【语义分割】2019-DANet CVPR
文章目录
- 【语义分割】2019-DANet CVPR
-
- 1. 简介
-
- 1.1 摘要
- 2. 网络
-
- 2.1 整体架构
- 2.2 位置注意力模块(Position Attention Module)
- 2.3 通道注意力模块(Channel Attention Module)
- 2.4 Attention Module Embedding with Networks
- 3. 代码
【语义分割】2019-DANet CVPR
论文题目:DANet:Dual Attention Network for Scene Segmentation
论文链接:https://arxiv.org/abs/1809.02983
论文代码:https://github.com/junfu1115/DANet/
1. 简介
1.1 摘要
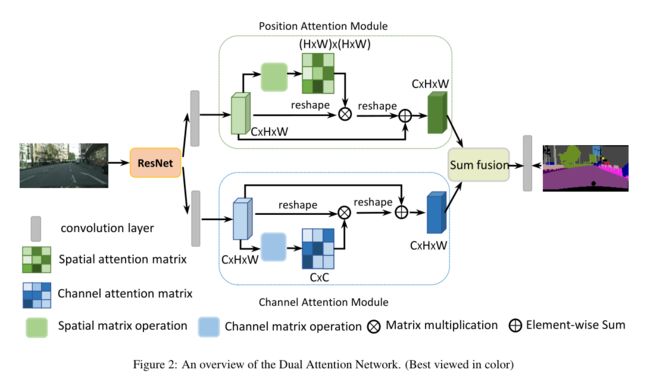
该论文提出新型的场景分割网络DANet,利用自注意力机制进行丰富语义信息的捕获,在带有空洞卷积的FCN架构的尾部添加两个并行的注意力模块:位置注意力模块和通道注意力模块,论文在Cityscapes,PASCAL Context和COCO数据集上都取得了SOTA效果。
- 在位置注意力模块中,任一位置的特征的更新是通过图像所有位置上特征的带权聚合进行更新,权重是由两个位置上特征的相似性决定的,也就是说无论两个位置的距离只要他们的特征相似那么就能得到更高的权重。
- 通道注意力模块中也应用了相似的自注意力机制来学习任意两个通道映射之间的关系,同样通过所有通道的带权加和来更新某一个通道。
总的来说一句话:将空间维度和通道维度上的语义信息分开进行提取,最后再做特征融合
2. 网络
2.1 整体架构
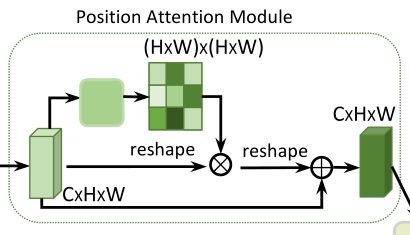
2.2 位置注意力模块(Position Attention Module)
其中position attention module使用自注意力机制捕获特征图在任意两个位置之间的空间依赖关系,通过加权求和对所有位置的特征进行聚合更新,权重是由对应两个位置的特征相似性决定的。
Spatial attention map的计算如下:
s j i = exp ( B i ⋅ C j ) ∑ i = 1 N exp ( B i ⋅ C j ) s_{j i}=\frac{\exp \left(B_{i} \cdot C_{j}\right)}{\sum_{i=1}^{N} \exp \left(B_{i} \cdot C_{j}\right)} sji=∑i=1Nexp(Bi⋅Cj)exp(Bi⋅Cj)
S j i S_{ji} Sji度量第i个位置对第j个位置的影响,也就是第i个位置和第j个位置之间的关联程度/相关性,越大越相似。
Output的计算如下:
E j = α ∑ i = 1 N ( s j i D i ) + A j E_{j}=\alpha \sum_{i=1}^{N}\left(s_{j i} D_{i}\right)+A_{j} Ej=αi=1∑N(sjiDi)+Aj
α \alpha α表示尺度系数,初始化为0,并逐渐地学习分配到更大的权重。每个位置的结果特征E,是所有位置和原始位置的加权和。因此它具有全局上下文视图,并能根据空间注意力图有选择地聚合上下文。
代码流程
- 特征图A(C×H×W)首先分别通过3个卷积层得到3个特征图B,C,D,然后将B,C,D reshape为C×N,其中N=H×W
- 之后将reshape后的B的转置(NxC)与reshape后的C(CxN)相乘,再通过softmax得到spatial attention map S(N×N)
- 接着在reshape后的D(CxN)和S的转置(NxN)之间执行矩阵乘法,再乘以尺度系数α,再reshape为原来形状,最后与A相加得到最后的输出E
- 其中 α \alpha α初始化为0,并逐渐的学习得到更大的权重
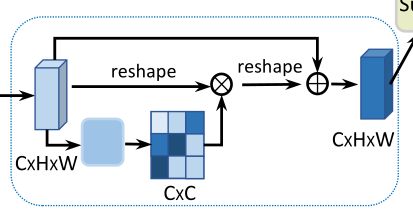
2.3 通道注意力模块(Channel Attention Module)
Channel attention module使用自注意力机制来捕获任意两个通道图之间的通道依赖关系,并使用所有通道图的加权,和更新每个通道图。
Channel attention map的计算:
x j i = exp ( A i ⋅ A j ) ∑ i = 1 C exp ( A i ⋅ A j ) x_{j i}=\frac{\exp \left(A_{i} \cdot A_{j}\right)}{\sum_{i=1}^{C} \exp \left(A_{i} \cdot A_{j}\right)} xji=∑i=1Cexp(Ai⋅Aj)exp(Ai⋅Aj)
