何恺明Focal Loss改进版!GFocal Loss:良心技术,无cost涨点
点击上方“计算机视觉工坊”,选择“星标”
干货第一时间送达
![]()
来自 | 知乎 作者 | 李翔
编辑 | AI科技评论
在ICCV 2017上,Kaiming大神所在的FAIR团队“随手”发了一篇名为《Focal Loss for Dense Object Detection》的论文。
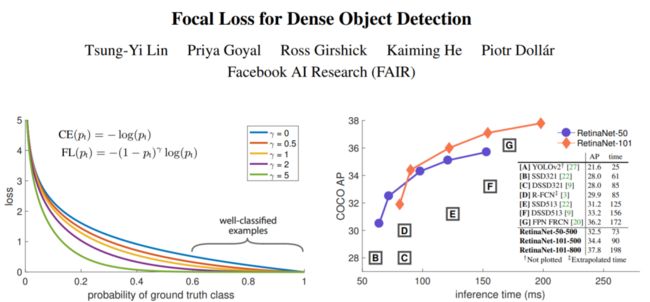
没曾想一石激起千层浪,这篇论文在解决目标检测中正负样本不平衡的问题上做出了很大的贡献,也为后人在此问题上开拓了新的思路。
Focal Loss是为one-stage的检测器的分类分支服务的,它支持0或者1这样的离散类别label。
那么,如果对于label是0~1之间的连续值呢?
我们既要保证Focal Loss此前的平衡正负、难易样本的特性,又需要让其支持连续数值的监督,这该如何实现呢?
今天要介绍的这篇论文就是在解决这个问题,且凭借出色的工作,论文刚刚被NeurIPS 2020 接收。

论文链接:https://arxiv.org/pdf/2006.04388.pdf
源码和预训练模型地址:https://github.com/implus/GFocal
GFocal目前已被MMDetection官方收录:https://github.com/openmmlab/mmdetection/blob/master/configs/gfl/README.md
论文第一作者:李翔博士,师从长江学者杨健教授。曾获阿里巴巴天池和滴滴研究院大数据竞赛冠军。在cvpr,neurips,ijcai,aaai等顶会发表10+篇一作或共一论文,Google Citation 650+。

