一文带你了解知识图谱融入预训练模型哪家强?九大模型集中放送
©原创作者 | 疯狂的Max
01 预训练模型与知识图谱
1.预训练模型
近年来,随着语言模型的技术发展,其在NLP领域获得巨大的成功,业界SOTA的前沿模型也大多是Transformer结构模型的变体。
Transformer结构模型使用注意力机制来获取文本中长距离字符间的依赖关系,包括对其进行优化的Transformer XL,BERT使用的MLM模型和XLNET使用的PLM模型。
这种类型的模型对语法知识进行编码,同时在一定程度上扩展了非结构文本中蕴含的语义知识,比如有论文证实了BERT模型在编码过程中获取了句法树的知识[5],也就解释了为什么这些预训练模型能够在语法相关的下游任务上表现良好。
2.知识图谱
知识图谱的概念诞生于2012年,由Google公司首先提出。知识图谱的提出是为了准确地阐述人、事、物之间的关系,最早应用于搜索引擎。
知识图谱在不同应用场景和技术范畴内,定义有所不同,但在自然语言处理视角下,知识图谱可以看做从文本中抽取语义和结构化的数据。
简单来说,知识图谱可以被定义为一种用于表示现实世界知识的图形式的数据,其中的每个节点代表一种实体或属性,连接节点的边表示两节点的关系[3]。
简单理解,可以将知识图谱看做是若干三元组的集合,这些三元组在某个知识领域范畴内表示着各个实体概念之间错综复杂的关系。
这些知识图谱既可以是来自于现实世界的常识类知识图谱,如下图1所示[2]。也可以是基于语言学知识构建的单词图谱,如WordNet[4],这是一个覆盖范围宽广的英语词汇语义网,反映了词语之间同义词,反义词,上下位词等关系,如下图2 所示。
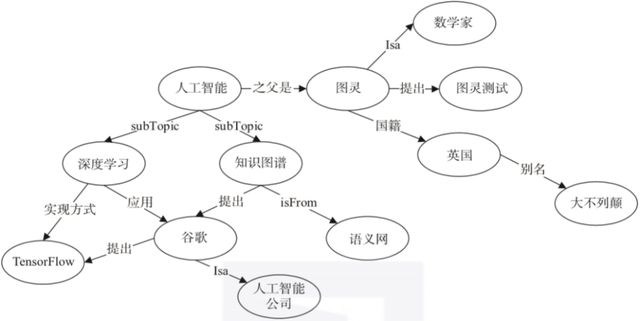
图1 常识概念类的知识图谱示例

