【综述】NLP 对抗训练(FGM、PGD、FreeAT、YOPO、FreeLB、SMART)
在对抗训练中关键的是需要找到对抗样本,通常是对原始的输入添加一定的扰动来构造,然后放给模型训练,这样模型就有了识别对抗样本的能力。其中的关键技术在于如果构造扰动,使得模型在不同的攻击样本中均能够具备较强的识别性
对抗训练,简单来说,就是在原始输入样本 x x x 上加上一个扰动 r a d v r_{adv} radv(在下文中有时记为 δ \delta δ),得到对抗样本后,用其进行训练。2018 年 Madry 针对对抗学习定义了一个 Min-Max 的公式1,即
m i n θ E ( x , y ) ∼ D [ m a x r a d v ∈ S L ( θ , x + r a d v , y ) ] \underset{\theta}{min}\mathbb E_{(x,y)\sim \mathcal D}[\underset{r_{adv\in S}}{max}\ L(\theta,x+r_{adv},y)] θminE(x,y)∼D[radv∈Smax L(θ,x+radv,y)]
该公式有两部分:
- 内部损失函数的最大化,对抗的思想即是往增大损失的方向增加扰动, S S S 定义为扰动空间,此时我们的目的就是求得让判断失误最多的扰动量,即最佳的攻击参数
- 外部风险的最小化,我们希望的是给输入加上扰动后,输出分布还能够和原分布相同,此时我们的目的就是在针对上述攻击的情况下找到最鲁邦的模型参数
下面将分别介绍 NLP 中用到的一些常用对抗训练算法:基本单步算法 FGM,一阶扰动最强多步算法 PGD, FreeAT、YOPO、FreeLB 和 SMART
请读者注意,对于不同的算法论文中可能采用了不同的数学符号,请注意区别
Fast Gradient Method(FGM)
Goodfellow 在 2015 年提出了 Fast Gradient Sign Method(FGSM)2,假设对于输入的梯度为
g = ▽ x L ( θ , x , y ) g=\triangledown_xL(\theta, x, y) g=▽xL(θ,x,y)
那么扰动就可以向着损失上升的方向再进一步
r a d v = ϵ ⋅ s g n ( ▽ x L ( θ , x , y ) ) r_{adv}=\epsilon\cdot sgn(\triangledown_xL(\theta, x, y)) radv=ϵ⋅sgn(▽xL(θ,x,y))
Goodfellow 发现,令 ϵ = 0.25 \epsilon=0.25 ϵ=0.25 ,这个扰动能给一个单层分类器造成 99.9% 的错误率。随后,在 2017 年 Goodfellow 对 FGSM 中计算扰动的部分做了一点简单的修改3,取消了符号函数,用梯度的第二范式做了一个 scale
r a d v = ϵ ⋅ g / ∣ ∣ g ∣ ∣ 2 x a d v = x + r a d v r_{adv}=\epsilon\cdot g\ /\ ||g||_2\\ x_{adv}=x+r_{adv} radv=ϵ⋅g / ∣∣g∣∣2xadv=x+radv
"""
对于每个x:
1.计算x的前向loss、反向传播得到梯度
2.根据embedding矩阵的梯度计算出r,并加到当前embedding上,相当于x+r
3.计算x+r的前向loss,反向传播得到对抗的梯度,累加到第一步的梯度上
4.将embedding恢复为第一步时的值
5.根据第三步的梯度对参数进行更新
"""
import torch
class FGM():
def __init__(self, model):
self.model = model
self.backup = {}
def attack(self, epsilon=1., emb_name='emb.'):
# emb_name这个参数要换成你模型中embedding的参数名
for name, param in self.model.named_parameters():
if param.requires_grad and emb_name in name:
self.backup[name] = param.data.clone()
norm = torch.norm(param.grad)
if norm != 0 and not torch.isnan(norm):
r_at = epsilon * param.grad / norm
param.data.add_(r_at)