x j i x_{ji} xji度量第i个通道对第j个通道的影响。
Output的计算如下:
E j = β ∑ i = 1 C ( x j i A i ) + A j E_{j}=\beta \sum_{i=1}^{C}\left(x_{j i} A_{i}\right)+A_{j} Ej=βi=1∑C(xjiAi)+Aj
β \beta β表示尺度系数,初始化为0,并逐渐地学习分配到更大的权重。每个通道的结果特征E,是所有通道特征和原始特征的加权和。实现了对特征图之间的长程语义依赖关系建模,有助于提高特征的辨别性。
每个通道的最终特征是所有通道和原始特征的加权和:
- 分别对A做reshape(CxN)和reshape与transpose(NxC)
- 将得到的两个特征图相乘,再通过softmax得到channel attention map X(C×C)
- 接着把X的转置(CxC)与reshape的A(CxN)做矩阵乘法,再乘以尺度系数 β \beta β,再reshape为原来形状,最后与A相加得到最后的输出E
- 其中 β \beta β初始化为0,并逐渐的学习得到更大的权重
2.4 Attention Module Embedding with Networks
两个注意力模块的输出先进行元素求和以完成特征融合
再进行一次卷积生成最终预测图
3. 代码
import torch
import torch.nn as nn
import torch.nn.functional as F
# from backbone import ResNet50
from torchvision.models import resnet50
class ResNet50(nn.Module):
def __init__(self, pretrained=False):
"""Declare all needed layers."""
super(ResNet50, self).__init__()
self.model = resnet50(pretrained=pretrained)
self.relu = self.model.relu # Place a hook
layers_cfg = [4, 5, 6, 7]
self.blocks = []
for i, num_this_layer in enumerate(layers_cfg):
self.blocks.append(list(self.model.children())[num_this_layer])
def base_forward(self, x):
feature_map = []
x = self.model.conv1(x)
x = self.model.bn1(x)
x = self.model.relu(x)
x = self.model.maxpool(x)
for i, block in enumerate(self.blocks):
x = block(x)
feature_map.append(x)
out = nn.AvgPool2d(x.shape[2:])(x).view(x.shape[0], -1)
return feature_map, out
class DANet(ResNet50):
r"""Pyramid Scene Parsing Network
Parameters
----------
nclass : int
Number of categories for the training dataset.
backbone : string
Pre-trained dilated backbone network type (default:'resnet50'; 'resnet50',
'resnet101' or 'resnet152').
norm_layer : object
Normalization layer used in backbone network (default: :class:`mxnet.gluon.nn.BatchNorm`;
for Synchronized Cross-GPU BachNormalization).
aux : bool
Auxiliary loss.
Reference:
Jun Fu, Jing Liu, Haijie Tian, Yong Li, Yongjun Bao, Zhiwei Fang,and Hanqing Lu.
