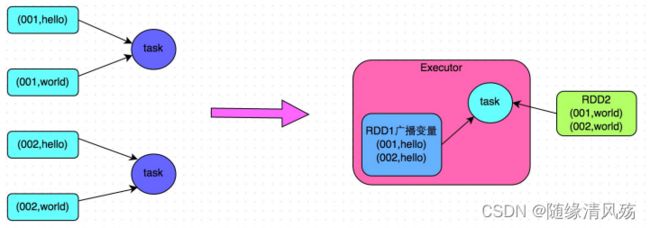
-
实现原理:采用广播小 RDD 全量数据 +map 算子来实现与 join 同样的效果,也就是 map join,此时就不会发生 shuffle 操 作,也就不会发生数据倾斜。
-
SQL伪代码:b是一张小表
select /*+ mapjoin(t)*/ f.a,f.b from A f join B t on f.a=t.a
- RDD伪代码
rdd.mapPartition().withBroadCast(smallTable_rdd)
(3)优缺点
- 优点:对join操作导致的数据倾斜,效果非常好,因为根本就不会发生shuffle,也就根本不会发生数据倾斜。
- 缺点:适用场景较少,因为这个方案只适用于一个大表和一个小表的情况。
- 原因:将小表进行广播,此时会比 较消耗内存资源,driver 和每个Executor 内存中都会驻留一份小 RDD 的全量数据。
4.8、位图法 - 表关联需求(大表关联大表)
(1)业务场景
两张大表进行数据关联,实际业务场景中的用户留存,新老用户等等等业务需求。
(2)实现思路
①把其中一个较小的表拆分成多个小表,执行多次大小表链接
②SortMergeJoin
③位图法

- 实现原理: 维护一个位数组 - 10E个位 每个位 要么是1 要么 0
(3)优缺点
- 优点:占用内存少,处理速度高;
- 缺点:维护BitMap要求高;
5、Spark内存管理
- 进程管理:Spark集群会启动
Dirver和Excecutor两种JVM进程Driver:负责创建SparkContext上下文,提交任务,task的分发等;Executor:负责task的计算任务,并将结果返回给Driver
- 统一内存管理和静态内存管理的区别:在于存储内存和执行内存共享一块空间,可以互相借用对方空间。
5.1、静态内存管理分布图
- 含义:存储内存、执行内存和其他内存的大小在
Spark应用程序运行期间均是固定的,单是用户可以在应用系统启动前进行配置。

(1)缓存数据内存:Executor内存占比60%
-
数据存储:
60%*90%-
存储RDD的缓存数据和广播变量:
90%*80% -
解压序列化数据:
90%*20%
-
-
预留空间防止OOM:
60%*10%
(2)shuffle内存:Executor内存占比20%
shuffle聚合内存:20%*80%shuffle预留内存:20%*20%
(3)task计算内存:Executor内存占比20%,由上面两部分参数决定后剩余的就是ttask计算内存。
5.2、统一管理内存分布图

(1)计算+预留空间:占比Executor内存的40%
- 预留内存:300M,防止OOM;
- 计算内存:其余用于用于task计算;
(2)存储+shuffle聚合内存:占比Excecutor内存的60%,两者可以互相动态借用。
- 存储内存:存储RDD缓存数据和广播变量,占比
Executor内存的60%*50%; - shuffle内存:用于shuffle聚合,占卜
Executor内存的60%*50%;
5.3、reduce拉取数据OOM问题
(1)OOM出现场景
- 含义:Reduce拉去map端数据首批拉取不进来才会OOM。
- 正常数据流程:
- Reduce内存40M:第一次拉取数据60M,批次数据内存中装载不下,导致OOM;
- Reduce内存60M:第一次拉取数据40M,**第二次也拉取40M,首批拉取的数据会进行磁盘溢写之后才会装在第二批的数据,**不会发生OOM。
(2)OOM解决方案
①减少每批次拉取的数据量;
②提高shuffle聚合的内存比例;
#提交任务时进行配置
spark-submit --conf spark.shuffle.memoryFraction=0.2
③提高Executor的总内存;