图2 WordNet示例
3.将知识图谱融入预训练模型
正如前文提到,预训练模型在一定程度上可以从非结构化的文本信息中获取知识,而知识图谱可以看做从文本中抽取语义和结构化的数据,那么可以预想这两者的结合对于提升模型效果将有极大研究价值和探索空间。
但如何将两者有效的结合起来,也激发了许多研究者的兴趣。是否有通用的融合方式使得可以在任何类型的业务场景下或者是下游任务中,都能有效提升模型效果?或者在某些特定条件下,需要针对不同的垂直领域,对融合方式进行实验调整和选择?本文接下来将对一系列将知识图谱融入预训练模型的研究进行介绍,并归纳总结。
02 知识图谱融入预训练模型的三种方式[3]
由于知识图谱是以图的形式表示实体关系,因此需要对其进行转换和改造,以融入预训练模型中,可以将融合方式分为三种类型:改造模型输入的融合方式、改造模型结构的融合方式和改造模型输出的融合方式[3]。
接下来介绍的一系列研究中,可能是采取其中一种融合方式,或者几种融合方式相结合。
1. 改造模型输入的融合方式(input injection)
这种融合方式被定义为对进入预训练模型的输入进行改造,既包括在预处理阶段将知识图谱的三元组知识融入到输入数据中,也包括将输入中实体的embedding和输入本身的embedding结合起来的方式。
无论是以哪种技术实现,只要是对输入模型的数据进行了与知识图谱相关的改造或结合,都被划分为改造模型输入的融合方式。
2. 改造模型结构的融合方式(architecture injection)
通过改造预训练模型结构的方式来融合外部知识,这种融合方式包括在原有预训练模型的层结构之间加入额外的层或者在最终层之后添加额外的层。
3. 改造模型输出的融合方式(output injection)
通过改造模型的预训练或微调任务,这种改造是基于知识图谱构建的,可以理解为隐性的通过训练模型去适应蕴含知识图谱知识的任务来实现知识图谱的融入,这也包括了对损失函数的重新定义。
以上三种融入方式在整个预训练模型中的流程如下图3所示:
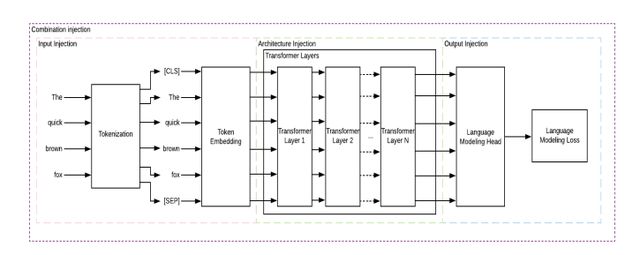
图3 知识图谱融入预训练模型的三种方式
03 知识图谱融入预训练的一系列模型
本文除了从融入方式对模型进行归纳,还将从以下几个维度对每种介绍的模型进行归纳总结:使用的知识图谱类型,是否使用知识图谱嵌套,是否在pre-training和fine-tuning阶段融入知识图谱。
1.K-ADAPTER: Infusing Knowledge into Pre-Trained Models with Adapters
1)论文地址:
https://arxiv.org/pdf/2002.01808.pdf
2)融入方式:architecture injection + output injection
3)使用的知识图谱:Wikipedia(常识类),dependency parse(语法类)
4)是否使用知识图谱嵌套:否
5)是否在pre-training和fine-tuning阶段使用知识图谱的融入:fine-tuning
6)模型的介绍说明
K-ADAPTER通过一种灵活且简单的框架将多种知识图谱融入预训练模型中,保留原本的预训练模型参数不变,通过在预训练模型的中间层之外加入额外的模型结构。
整体的模型框架如下图所示。图(a)是之前大部分通过注入知识图谱相关的多任务学习来更新整个模型参数的框架,图(b) 是K-ADAPTER通过知识适配器引入知识的框架。
具体来说,K-ADAPTER保留了预训练模型原本的参数,使其参数固定,在融入某一种知识的时候,只更新对应的adapter,从而产出不同知识对应的不相互混淆的模型输出。这些不同的adapter结构是在预训练模型的之外的,可以插入和抽取。
其输入是预训练模型中间层的隐层输出结构,这就使得每一个adapter在不同的任务上可以对应融入不同的外部知识,并保证原本的预训练模型的参数是被冻结,不被更新的。

具体来说,每个知识图谱对应一种adapter,每个adapter包含K个adapter层,分别插入到预训练模型原本的不同的transformer层之间。而这中间的每个adapter层由N 个transformer层,2 个映射层和1 个残差连接组成,如下图所示:

每个adapter层连接到预训练模型中不同的transformer层上。其中,每个adapter层的输入为:当前adapter层的输入为连接的 transformer层隐藏层的输出和前一个adapter层的输出,这两个表示进行拼接之后进入adapter层。
而整个K-ADAPTER模型的输出为:将预训练模型最后一层的隐藏层输出和最后一个adapter层的输出,进行拼接作为最终的输出。
文中,作者用RoBERTa作为基础预训练模型,共计335M参数。
在其第0层、11层、23层的transformer层之后加入adapter层,每个adapter层中的transformer层数 、隐层维度和自注意力头为2,768,12,两个映射层维度分别是 1024 和 768。
并且,不同的adapter层之间不共享参数,最终一种adapter包含的参数量为42M。
作者融入了两种类型的知识图谱:一种是维基百科三元组构成的知识图谱,另一种是基于句法依存的语法类知识图谱。
训练好的模型在relation classification,entity typing和question answering这3个知识导向的下游任务上效果都优于RoBERTa,由此可见K-ADAPTER所做的改进是有效的。
7)优点及缺点:
优点:①只需要更新少量参数,训练效率高;②支持持续的多种知识的融入,并且新融入的知识不会对旧知识学习到的参数产生影响。
缺点:并没有对如何针对不同的知识设计不同的训练任务进行探索和说明,模型在实际业务场景中的效果不可知。
2. KT-NET: Enhancing Pre-Trained Language Representations with Rich Knowledge for Machine Reading Comprehension
1)论文地址:
https://aclanthology.org/P19-1226.pdf
2)融入方式:architecture injection
3)使用的知识图谱:WordNet(语法类),NELL(常识类)
4)是否使用知识图谱嵌套:是
5)是否在pre-training和fine-tuning阶段使用知识图谱的融入:fine-tuning
6)模型的介绍说明:
KT-NET将注意力机制应用到对知识图谱内知识抽取中,并将其融入BERT预训练模型,从而提升知识相关的MRC下游任务效果。KT-NET的模型架构如下图所示。

