python识别图片表格内容
python-opencv表格识别
文章目录
- python-opencv表格识别
- 前言
- 一、环境准备
- 二、tesseract-OCR搭建
-
- 1.tesseract-OCR
- 2.debug tesseract
- 三、源码
-
- 1.源码
- 2.运行结果
- 总结
前言
提示:以下是本篇文章正文内容,python环境的搭建这里暂不做介绍,不会的同学可以参考一下其它文章。
提示:以下是本篇文章正文内容,下面案例可供参考
一、环境准备
1、python环境搭建;
2、tesseract安装(pytesseract);
3、python必要的一些库(os、cv2、numpy等);
4、源码调试
二、tesseract-OCR搭建
1.tesseract-OCR
可参考文章https://blog.csdn.net/qq_43317529/article/details/83340739
下载链接:https://digi.bib.uni-mannheim.de/tesseract/
1、下载选择对应的版本;
2、选择安装路径进行安装;
3、若需要下载识别其他语言的字符,可到官网下载对应语言包,下载完成后放到Tesseract-OCR\tessdata\tessconfigs下即可;
4、设置环境变量,进入环境变量中;
5、tesseract -v 检查是否安装成功;
2.debug tesseract
运行源码时发现:pytesseract.pytesseract.TesseractNotFoundError: E:/Tesseract-OCR/tesseract.exe is not installed or it’s not in your PATH. See README file for more information.
PS E:\py\python3.7\test\test22> python .\ocr2.py
mylisty [4, 41, 78, 115, 152, 189, 226, 263, 300, 337, 374, 411]
mylistx [0, 53, 218, 307, 374, 441, 508, 568, 670, 769, 901]
Traceback (most recent call last):
File "E:\py\python3.7\Python37\lib\site-packages\pytesseract\pytesseract.py", line 252, in run_tesseract
proc = subprocess.Popen(cmd_args, **subprocess_args())
File "E:\py\python3.7\Python37\lib\subprocess.py", line 756, in __init__
restore_signals, start_new_session)
File "E:\py\python3.7\Python37\lib\subprocess.py", line 1155, in _execute_child
startupinfo)
FileNotFoundError: [WinError 2] 系统找不到指定的文件。
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File ".\ocr2.py", line 82, in <module>
text1 = pytesseract.image_to_string(ROI) #读取文字,此为默认英文
File "E:\py\python3.7\Python37\lib\site-packages\pytesseract\pytesseract.py", line 417, in image_to_string
}[output_type]()
File "E:\py\python3.7\Python37\lib\site-packages\pytesseract\pytesseract.py", line 416, in <lambda>
Output.STRING: lambda: run_and_get_output(*args),
File "E:\py\python3.7\Python37\lib\site-packages\pytesseract\pytesseract.py", line 284, in run_and_get_output
run_tesseract(**kwargs)
File "E:\py\python3.7\Python37\lib\site-packages\pytesseract\pytesseract.py", line 256, in run_tesseract
raise TesseractNotFoundError()
pytesseract.pytesseract.TesseractNotFoundError: E:/Tesseract-OCR/tesseract.exe is not installed or it's not in your PATH. See README file for more information.
解决方式:
1、通过cmd输入pip install pytesseract进行安装,但是安装后并不能直接使用;
2、在Tesseract-OCR的目录下运行pip install pytesseract可以看到自己安装的pytesseract所在路径;
PS E:\py\OCR\Tesseract-OCR> pip install pytesseract
Requirement already satisfied: pytesseract in e:\py\python3.7\python37\lib\site-packages (0.3.8)
Requirement already satisfied: Pillow in e:\py\python3.7\python37\lib\site-packages (from pytesseract) (8.2.0)
3、根据路径找到pytesseract.py;
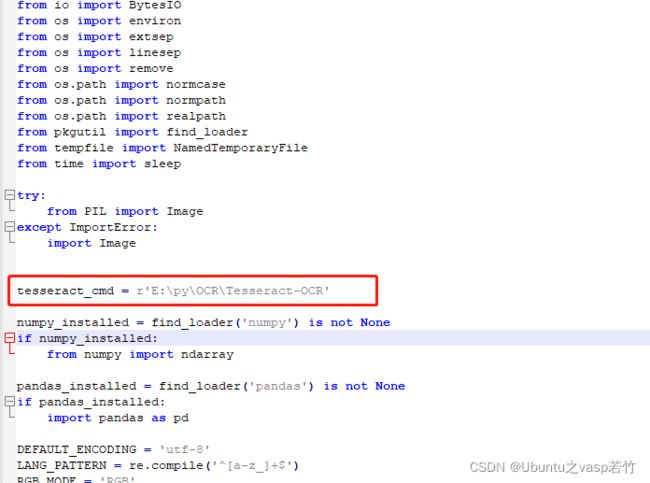
4、点开编辑,找到tesseract_cmd将它改为你刚刚安装的tesseract的路径。
5、添加环境变量,在Tesseract-OCR路径下,再添加一个tessdata;
path=E:\py\OCR\Tesseract-OCR