def restore(self, emb_name='emb.'):
# emb_name这个参数要换成你模型中embedding的参数名
for name, param in self.model.named_parameters():
if param.requires_grad and emb_name in name:
assert name in self.backup
param.data = self.backup[name]
self.backup = {}
# 需要使用对抗训练的时候,只需要添加五行代码
# 初始化
fgm = FGM(model)
for batch_input, batch_label in data:
# 正常训练
loss = model(batch_input, batch_label)
loss.backward() # 反向传播,得到正常的grad
# 对抗训练
fgm.attack() # 在embedding上添加对抗扰动
loss_adv = model(batch_input, batch_label)
loss_adv.backward() # 反向传播,并在正常的grad基础上,累加对抗训练的梯度
fgm.restore() # 恢复embedding参数
# 梯度下降,更新参数
optimizer.step()
model.zero_grad()
Project Gradient Descent(PDG)
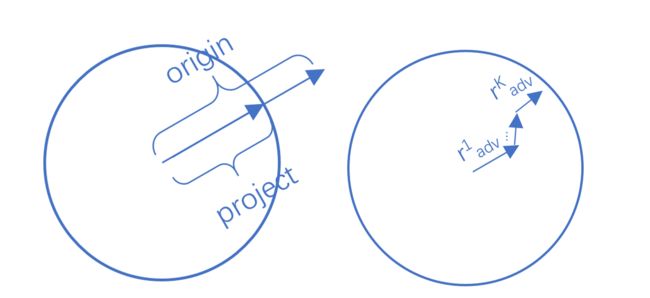
PGD1 是一种迭代攻击,相比于普通的 FGM 的一步到位,PGD 选择小步走,多次迭代每次走一小步,每次迭代都会将扰动投射到规定范围内——即如果走出了扰动半径为 e p s i l o n epsilon epsilon 的空间,就映射回球面上,以保证扰动不要过大
r a d v t + 1 = Π ∣ ∣ r a d v ∣ ∣ F ≤ ϵ ( r a d v t + α ⋅ g ( r a d v t ) / ∣ ∣ g ( r a d v t ) ∣ ∣ 2 ) g ( r a d v t ) = ▽ r a d v L ( f θ ( x + r a d v t ) , y ) r^{t+1}_{adv}=\Pi_{||r_{adv}||_F\leq\epsilon}(r^t_{adv}+\alpha\cdot g(r^t_{adv})\ /\ ||g(r^t_{adv})||_2)\\ g(r^t_{adv})=\triangledown_{r_{adv}}L(f_{\theta}(x+r^t_{adv}), y) radvt+1=Π∣∣radv∣∣F≤ϵ(radvt+α⋅g(radvt) / ∣∣g(radvt)∣∣2)g(radvt)=▽radvL(fθ(x+radvt),y)
∣ ∣ r a d v ∣ ∣ F ≤ ϵ ||r_{adv}||_F\leq\epsilon ∣∣radv∣∣F≤ϵ 是扰动的约束空间, Π ∣ ∣ r a d v ∣ ∣ F ≤ ϵ \Pi_{||r_{adv}||_F\leq\epsilon} Π∣∣radv∣∣F≤ϵ 是在 ϵ \epsilon ϵ-ball 上的投影,当扰动幅度过大时,我们将 origin 部分拉回到边界球的投影处,多次操作即是在球内的多次叠加
"""
对于每个x:
1.计算x的前向loss、反向传播得到梯度并备份
对于每步t:
2.根据embedding矩阵的梯度计算出r,并加到当前embedding上,相当于x+r(超出范围则投影回epsilon内)
3.t不是最后一步: 将梯度归0,根据x+r计算前后向并得到梯度
4.t是最后一步: 恢复第一步的梯度,计算最后的x+r并将梯度累加到第一步上
5.将embedding恢复为第一步时的值
6.根据第四步的梯度对参数进行更新
"""
import torch
class PGD():
def __init__(self, model):
self.model = model
self.emb_backup = {}
self.grad_backup = {}
def attack(self, epsilon=1., alpha=0.3, emb_name='emb.', is_first_attack=False):
# emb_name这个参数要换成你模型中embedding的参数名
for name, param in self.model.named_parameters():