个人主页:http://implus.github.io/
接下来是作者本人对论文的随手解读:
1
方法
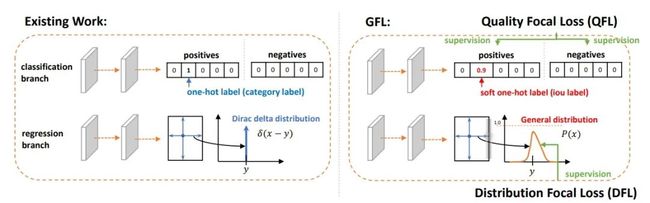
本论文工作达到的效果:良心技术,别问,问就是无cost涨点。
一句话总结:基于任意one-stage检测器上,调整框本身与框质量估计的表示,同时用泛化版本的GFocal Loss训练该改进的表示,无cost涨点(一般1个点出头)AP。
这个工作核心是围绕“表示”的改进来的,也就是大家所熟知的“representation”这个词。这里的表示具体是指检测器最终的输出,也就是head末端的物理对象,目前比较强力的one-stage anchor-free的检测器(以FCOS,ATSS为代表)基本会包含3个表示:
1、类表示;
2、 检测框表示;
3、检测框的质量估计(在FCOS/ATSS中,目前采用centerness,当然也有一些其他类似的工作会采用IoU,这些score基本都在0~1之间)。
三个表示一般情况下如图所示:
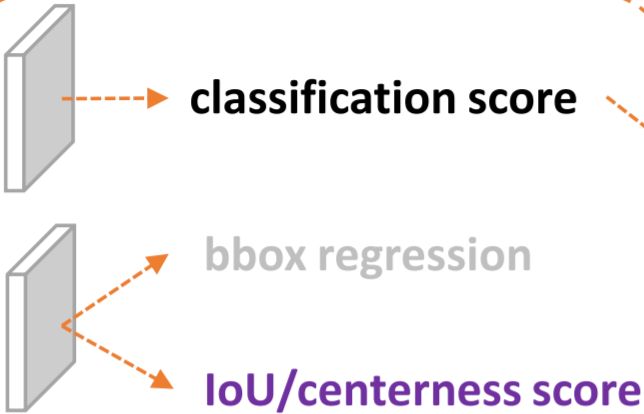 三个表示
三个表示
那么要改进表示一定意味着现有的表示或多或少有那么一些问题。事实上,我们具体观察到了下面两个主要的问题:
问题一:classification score 和 IoU/centerness score 训练测试不一致。
这个不一致主要体现在两个方面:
1、用法不一致。
训练的时候,分类和质量估计各自训记几个儿的,但测试的时候却又是乘在一起作为NMS score排序的依据,这个操作显然没有end-to-end,必然存在一定的gap。
2、对象不一致。
借助Focal Loss的力量,分类分支能够使得少量的正样本和大量的负样本一起成功训练,但是质量估计通常就只针对正样本训练。
那么,对于one-stage的检测器而言,在做NMS score排序的时候,所有的样本都会将分类score和质量预测score相乘用于排序,那么必然会存在一部分分数较低的“负样本”的质量预测是没有在训练过程中有监督信号的,有就是说对于大量可能的负样本,他们的质量预测是一个未定义行为。
这就很有可能引发这么一个情况:一个分类score相对低的真正的负样本,由于预测了一个不可信的极高的质量score,而导致它可能排到一个真正的正样本(分类score不够高且质量score相对低)的前面。
问题一如图所示:
 不一致啊不一致, End-to-end 表示很难受
不一致啊不一致, End-to-end 表示很难受
问题二:bbox regression 采用的表示不够灵活,没有办法建模复杂场景下的uncertainty。
问题二比较好理解,在复杂场景中,边界框的表示具有很强的不确定性,而现有的框回归本质都是建模了非常单一的狄拉克分布,非常不flexible。
我们希望用一种general的分布去建模边界框的表示。问题二如图所示(比如被水模糊掉的滑板,以及严重遮挡的大象):
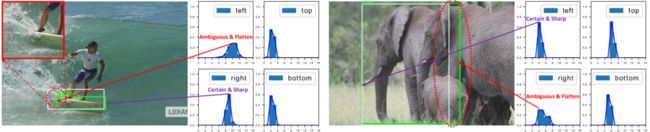 模糊及界定不清晰的边界
模糊及界定不清晰的边界
那么有了这些问题,我们自然可以提出一些方案来一定程度上解决他们:
1、对于第一个问题,为了保证training和test一致,同时还能够兼顾分类score和质量预测score都能够训练到所有的正负样本,那么一个方案呼之欲出:就是将两者的表示进行联合。这个合并也非常有意思,从物理上来讲,我们依然还是保留分类的向量,但是对应类别位置的置信度的物理含义不再是分类的score,而是改为质量预测的score。这样就做到了两者的联合表示,同时,暂时不考虑优化的问题,我们就有可能完美地解决掉第一个问题。
2、对于第二个问题,我们选择直接回归一个任意分布来建模框的表示。当然,在连续域上回归是不可能的,所以可以用离散化的方式,通过softmax来实现即可。这里面涉及到如何从狄拉克分布的积分形式推导到一般分布的积分形式来表示框,详情可以参考原论文。