①BERT Encoding Layer:模型的输入经过预训练好的BERT模型,得到最后一层的隐层向量表示,即图中所示的BERT vector,而输入的文本内容里面会抽取出对应的实体,这个实体通过BILINEAR model得到对应的知识图谱中每个实体的知识表示,即图中所指的KB embedding;
②Knowledge integration layer:通过注意力机制将BERT Vector与KB embedding做融合;
③Self-matching layer:通过双层的自注意力机制进一步融合BERT和KB的表示;
④将几种知识图谱对应的输出结果做拼接后进入最终预测层。该模型在MRC任务上表现超过SOTA效果。
7)优点与缺点:
优点:可以同时融合多种知识图谱,对与知识相关的MRC任务提升效果明显
缺点:模型的效果可能与提取KB embedding的模型有关,并且没有考虑KB embedding和BERT vector是通过不同的模型进行映射得到,两者之间存在gap,直接用attention机制融合的合理性还有待进一步探究。
3. KnowBERT:Knowledge Enhanced Contextual Word Representations
1)论文地址:
https://arxiv.org/pdf/1909.04164v2.pdf
2)融入方式:architecture injection + output injection
3)使用的知识图谱:WordNet(语法类),Wikipedia(常识类)
4)是否使用知识图谱嵌套:是
5)是否在pre-training和fine-tuning阶段使用知识图谱的融入:pre-training + fine-tuning
6)模型的介绍说明[6]:
KnowBERT通过在BERT的原始模型两层之间加入KAR层结构来注入知识图谱信息。同时利用了输入文本抽取的span之间,span和entity之间,entity之间的attention来实现交互计算,进一步将知识图谱的信息融入到模型中去。
其主要思想是要在输入文本中显式建模实体跨度(Entity spans),并使用实体链接器(Entity Linker)从KB中检测mention、检索相关的实体嵌入(Entity embeddings),以形成知识增强的实体跨度表示形式。
然后使用word-to-entity attention将单词的表示重新上下文化,以携带全部的实体信息。
具体的实现步骤是,首先需要对输入的文本中的实体进行抽取并或获取其embedding。
其中检测mention的方法用到了共指消解,在此不再详细介绍,KnowBERT的作者也是直接使用其他研究的技术方法,有兴趣的读者可以对本文进行精读研究其实现。
得到mention之后,就需要获取对应的entity embedding,对于不同的知识图谱,做法不完全一致,WordNet采用TuckER的技术获取200维嵌入,而对于Wikipedia,作者在实验部分介绍到他们使用doc2vec的方式直接从Wikipedia描述中学习Wikipedia页面标题的300维嵌入,对于两种融合在一起的数据库作者也介绍了他们使用的方法。
值得注意的是,训练时entity embedding的参数是冻结的,模型训练只会更新BERT结构和加入KAR结构的参数。
接下来,作者通过在BERT的原始模型两层之间加入KAR结构,如下图所示:
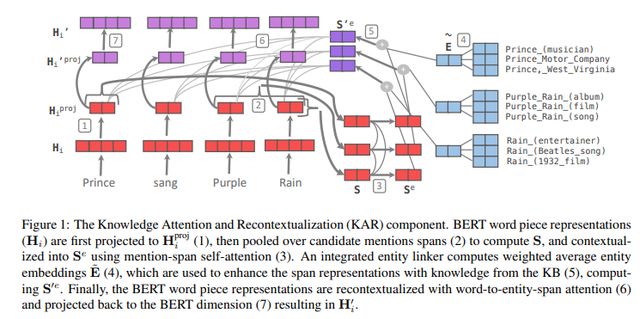
①为了与Entity Embedding维度一致,对来自BERT层的隐层向量进行一个线性投射,得到
![]()
如下图公式所示:
![]()
②使用之前提到过的共指消解的方法,检测到Prince、Purple Rain和Rain这三个mention,并进行了消解,得到了消解后的编码S。
③对于第②步得到的S,通过一个多头self-attention,使得mention可以获得全局信息,得到
![]()
![]()
④之前提到的Entity Linker,作者希望通过训练得到一个可以将mention正确连接到对应实体embedding的连接器。因此对每个mention对应的候选实体列表中的实体embedding通过以下公式依次打分。
![]()
对于对应的ground truth,也就是这个mention所应该真正对应的实体,也就可以对连接器进行训练。loss使用的是这两个当中的之一:


无论使用哪种损失,都是为了让ground truth对应的打分应该高。Max-margin loss还希望除了ground truth的其他打分应该比较低。

⑥对第⑤步的结果通过一个多头attention之后再进行映射,得到的结果再进行一个残差连接得到最终结果,如下图两公式所示:
![]()
![]()
KnowBert作者在实验结果中表明其参数量只比BERT-base多一点,但效果与BERT-large相当。
7)优点与缺点:
优点:①不针对特定任务,对任何下游任务都可以fine-tune;②模型轻量,只在原有预训练模型的基础上增加了少量的参数
缺点:需要更新预训练模型的全部参数,训练速度较慢
4. K-BERT: Enabling Language Representation with Knowledge Graph
1)论文地址:
https://arxiv.org/pdf/1909.07606v1.pdf
2)融入方式:input injection + architecture injection
3)使用的知识图谱:CN-DBpedia(常识类)、HowNet(语法类)、MedicalKG(特定领域)
4)是否使用知识图谱嵌套:否
5)是否在pre-training和fine-tuning阶段使用知识图谱的融入:fine-tuning
6)模型的介绍说明[7]:
针对文本中的词嵌入向量和从知识图谱中实体的词嵌入向量的向量空间不一致的问题和过多引入知识图谱知识造成噪音的问题,K-BERT提出用soft-position和visible matrix在BERT模型中引入外部知识。其整体模型框架如下图所示:

整体的模型框架分为四个模块:knowledge layer,embedding layer,seeing layer和mask-transformer。
对于输入的句子,knowledge layer先融入从知识图谱中抽取的该句子的相关三元组,将原始的句子转换为蕴含有知识图谱知识的句子树。
这个句子树同时进入embedding layer和seeing layer,然后再分别输出对应的token-level embedding representation和visible matrix。
这个visible matrix用于控制每个token可见的区域,防止因为过多的外部知识注入导致原本句子语义的改变。具体每一个模块的计算细节为:
①knowledge layer:给定一个输入的句子
![]()
通过知识图谱的knowledge query得到一个句子中对应实体的三元组集合
![]()
然后这个集合注入到原本的句子s中,从而得到一个句子树,如下图所示:

②embedding layer:通过①得到到的句子树,需要通过embedding layer输出对应的embedding presentation。
与BERT相似,K-BERT的embedding也是token embedding,position embedding和segment embedding三者相加,其不同在于K-BERT的输入是句子树而不是原始句子。
因此,如何将句子树转变成一个句子是K-BERT的关键。
正如下图Figure 2上部分token embedding所示,原本的句子“Tim Cook is currently visiting Beijing now”经过句子树的转换,输入变成“Tim Cook CEO Apple is visiting Beijing capital China is a City now”。
这个句子会产生对应的token embedding,同时这个重组后的输入对应的position embedding也会相应做出调整。
如下图Figure 2中Sentence tree部分所示,如果按照BERT原本的position进行标注,就是黑字对应显示每个token的位置,而K-BERT用soft-position index来产出position index,就使得句子中三元组对应的分支是互不影响的,通过这样的index标注来告诉模型句子正确的语义顺序。
同时,从Figure 2中可以看到,因为三元组的融入,存在位置不同编码相同的问题,解决的方案是用后面会提到的Mask-Self-Attention来解决。
而K-BERT的segment embedding部分与BERT一致,在这里不再赘述。

③seeing layer:正如前文提到的,K-BERT引入KG可能造成noise问题,于是seeing layer层的作用就是通过一个visible matrix来限制词与词之间的联系。如果两个词是来自统一分支,那么两者是可见的,反之不可见,可以用以下公式表示:

④mask-transformer:从某种角度来说,visible matrix M在一定程度上蕴含了句子树的结构化信息,而BERT模型本身的transformer encoder里面是不能直接将visible matrix M作为输入计算的(因为本身的mask计算是正常句子输入进行self-attention计算,输入改变了,但是attention计算方式不变当然是不合理的)。
因此,K-BERT中的将其修正为了Mask-Tranformer,用以限制visible matrix M决定的self-attention的计算区,本质上就是mask-self-attention块的堆叠。
对于一个visible matrix M,相互可见的红色点取值为 0,相互不可见的白色取值为负无穷,如下图所示:

然后把 M 加到计算 self-attention 的 softmax 函数里即可,即如下公式:


以上公式只是对 BERT 里的 self-attention 做简单的修改,多加了一个 M,其余并无差别。
以上就是K-BERT的整个模型改进和输入改进的流程。总的来说,K-BERT除了soft position和visible matrix,其余结构均与 Google BERT 保持一致,这就让其能够兼容所有BERT 类的模型参数包括Roberta,Electra,ERNIE,MacBERT等,理论上将,这样的增益就可以在更好效果的预训练模型上可以进一步提升模型效果。
7)优点与缺点:
优点:与原始的BERT模型相兼容,消除了预训练模型产出的representation与知识图谱之间映射的向量空间不一致问题;通过visible matrix解决knowledge noise的问题。
缺点:fine-tuning一次只能融入一种知识图谱知识。
5.清华ERNIE: Enhanced Language Representation with Informative Entities
1)论文地址:
https://aclanthology.org/P19-1139.pdf
2)融入方式:architecture injection + output injection
3)使用的知识图谱:Wikipedia
4)是否使用知识图谱嵌套:是
5)是否在pre-training和fine-tuning阶段使用知识图谱的融入:pre-taining + fine-tuning
6)模型的介绍说明:
清华ERNIE通过同时在大规模的非结构化的文本语料数据和知识图谱上对模型进行预训练以增强仅仅只吸收了非结构化文本信息的预训练模型。
概括来讲,就是通过改造BERT原本的模型结构,直接在模型中注入知识图谱信息,同时改造预训练的目标任务,通过任务的方式隐性的让模型学习到更多知识图谱的知识。
①模型结构的改进:ERNIE由两种Encoder组成,分别是T-Encoder以及K-Encoder,其中T-Encoder主要是进行输入文本的encoder,提取的是词法以及语义的信息,跟原本的BERT模型的encoder层结构一样,共N层;而K-Encoder用来对来自知识图谱entity embedding进行融合,共M层。如下图所示:

论文中M和N都取值为6,总共加起来12层,与正常的BERT模型一致,并且在进行预训练时,模型参数可以直接用训练好的BERT模型参数进行初始化,作者也是这么做的。

K-Encoder每层(文中称为aggregator)的具体实现可见上图 Figure 2的右边部分,进入的token embedding和entity embedding各自经过一个multi-head self-attention,得到的结果再进行information fusion来实现token序列和entity序列的交互融合,计算出融合后的每个token和entity的output embedding。对于每个token和其对应的entity,其信息融合流程如下:
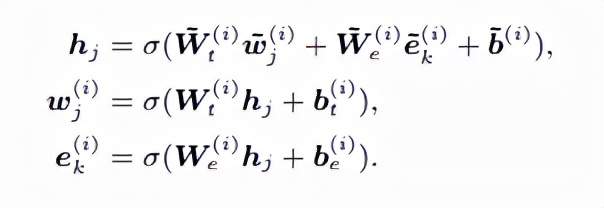
本质上就是通过线性映射和激活函数组合起来的dense层之后再映射加和映射,本文中的激活函数使用的是GELU。而对于没有对应的entity的token,计算流程如下:

第i个aggregator得到的token embedding序列和entity embedding序列一次进入下一个aggregator,最顶层的aggregator得到的output用于连接后续的训练任务。
②训练任务的改进:除了跟预训练模型一样的MLM和NSP任务外,类似于[8]研究者提出的训练一个denoising auto-encoder,ERNIE提出了一种denoising entity auto-encoder(dEA)训练目标进一步隐性的让模型更好的学习到知识图谱的知识。
主要的做法是随机mask一些token-entity alignments 然后要模型根据aligned tokens 去预测entities 。
同时考虑到有可能存在错误的token-entity alignmnent,类似MLM,具体操作为:5%的概率对一个token-entity alignment随机替换entity,让模型预测正确的entity;15%的概率随机mask掉 token-entity alignment,让模型去正确预测token-entity alignment;剩下80%概率,token-entity alignment不变,让模型将知识进行融合。
7)优点与缺点:
优点:可以兼容原版的BERT模型;个人认为还可以在此基础上通过concatenate的方式融合多种知识图谱知识。
缺点:模型结构过于复杂;效果可能强依赖于抽取实体的精准度。
6.BERT-MK: Integrating Graph Contextualized Knowledge into Pre-trained Language Models
1)论文地址:
http://staff.ustc.edu.cn/~tongxu/Papers/Bin_EMNLP20.pdf
2)融入方式:architecture injection + output injection
3)使用的知识图谱:UMLS(medical KG)
4)是否使用知识图谱嵌套:是
5)是否在pre-training和fine-tuning阶段使用知识图谱的融入:pre-training + fine-tuning
6)模型的介绍说明:
BERT-MK的作者指出知识图谱表征的一般做法知识将图谱中的三元组作为一个单独的训练单元而没有利用整个图谱的上下文信息。
为了更有效的利用图级别的知识,BERT-MK提出了在预训练模型融入知识图谱知识时,增加一个GCKE模块,同时加入训练,使得知识图谱获取entity embedding的时候考虑到了整个图谱的上下文信息,从而更好的挖掘和利用到蕴含在知识图谱中的知识。
BERT-MK模型的整体架构跟上文提到的ERNIE模型一致,ERNIE entity embedding是通过知识图谱用TransE模型直接获取的,而BERT-MK则设计了GCKE模块对entity embedding进行训练获得。
具体模型的结构和实现可以也分为两部分,第一部分用来提取蕴含在知识图谱的上下文信息,第二部分将知识图谱知识融入预训练模型中如下图Figure 3所示。