if param.requires_grad and emb_name in name:
if is_first_attack:
self.emb_backup[name] = param.data.clone()
norm = torch.norm(param.grad)
if norm != 0 and not torch.isnan(norm):
r_at = alpha * param.grad / norm
param.data.add_(r_at)
param.data = self.project(name, param.data, epsilon)
def restore(self, emb_name='emb.'):
# emb_name这个参数要换成你模型中embedding的参数名
for name, param in self.model.named_parameters():
if param.requires_grad and emb_name in name:
assert name in self.emb_backup
param.data = self.emb_backup[name]
self.emb_backup = {}
def project(self, param_name, param_data, epsilon):
r = param_data - self.emb_backup[param_name]
if torch.norm(r) > epsilon:
r = epsilon * r / torch.norm(r)
return self.emb_backup[param_name] + r
def backup_grad(self):
for name, param in self.model.named_parameters():
if param.requires_grad:
self.grad_backup[name] = param.grad.clone()
def restore_grad(self):
for name, param in self.model.named_parameters():
if param.requires_grad:
param.grad = self.grad_backup[name]
# 使用的时候,要麻烦一点
pgd = PGD(model)
K = 3
for batch_input, batch_label in data:
# 正常训练
loss = model(batch_input, batch_label)
loss.backward() # 反向传播,得到正常的grad
pgd.backup_grad()
# 对抗训练
for t in range(K):
pgd.attack(is_first_attack=(t==0)) # 在embedding上添加对抗扰动, first attack时备份param.data
if t != K-1:
model.zero_grad()
else:
pgd.restore_grad()
loss_adv = model(batch_input, batch_label)
loss_adv.backward() # 反向传播,并在正常的grad基础上,累加对抗训练的梯度
pgd.restore() # 恢复embedding参数
# 梯度下降,更新参数
optimizer.step()
model.zero_grad()
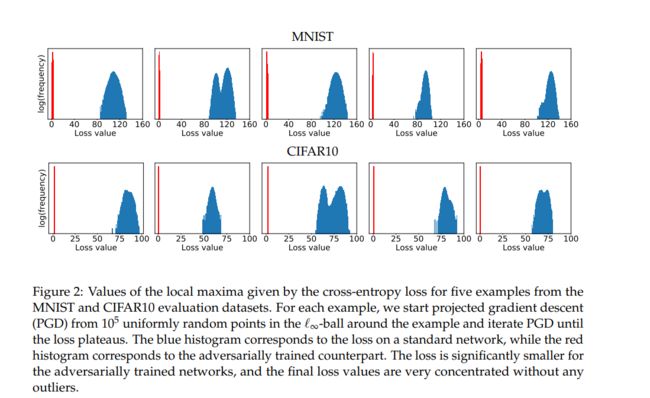
论文中,作者给出了如下图所示的对比,可以发现所有的一阶对抗都能得到一个非常低且集中的损失值分布。因此,在论文中,作者称 PGD 为一阶最强对抗。也就是说,只要能搞定 PGD 对抗,别的一阶对抗就不在话下
Free Adversarial Training(FreeAT)
从 FGSM 到 PGD,主要是优化对抗扰动的计算,虽然取得了更好的效果,但计算量也一步步增加
普通的 PGD 方法,在计算一个 epoch 的一个 batch时:
- 内层循环经过 K 次前向后向的传播,得到 K 个关于输入的梯度
- 外层循环经过 1 次前后向的传播得到关于参数的梯度更新网络
这样的计算成本是十分高昂的,其实,我们在针对输入或参数中的一个计算梯度时,能够几乎无成本的得到另外一个的梯度。这就是 Free Adversarial Training 的思想,在一次计算中利用更多的信息加速对抗性学习的训练