"Dual Attention Network for Scene Segmentation." *CVPR*, 2019
"""
def __init__(self, nclass, aux=True, **kwargs):
super(DANet, self).__init__(nclass)
# DANet的头
self.head = _DAHead(2048, nclass, aux, **kwargs)
self.aux = True
self.__setattr__('exclusive', ['head'])
def forward(self, x):
size = x.size()[2:]
# backbone 一共返回4层特征
feature_map,_ = self.base_forward(x)
# 只使用 后2层特征
c3,c4 = feature_map[2],feature_map[3]
outputs = []
# 返回3个特征
x = self.head(c4)
# torch.Size([1, 19, 7, 7])
# torch.Size([1, 19, 7, 7])
# torch.Size([1, 19, 7, 7])
x0 = F.interpolate(x[0], size, mode='bilinear', align_corners=True)
outputs.append(x0)
if self.aux:
#print('x[1]:{}'.format(x[1].shape))
x1 = F.interpolate(x[1], size, mode='bilinear', align_corners=True)
x2 = F.interpolate(x[2], size, mode='bilinear', align_corners=True)
outputs.append(x1)
outputs.append(x2)
return outputs
class _PositionAttentionModule(nn.Module):
""" Position attention module"""
def __init__(self, in_channels, **kwargs):
super(_PositionAttentionModule, self).__init__()
self.conv_b = nn.Conv2d(in_channels, in_channels // 8, 1)
self.conv_c = nn.Conv2d(in_channels, in_channels // 8, 1)
self.conv_d = nn.Conv2d(in_channels, in_channels, 1)
self.alpha = nn.Parameter(torch.zeros(1))
self.softmax = nn.Softmax(dim=-1)
def forward(self, x):
batch_size, _, height, width = x.size()
feat_b = self.conv_b(x).view(batch_size, -1, height * width).permute(0, 2, 1)
feat_c = self.conv_c(x).view(batch_size, -1, height * width)
attention_s = self.softmax(torch.bmm(feat_b, feat_c))
feat_d = self.conv_d(x).view(batch_size, -1, height * width)
feat_e = torch.bmm(feat_d, attention_s.permute(0, 2, 1)).view(batch_size, -1, height, width)
out = self.alpha * feat_e + x
return out
class _ChannelAttentionModule(nn.Module):
"""Channel attention module"""
def __init__(self, **kwargs):
super(_ChannelAttentionModule, self).__init__()
self.beta = nn.Parameter(torch.zeros(1))
self.softmax = nn.Softmax(dim=-1)
def forward(self, x):
batch_size, _, height, width = x.size()
feat_a = x.view(batch_size, -1, height * width)
feat_a_transpose = x.view(batch_size, -1, height * width).permute(0, 2, 1)
attention = torch.bmm(feat_a, feat_a_transpose)
attention_new = torch.max(attention, dim=-1, keepdim=True)[0].expand_as(attention) - attention
attention = self.softmax(attention_new)
feat_e = torch.bmm(attention, feat_a).view(batch_size, -1, height, width)
out = self.beta * feat_e + x
return out
class _DAHead(nn.Module):
def __init__(self, in_channels, nclass, aux=True, norm_layer=nn.BatchNorm2d, norm_kwargs=None, **kwargs):
super(_DAHead, self).__init__()
self.aux = aux
inter_channels = in_channels // 4
self.conv_p1 = nn.Sequential(
nn.Conv2d(in_channels, inter_channels, 3, padding=1, bias=False),
norm_layer(inter_channels, **({} if norm_kwargs is None else norm_kwargs)),
nn.ReLU(True)
)
self.conv_c1 = nn.Sequential(
nn.Conv2d(in_channels, inter_channels, 3, padding=1, bias=False),
norm_layer(inter_channels, **({} if norm_kwargs is None else norm_kwargs)),
nn.ReLU(True)
)
self.pam = _PositionAttentionModule(inter_channels, **kwargs)
self.cam = _ChannelAttentionModule(**kwargs)
self.conv_p2 = nn.Sequential(
nn.Conv2d(inter_channels, inter_channels, 3, padding=1, bias=False),
norm_layer(inter_channels, **({} if norm_kwargs is None else norm_kwargs)),
nn.ReLU(True)
)
self.conv_c2 = nn.Sequential(
nn.Conv2d(inter_channels, inter_channels, 3, padding=1, bias=False),
norm_layer(inter_channels, **({} if norm_kwargs is None else norm_kwargs)),
nn.ReLU(True)
)
self.out = nn.Sequential(
nn.Dropout(0.1),
nn.Conv2d(inter_channels, nclass, 1)
)
if aux:
self.conv_p3 = nn.Sequential(
nn.Dropout(0.1),
nn.Conv2d(inter_channels, nclass, 1)
)
self.conv_c3 = nn.Sequential(
nn.Dropout(0.1),
nn.Conv2d(inter_channels, nclass, 1)
)
def forward(self, x):
feat_p = self.conv_p1(x)
feat_p = self.pam(feat_p)
feat_p = self.conv_p2(feat_p)
feat_c = self.conv_c1(x)
feat_c = self.cam(feat_c)
feat_c = self.conv_c2(feat_c)
feat_fusion = feat_p + feat_c
outputs = []
fusion_out = self.out(feat_fusion)
outputs.append(fusion_out)
if self.aux:
p_out = self.conv_p3(feat_p)
c_out = self.conv_c3(feat_c)
outputs.append(p_out)
outputs.append(c_out)
return tuple(outputs)
def get_danet( backbone='resnet50', pretrained_base=False, **kwargs):
cityspaces_numclass = 19
model = DANet(cityspaces_numclass, backbone=backbone, pretrained_base=pretrained_base, **kwargs)
return model
if __name__ == '__main__':
img = torch.randn(1,3,224,224)
model = get_danet()
outputs = model(img)
for temp in outputs:
print(temp.shape)
参考资料
DANet论文及代码阅读笔记_IronLavender的博客-CSDN博客_danet
Semantic Segmentation—DANet:Dual Attention Network for Scene Segmentation(论文解读九)_Jayden yang的博客-CSDN博客