其中第二部分也就是跟ERNIE的T-ENCODER+K-ENCODER结构一样,读者可以细度ERNIE的模型介绍。对于第一部分,也就是BERT-MK的主要工作,具体分为两个步骤:
①subgraph conversion:通过如下的算法抽取知识图谱中的子图:

通过以上算法原理的得到每句输入对应的子图结构与原本的句子进行充足,生成加入了知识图谱三元组信息的一个句子序列,这个思路与K-BERT的输入改造相似,读者可以对照阅读前文对K-BERT的解说,具体实现流程可以参见下图Figure 2:

②GCKE:通过subgraph conversion对输入进行重组之后,再进入GCKE模块,这个模块由L层组成,并将最终的顶层输入连接一个triple restoration层连接输出单独计算GCKE模块的训练目标损失。
具体来说,GCKE的每一层都是Transformer-base的模型结构,也是有多头注意力机制和前向层组成,加上了残差结构。
多头注意力机制的matrix与K-BERT的visible matrix原理一样,用以适配经过知识图谱关系注入的输入重组,如下图所示,具体实现同样的可以参见K-BERT的相关解说:

经过GCKE模块的输出连接到Triple Restoration,其训练目标简单来说就是训练对应的三元组是否是valid,也是通过替换对应三元组中的entity来实现,具体可在上图右上角。
7)优点与缺点:
优点:可以看做是上文提到的第5种模型ERNIE的进一步改进版本,对于ERNIE直接用TransE获取entity的embedding,bert-mk通过GCKE模块并增加新的训练任务,通过这个模块获取更为合理的entity embedding,且GCKE模块是单独设置训练目标进行训练的,后续研究有更多改进攻坚。
缺点:模型结构复杂,训练更新成本高。
7. KG-BERT: BERT for Knowledge Graph Completion
1)论文地址:
https://arxiv.org/pdf/1909.03193.pdf
2)融入方式:output injection
3)使用的知识图谱:Wikipedia
4)是否使用知识图谱嵌套:否
5)是否在pre-training和fine-tuning阶段使用知识图谱的融入:fine-tuning
6)模型的介绍说明:
KG - BERT的作者称,KG-BERT第一项使用PLM对三元组进行建模的研究。作者采用的方法比较简单粗暴,第一种方法是直接用预训练好的BERT模型进行fine-tuning,只是fine-tuning的任务是判断三元组是否使正确的三元组组合,而模型的输入也是直接将三元组中的三个元素直接用[SEP]分隔进入BERT模型,如下图所示:

另外,除了这种方法,KG-BERT采取的另一种训练方式是只输入两个实体的描述,来预测两者的关系,如下图所示:

而作者在文中提到第二种方式相较第一种方式,在预测关系时效果更好。
7)优点与缺点:
优点:模型没有结构的变化,实现简单,符合直觉。
缺点:没有充分利用知识图谱中三元组之间相互关联的深层知识信息,可以看做是知识图谱融入预训练模型最简单的尝试。
8. (WKLM)Pretrained Encyclopedia: Weakly Supervised Knowledge-Pretrained Language Model
1)论文地址:
https://arxiv.org/pdf/1912.09637.pdf
2)融入方式:input injection + output injection
3)使用的知识图谱:Wikidata
4)是否使用知识图谱嵌套:否
5)是否在pre-training和fine-tuning阶段使用知识图谱的融入:pre-training
6)模型的介绍说明[9]:
WKLM的作者提出大规模的预训练模型通过理解非结构化的大量文本信息隐式地从真实世界中获取知识,因此可以进一步以一种强制的方式促使预训练模型关注于真实世界实体的百科知识,以便于能够更好的的自然语言中获取实体信息并且将其应用到与实体相关的NLP任务上去。
简单来说,就是在预训练时改造模型的输入和输出,将输入中出现的实体替换为同类型的另一实体,让模型任务变成判断实体是否为随机替换的,以此构造训练任务,达到知识的融入效果。
值得一提的是,这里作者所提到的弱监督的概念可以理解为训练的任务构造仅仅只需要将实体进行替换,不需要额外的标签标注,所以可以定义为弱监督。具WKLM的具体实现包括:
①数据准备:使用英文维基百科作为训练数据,文档中的实体根据维基百科中的锚链接和Wikidata(三元组知识库)的实体名来识别。即首先检索由锚链接注释的实体,然后通过字符串匹配它们在Wikidata中的名称,以检索其他提到这些实体的地方。通过此方法可以使用现成的实体链接工具,也很容易扩展至其他语料库。
②替换策略:如下图所示,进行实体替换时首先需通过Wikidata知识库确定其实体类型,并随机选取该实体类型下的其他实体替换原实体,每个实体会通过同样的方式进行10次替换,生成10个不同的负例。相邻实体不会被同时替换,以避免多个连续的负例组成了符合事实的描述。
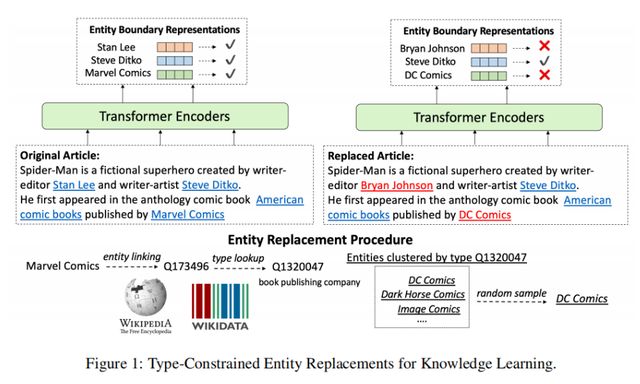
③训练目标:对于在上下文C中提到的某个实体e,我们训练模型进行正负样本预测,以指示该实体是否已被替换,计算公式如下:

7)优点与缺点:
优点:通过简单的改造预训练模型的输入输出来隐式引入知识图谱的知识,实现方式简单
缺点:仅仅利用了知识图谱中实体的信息,没有充分利用到三元组关系,可以看做是知识图谱与预训练模型的简单结合。
9. CoLAKE: Contextualized Language and Knowledge Embedding
1)论文地址:
https://arxiv.org/pdf/2010.00309.pdf
2)融入方式:input injection + architecture injection
3)使用的知识图谱:Wikipedia
4)是否使用知识图谱嵌套:否
5)是否在pre-training和fine-tuning阶段使用知识图谱的融入:pre-training
6)模型的介绍说明:
在将知识图谱融入预训练模型这个课题上,大部分研究都只考虑了知识图谱中浅层的、固态的知识表征,并且对非结构性语言的表征和结构性知识的表征是分别进行训练的,造成外部知识的潜力并没有在预训练模型中得到充分利用,没能获得更大的效能增益,也几乎没有研究探索过在融入外部知识时挖掘更多知识表征的深层上下文语境。
为解决这些问题,CoLAKE模型通过改造模型的输入和结构,沿用预训练模型的MLM目标,对语言和知识的表征同时进行同步训练。
此外,为了解决非结构化文本与知识之间的异构性冲突,CoLAKE将两者以一种统一的数据结果将两者整合起来,形成word-knowledge graph,将其作为预训练数据在改造后的Transformer encoder模型上进行预训练。
CoLAKE在结构化的、无标签的word-knowledge graphs的数据上对结合了上下文的语言和知识表征进行联合的、同步的预训练。其实现方法是先需要构造出这样WK graphs,然后对模型结构和训练目标稍作改动。具体实现如下:
①构造WK graphs:
先对输入的句子中的mention进行识别,然后通过一个entity linker找到其在特定知识图谱中对应的entity。Mention结点被替换为相应的entity,被称作anchor nodes。
以这个anchor node为中心,可以提取到多种三元组关系来形成子图,提取到的这些子图和句子中的词语,以及anchor node一起拼接起来形成WK graph,如下图 Figure 2所示。
实际上,对于每个anchor node,作者随机玄奇最多15个相邻关系和实体来构建WK graph,并且只考虑anchor node在三元组中是head的情况。
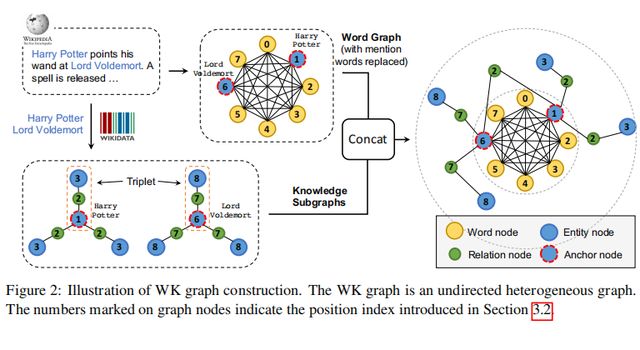
②模型结构:
接下来构建好的WK graph进入Transformer Encoder,CoLAKE对embedding层和encoder层都做了相应的改造。
Embedding Layer:输入的embedding是token embedding,type embedding和position embedding的加和。因为WK graph会将原本的句子进行充足,因此输入的句子会使一句错乱的序列,因此需要对应修正其type input和position input。
其中对于每个token,其同一对应的type会用来表征该token对应的node的类型,比如是word,entity或者是relation;对应的position也是根据WK graph赋予的。下图给出了一个具体的例子进行说明:

Masked Transformer Encoder:
利用多头注意力机制中的注意力矩阵来反映WK graph的结构。

可以看出,模型的改动就是在计算注意力矩阵的时候,对于没有关联的节点加上了负无穷,使得两者不可见,以这种方式体现出WK graph的结构。
③训练目标:
MLM是指随机的掩盖掉输入中的某些词,让模型预测掩盖掉的词是什么。而CoLAKE就是将MLM从词序列拓展到了WK graphs。
作者随机掩盖15%的节点,80%的时间用[MASK]替代,10%的时间随机替换成同类型的其他节点,10%时间不做任何改变。
通过掩盖词语,关系和实体结点,能从不同角度帮助模型更好的同时学习到语言本身和知识图谱中的知识。
同时,作者提到在预测anchor node的时候,模型可能会更容易借助知识上下文而不是语言上下,因为后者的多样性和学习难度更大。
为了规避这个问题,作者在预训练时在50%的时间里丢弃了anchor nodes的相邻节点,从而减少来自知识图谱的帮助。
7)优点与缺点:
优点:对模型结构改动小,可根据实际需求融入多种知识图谱
缺点:对结构化知识强依赖的下游任务更有效,在应对需要理解语义的下游任务时没有改进
04 未来探索方向思考
知识对于语言的理解至关重要,在语言预训练模型大行其道的当下,将知识融入语言预训练模型中是重要的技术发展方向,但知识的注入未必总是有效的。
在一些下游任务上知识图谱的融入反而有可能会扰乱预训练模型从非结构化的文本中理解到的知识体系,同时过多的知识引入也可能带来噪声,反而造成模型损失。
因此也不需要一味鼓吹魔改模型或者是设计繁复的模型结构盲目融合知识图谱。
但在不盲目的前提下,将知识图谱融入预训练模型肯定是大有可为的。
经过前文的论述,知识图谱融入的模型改进方式多种多样,不论是从模型输入,模型结构,模型输出进行融合,在一定程度上都可以提升模型在与知识导向相关的下游任务上的表现,因此后续的工作可以考虑将多种模型的改进共同作用在一个模型上,当然这也需要进一步考量各个模型改进方案之间是否存在冲突。
除了以上的一些模型介绍外,还有一些研究将知识图谱转换成自然语言作为evidence与任务输入一同进入模型,以减少知识图谱和自然语言之间的异构性冲突。
而知识图谱融入预训练模型的效果,除了融合方法的改进和尝试,知识图谱本身构建的合理性和高效性也关系到融合技术是否有效落地到实际业务中,因此在以后的研究中应当更多兼顾知识图谱本身构建的技术研究上去。
参考文献
[1] 当知识图谱遇上预训练语言模型
https://blog.csdn.net/qq_27590277/article/details/119988603
[2]终于有人把知识图谱讲明白
https://blog.csdn.net/zw0Pi8G5C1x/article/details/113930459
[3] Colon-Hernandez P , Havasi C , Alonso J , et al. Combining pre-trained language models and structured knowledge[J]. 2021.
[4]WordNet https://wordnet.princeton.edu/
[5]Hewitt, John and Christopher D Manning. 2019. A structural probe for finding syntax in word representations. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4129–4138.
[6]论文笔记《Knowledge Enhanced Contextual Word Representations》
https://blog.csdn.net/BigPig_LittleTail/article/details/104511432
[7] 【深度学习】知识图谱——K-BERT详解
https://zhuanlan.zhihu.com/p/314998122
[8] Pascal Vincent, Hugo Larochelle, Yoshua Bengio, and Pierre-Antoine Manzagol. 2008. Extracting and composing robust features with denoising autoencoders. In Proceedings of ICML, pages 1096–1103.
[9] 论文笔记 --《CoLAKE: Contextualized Language and Knowledge Embedding》
https://www.jianshu.com/p/3b5faaa691fe
[10]当知识图谱遇上预训练语言模型
https://blog.csdn.net/qq_27590277/article/details/119988603
[11]BERT遇上知识图谱:预训练模型与知识图谱相结合的研究进展
https://zhuanlan.zhihu.com/p/408088588