FreeAT4 的核心是同步更新扰动和模型参数,如下图所示
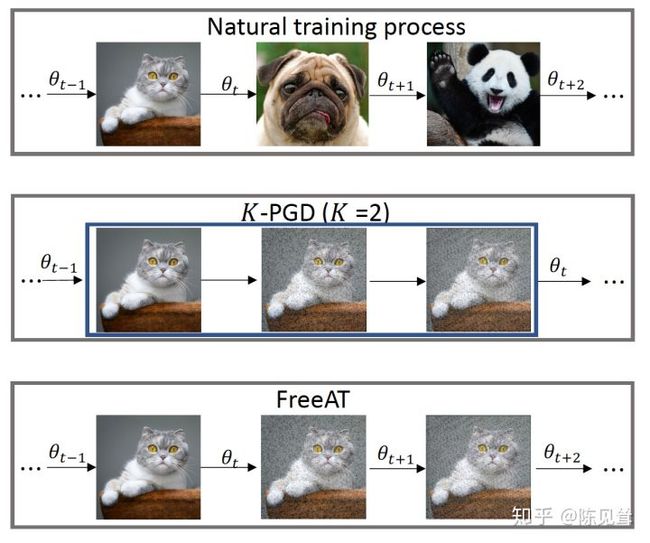
FreeAT 对每个样本进行连续重复的 m m m 次训练,为了保证总的梯度计算次数和普通训练的梯度次数一样,把原来的 epoch 除以 m m m,完整的算法流程如下图所示

另外,可以看到的是,下一个 minibatch 过来时会使用上一次 minibatch 的扰动做一个预热
YOPO
YOPO5 的出发点是利用神经网络的结构来降低梯度计算的计算量。从极大值原理PMP(Pontryagin’s maximum principle)出发,对抗扰动只和网络的第 0 层有关,即在 embedding 层上添加扰动。再加之,层之间是解耦合的,那就不需要每次都计算完整的前后向传播
基于这个想法,作者就想复用后面几层的梯度,减少非必要的完整传播。如下图所示,可以将 PGD 的 r r r 次攻击拆成 m × n m\times n m×n 次
- 首先在 m m m 轮中,每轮只进行一次前向后向传播
- 每轮传播中,进行完整的前向传播,在接下来的反向传播中到第 1 层就停止,用 p p p 记录下反向传播的结果;接着再第 0 层上进行 n n n 次攻击,这样 YOPO 只完成了 m m m 次的完整正向反向传播但却实现了 m × n m\times n m×n 次扰动的更新

下面我们描述一下 gradient based YOPO 的具体内容

下图是完整的算法流程

Free Large Batch Adversarial Training( FreeLB)
YOPO 看着很厉害,但是好景不长,很快 FreeLB6 就指出 YOPO 的假设对于 ReLU-based 网络来说是不成立的,因为 YOPO 要求损失是两次可微的
另外,FreeLB 认为 FreeAT 和 PGD 在获取最优扰动时的计算都存在问题。于是,FreeLB 在 FreeAT 的基础上将每次 inner-max 中更新模型参数这一操作换掉,利用 K K K 步之后累积的参数梯度进行更新(如下面算法中的第 8、13 行所示),于是总体任务的目标函数就记为
m i n θ E ( Z , y ) ∼ D [ 1 K ∑ t = 0 K − 1 m a x δ t ∈ I t L ( f θ ( X + δ t ) , y ) ] I t = B X + δ 0 ( α t ) ∩ B X ( ϵ ) \underset{\theta}{min}\mathbb E_{(Z,y)\sim \mathcal D}\left[\frac{1}{K}\sum_{t=0}^{K-1}\underset{\delta_t\in\mathcal I_t}{max}\ L(f_\theta(X+\delta_t),y)\right]\\ \mathcal I_t=\mathcal B_{X+\delta_0}(\alpha t)\cap\mathcal B_X(\epsilon) θminE(Z,y)∼D[K1t=0∑K−1δt∈Itmax L(fθ(X+δt),y)]It=BX+δ0(αt)∩BX(ϵ)
X + δ t X+\delta_t X+δt 可以看成两个球形邻域的交上局部最大的近似。同时,通过累积参数梯度的操作,我们可以看作是输入了 [ X + δ 0 , ⋯ , X + δ K − 1 ] [X+\delta_0,\cdots,X+\delta_{K-1}] [X+δ0,⋯,X+δK−1] 这样一个虚拟的 K K K 倍大小的 batch
(对上面公式解释一点,input subwords 的 one-hot representations 记为 Z Z Z,embedding matrix 记为 V V V,subwords embedding 记为 X = V Z X=VZ X=VZ)
依据下面算法中的数学符号,PGD 需要进行 N e p ⋅ ( K + 1 ) N_{ep}\cdot(K+1) Nep⋅(K+1) 次梯度计算,FreeAT 需要进行 N e p N_{ep} Nep 次,FreeLB 需要 N e p ⋅ K N_{ep}\cdot K Nep⋅K 次。虽然,FreeLB 在效率上并没有特别大的优势,但是其效果十分不错

另外,论文中指出对抗训练和 dropout 不能同时使用,加上 dropout 相当于改变了网络的结果,影响扰动的计算。如果一定要加入 dropout 操作,需要在 K K K 步中都使用同一个 mask