Ok,方案都出来了还算比较靠谱,但是问题又来了:
怎么优化他们呢?
这个时候就要派上Generalized Focal Loss出马了!
我们知道之前Focal Loss是为one-stage的检测器的分类分支服务的,它支持0或者1这样的离散类别label。
然而,对于我们的分类-质量联合表示,label却变成了0~1之间的连续值。我们既要保证Focal Loss此前的平衡正负、难易样本的特性,又需要让其支持连续数值的监督,自然而然就引出了我们对Focal Loss在连续label上的拓展形式之一,我们称为Quality Focal Loss (QFL),具体地,它将原来的Focal Loss从:
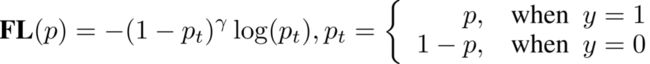
魔改为:
![]()
其中y为0~1的质量标签,![]() 为预测;注意QFL的全局最小解即是
为预测;注意QFL的全局最小解即是![]() = y。
= y。
这样交叉熵部分变为完整的交叉熵,同时调节因子变为距离绝对值的幂次函数。
和Focal Loss类似,我们实验中发现一般取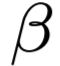 = 2为最优。
= 2为最优。
对于任意分布来建模框的表示,它可以用积分形式嵌入到任意已有的和框回归相关的损失函数上,例如最近比较流行的GIoU Loss。
这个实际上也就够了,不过涨点不是很明显,我们又仔细分析了一下,发现如果分布过于任意,网络学习的效率可能会不高,原因是一个积分目标可能对应了无穷多种分布模式。
如下图所示:
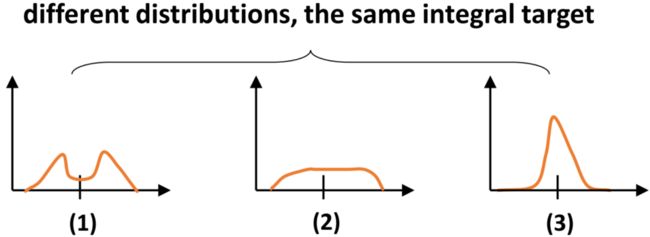 各种各样的表示
各种各样的表示
考虑到真实的分布通常不会距离标注的位置太远,所以我们又额外加了个loss,希望网络能够快速地聚焦到标注位置附近的数值,使得他们概率尽可能大。基于此,我们取了个名字叫Distribution Focal Loss (DFL):
![]()
其形式上与QFL的右半部分很类似,含义是以类似交叉熵的形式去优化与标签y最接近的一左一右两个位置的概率,从而让网络快速地聚焦到目标位置的邻近区域的分布中去。
最后,QFL和DFL其实可以统一地表示为GFL,我们将其称之为Generalized Focal Loss,同时也是为了方便指代,其具体形式如下:
![]()
我们在附录中也给出了:Focal Loss,包括本文提出的QFL和DFL都可以看做为GFL中的变量取到特定值的特例。
2
实验
接下来是实验部分。Ablation Study就不展开了,重点的结论即是:
1、这两个方法,即QFL和DFL的作用是正交的,他们的增益互不影响,所以结合使用更香(我们统一称之为GFL)。
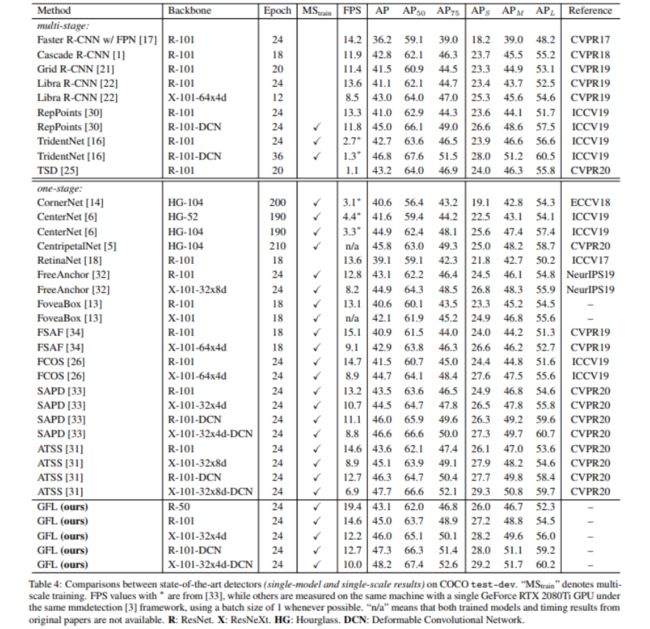
我们在基于Resnet50的backbone的ATSS(CVPR20)的baseline上1x训练无multi-scale直接基本无cost地提升了一个点,在COCO validation上从39.2 提到了40.2 AP。
实际上QFL还省掉了原来ATSS的centerness那个分支,不过DFL因为引入分布表示需要多回归一些变量,所以一来一去inference的时间基本上也没什么变化。
2、在2x + multi-scale的训练模式下,在COCO test-dev上,Resnet50 backbone用GFL一把干到了43.1 AP,这是一个非常可观的性能。
同时,基于ResNeXt-101-32x4d-DCN backbone,能够有48.2的AP且在2080Ti单GPU上有10FPS的测速,还是相当不错的speed-accuracy trade-off了。
放一些重点的实验插图:

最后,附录里面其实有不少彩蛋。
第一个彩蛋是关于IoU和centerness的讨论。在对比实验中,我们发现IoU作为框预测质量的度量会始终比centerness更优。于是我们又具体深入分析了一些原因,发现的确从原理上来讲,IoU可能作为质量的估计更加合适。
具体原因如下:
1、IoU本身就是最终metric的衡量标准,所以用来做质量估计和排序是非常自然的。
2、centerness有一些不可避免的缺陷,比如对于stride=8的FPN的特征层(也就是P3),会存在一些小物体他们的centerness label极度小甚至接近于0,如下图所示:

而IoU就会相对好很多。我们也统计了一下两者作为label的分布情况,如图:
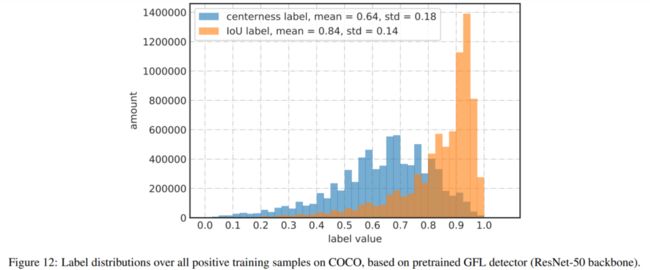
这意味着IoU的label相对都较大,而centerness的label相对都较小,同时还有非常非常小的。
可以想见,如果有一些正样本的centerness的label本身就很小,那么他们最后在做NMS排序的时候,乘上一个很小的数(假设网络学到位了),那么就很容易排到很后面,那自然性能就不容易上去了。
所以,综合各种实验以及上述的分析,个人认为centerness可能只是一个中间产物(当然,其在FCOS中提出时的创新性还是比较valuable的),最终历史的发展轨迹还是要收敛到IoU来。
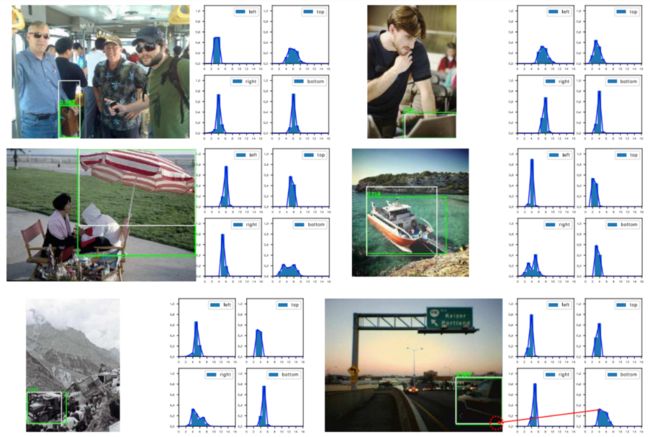
第二个彩蛋是分布式表示的一些有趣的观察。
我们发现有一些分布式表示学到了多个峰,比如伞这个物体,它的伞柄被椅子严重遮挡。
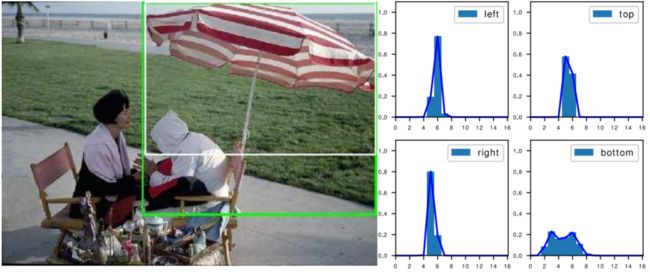
如果我们不看伞柄,那么可以按照白色框(gt)来定位伞,但如果我们算上伞柄,我们又可以用绿色框(预测)来定位伞。
在分布上,它也的确呈现一个双峰的模式(bottom),它的两个峰的概率会集中在底部的绿线和白线的两个位置。这个观察还是相当有趣的。
这可能带来一个妙用,就是我们可以通过分布shape的情况去找哪些图片可能有界定很模糊的边界,从而再进行一些标注的refine或一致性的检查等等。颇有一种Learn From Data,再反哺Data的感觉。
3
杂谈
最后谈谈检测这块的两个可能的大趋势。
太明显了,一个是kaiming引领的unsupervised learning,妥妥撸起袖子干一个检测友好的unsupervised pretrain model especially for object detection;
还有一个是FAIR最近火爆的DETR。
其实去掉NMS这个事情今年也一直在弄,搞的思路一直不太对,也没搞出啥名堂。
还是DETR花500个epoch引领了一下这个潮流,指了个门道,当然方向有了,具体走成啥样,还是八仙过海,各显神通啦~
本文首发于知乎:https://zhuanlan.zhihu.com/p/147691786
本文仅做学术分享,如有侵权,请联系删文。
下载1
在「计算机视觉工坊」公众号后台回复:深度学习,即可下载深度学习算法、3D深度学习、深度学习框架、目标检测、GAN等相关内容近30本pdf书籍。
下载2
在「计算机视觉工坊」公众号后台回复:计算机视觉,即可下载计算机视觉相关17本pdf书籍,包含计算机视觉算法、Python视觉实战、Opencv3.0学习等。
下载3
在「计算机视觉工坊」公众号后台回复:SLAM,即可下载独家SLAM相关视频课程,包含视觉SLAM、激光SLAM精品课程。
重磅!计算机视觉工坊-学习交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、学术交流、求职交流等微信群,请扫描下面微信号加群,备注:”研究方向+学校/公司+昵称“,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进去相关微信群。原创投稿也请联系。

▲长按加微信群或投稿

▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的知识点汇总、入门进阶学习路线、最新paper分享、疑问解答四个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近2000星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款

圈里有高质量教程资料、可答疑解惑、助你高效解决问题
觉得有用,麻烦给个赞和在看~ 