path=E:\py\OCR\Tesseract-OCR\tessdata
6、在源码中修改路径为Tesseract-OCR的路径即可;
三、源码
1.源码
代码如下(示例):
# -*- coding: utf-8 -*-
"""
Created on Tue May 28 19:23:19 2019
将图片按照表格框线交叉点分割成子图片(传入图片路径)
@author: hx
"""
import cv2
#import cv2 as cv
import numpy as np
import pytesseract
#image = cv2.imread('C:/Users/Administrator/Desktop/7.jpg', 1)
image = cv2.imread(r'E:\py\python3.7\test\test22\src1.jpg', 1)
#灰度图片
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
#二值化
binary = cv2.adaptiveThreshold(~gray, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 35, -5)
#ret,binary = cv2.threshold(~gray, 127, 255, cv2.THRESH_BINARY)
cv2.imshow("二值化图片:", binary) #展示图片
cv2.waitKey(0)
rows,cols=binary.shape
scale = 40
#识别横线
kernel = cv2.getStructuringElement(cv2.MORPH_RECT,(cols//scale,1))
eroded = cv2.erode(binary,kernel,iterations = 1)
#cv2.imshow("Eroded Image",eroded)
dilatedcol = cv2.dilate(eroded,kernel,iterations = 1)
cv2.imshow("表格横线展示:",dilatedcol)
cv2.waitKey(0)
#识别竖线
scale = 20
kernel = cv2.getStructuringElement(cv2.MORPH_RECT,(1,rows//scale))
eroded = cv2.erode(binary,kernel,iterations = 1)
dilatedrow = cv2.dilate(eroded,kernel,iterations = 1)
cv2.imshow("表格竖线展示:",dilatedrow)
cv2.waitKey(0)
#标识交点
bitwiseAnd = cv2.bitwise_and(dilatedcol,dilatedrow)
cv2.imshow("表格交点展示:",bitwiseAnd)
cv2.waitKey(0)
# cv2.imwrite("my.png",bitwiseAnd) #将二值像素点生成图片保存
#标识表格
merge = cv2.add(dilatedcol,dilatedrow)
cv2.imshow("表格整体展示:",merge)
cv2.waitKey(0)
#两张图片进行减法运算,去掉表格框线
merge2 = cv2.subtract(binary,merge)
cv2.imshow("图片去掉表格框线展示:",merge2)
cv2.waitKey(0)
#识别黑白图中的白色交叉点,将横纵坐标取出
ys,xs = np.where(bitwiseAnd>0)
mylisty=[] #纵坐标
mylistx=[] #横坐标
#通过排序,获取跳变的x和y的值,说明是交点,否则交点会有好多像素值值相近,我只取相近值的最后一点
#这个10的跳变不是固定的,根据不同的图片会有微调,基本上为单元格表格的高度(y坐标跳变)和长度(x坐标跳变)
i = 0
myxs=np.sort(xs)
for i in range(len(myxs)-1):
if(myxs[i+1]-myxs[i]>10):
mylistx.append(myxs[i])
i=i+1
mylistx.append(myxs[i]) #要将最后一个点加入
i = 0
myys=np.sort(ys)
#print(np.sort(ys))
for i in range(len(myys)-1):
if(myys[i+1]-myys[i]>10):
mylisty.append(myys[i])
i=i+1
mylisty.append(myys[i]) #要将最后一个点加入
print('mylisty',mylisty)
print('mylistx',mylistx)
#循环y坐标,x坐标分割表格
for i in range(len(mylisty)-1):
for j in range(len(mylistx)-1):
#在分割时,第一个参数为y坐标,第二个参数为x坐标
ROI = image[mylisty[i]+3:mylisty[i+1]-3,mylistx[j]:mylistx[j+1]-3] #减去3的原因是由于我缩小ROI范围
cv2.imshow("分割后子图片展示:",ROI)
cv2.waitKey(0)
#special_char_list = '`~!@#$%^&*()-_=+[]{}|\\;:‘',。《》/?ˇ'
#pytesseract.pytesseract.tesseract_cmd = r'E:/Tesseract-OCR/tesseract.exe'
pytesseract.pytesseract.tesseract_cmd = r'E:\py\OCR\Tesseract-OCR\tesseract.exe'
#pytesseract.pytesseract.tesseract_cmd = r'E:\py\python3.7\Python37\Scripts\py\pytesseract.exe'
text1 = pytesseract.image_to_string(ROI) #读取文字,此为默认英文
#text2 = ''.join([char for char in text2 if char not in special_char_list])
print('识别分割子图片信息为:'+text1)
j=j+1
i=i+1
2.运行结果





总结
提示:此源码仅供测试学习,功能尚不完善,持续更新中。