SMoothness-inducing Adversarial Regularization(SMART)
之前我们看到的所有操作基本都是基于 Min-Max 的目标函数 ,但是在 SMART7 中却放弃了 Min-Max 公式,选择通过正则项 Smoothness-inducing Adversarial Regularization 完成对抗学习。为了解决这个新的目标函数作者又提出了优化算法 Bregman Proximal Point Optimization,这就是 SMART 的两个主要内容
SMART 的主要想法是强制模型在 neighboring data points 上作出相似的预测,加入正则项后的目标函数如下所示
m i n θ F ( θ ) = L ( θ ) + λ s R s ( θ ) ) L ( θ ) = 1 n ∑ i = 1 n ℓ ( f ( x i ; θ ) , y i ) R s ( θ ) = 1 n ∑ i = 1 n m a x ∣ ∣ x ~ i − x i ∣ ∣ p ≤ ϵ ℓ s [ f ( x ~ i ; θ ) , f ( x i ; θ ) ] \underset{\theta}{min}\ \mathcal F(\theta)=\mathcal L(\theta)+\lambda_s\mathcal R_s(\theta))\\ \mathcal L(\theta)=\frac{1}{n}\sum_{i=1}^{n}\ell\left(f(x_i;\theta),y_i\right)\\ \mathcal R_s(\theta)=\frac{1}{n}\sum_{i=1}^{n}\underset{||\tilde x_i-x_i||_p\leq\epsilon}{max}\ \ell_s\left[f(\tilde x_i;\theta),f(x_i;\theta)\right] θmin F(θ)=L(θ)+λsRs(θ))L(θ)=n1i=1∑nℓ(f(xi;θ),yi)Rs(θ)=n1i=1∑n∣∣x~i−xi∣∣p≤ϵmax ℓs[f(x~i;θ),f(xi;θ)]
ℓ \ell ℓ 是具体任务的损失函数, x ~ i \tilde x_i x~i 是 generated neighbors of training points , ℓ s \ell_s ℓs 在分类任务中使用对称的 KL 散度,即 ℓ s ( P , Q ) = D K L ( P ∣ ∣ Q ) + D K L ( Q ∣ ∣ L ) \ell_s(P,Q)=\mathcal D_{KL}(P||Q)+D_{KL}(Q||L) ℓs(P,Q)=DKL(P∣∣Q)+DKL(Q∣∣L);在回归任务中使用平方损失, ℓ s ( p , q ) = ( p − q ) 2 \ell_s(p,q)=(p-q)^2 ℓs(p,q)=(p−q)2
此时可以看到对抗发生在正则化项上,对抗的目标是最大扰动前后的输出
Bregman Proximal Point Optimization 也可以看作是一个正则项,其目的是让模型更新得温柔一点,换句话说就是防止更新的时候 θ t + 1 \theta_{t+1} θt+1 和前面的 θ t \theta_t θt 变化过大。在第 t + 1 t+1 t+1 次迭代时,采用 vanilla Bregman proximal point (VBPP) method
θ t + 1 = a r g m i n θ F ( θ ) + μ D B r e g ( θ , θ t ) (2) \theta_{t+1}=argmin_{\theta}\mathcal F(\theta)+\mu\mathcal D_{Breg}(\theta,\theta_t)\tag{2} θt+1=argminθF(θ)+μDBreg(θ,θt)(2)
其中 D B r e g \mathcal D_{Breg} DBreg 表示 Bregman divergence 定义为
D B r e g ( θ , θ t ) = 1 n ∑ i = 1 n ℓ s ( f ( x i ; θ ) , f ( x i ; θ t ) ) \mathcal D_{Breg}(\theta,\theta_t)=\frac{1}{n}\sum_{i=1}^n\ell_s\left(f(x_i;\theta),f(x_i;\theta_t)\right) DBreg(θ,θt)=n1i=1∑nℓs(f(xi;θ),f(xi;θt))
ℓ s \ell_s ℓs 是上面给出的对称 KL 散度
我们可以使用动量来加速 VBPP,此时定义 β \beta β 为动量,记 θ ~ = ( 1 − β ) θ t + β θ ~ t − 1 \tilde\theta=(1-\beta)\theta_t+\beta\tilde\theta_{t-1} θ~=(1−β)θt+βθ~t−1 表示指数移动平均,那么 momentum Bregman proximal point (MBPP) method 就可以表示为
θ t + 1 = a r g m i n θ F ( θ ) + μ D B r e g ( θ , θ ~ t ) (3) \theta_{t+1}=argmin_{\theta}\mathcal F(\theta)+\mu\mathcal D_{Breg}(\theta,\tilde\theta_t)\tag{3} θt+1=argminθF(θ)+μDBreg(θ,θ~t)(3)
下面是 SMART 的完整算法流程
"""
注释一下 Algorithm 1
对于 t 轮迭代:
备份 theta,作为 Bregman divergence 计算的 theta_t
对于每一个 batch:
使用正态分布随机初始化扰动,结合 x 得到 x_tilde
循环 m 小步:
计算扰动下的梯度 g_tilde
基于 g_tilde 和学习率更新 x_tilde
基于 x_tilde 重新计算梯度,更新参数 theta
更新 theta_t
"""

Reference
博客引用
- 一文搞懂NLP中的对抗训练FGSM/FGM/PGD/FreeAT/YOPO/FreeLB/SMART
- NLP — >对抗学习:从FGM, PGD到FreeLB
- 论文阅读:对抗训练(adversarial training)
- 如何加速对抗样本防御?
- SMART: Robust and Efficient Fine-Tuning for Pre-trained Natural Language…
- SMART: 通用对抗式训练
论文引用
Madry A, Makelov A, Schmidt L, et al. Towards deep learning models resistant to adversarial attacks[J]. arXiv preprint arXiv:1706.06083, 2017. ↩︎ ↩︎
Goodfellow I J, Shlens J, Szegedy C. Explaining and harnessing adversarial examples[J]. arXiv preprint arXiv:1412.6572, 2014. ↩︎
Miyato T, Dai A M, Goodfellow I. Adversarial training methods for semi-supervised text classification[J]. arXiv preprint arXiv:1605.07725, 2016. ↩︎
Shafahi A, Najibi M, Ghiasi A, et al. Adversarial training for free![J]. arXiv preprint arXiv:1904.12843, 2019. ↩︎
Zhang D, Zhang T, Lu Y, et al. You only propagate once: Accelerating adversarial training via maximal principle[J]. arXiv preprint arXiv:1905.00877, 2019. ↩︎
Zhu C, Cheng Y, Gan Z, et al. Freelb: Enhanced adversarial training for natural language understanding[J]. arXiv preprint arXiv:1909.11764, 2019. ↩︎
Jiang H, He P, Chen W, et al. Smart: Robust and efficient fine-tuning for pre-trained natural language models through principled regularized optimization[J]. arXiv preprint arXiv:1911.03437, 2019. ↩︎