百度吃鸡排名预测挑战赛第六名方案(基于PyCaret)
序言
笔者参加百度吃鸡排名预测挑战赛位列第六名,现将方案给出,欢迎批评指正,如有想上车参赛的同学请私信联系,另外提供代码和模型预测文件。

比赛介绍
《绝地求生》(PUBG) 是一款战术竞技型射击类沙盒游戏。在游戏中,玩家需要在游戏地图上收集各种资源,并在不断缩小的安全区域内对抗其他玩家,让自己生存到最后。当选手在本局游戏中取得第一名后,会有一段台词出现:“大吉大利,晚上吃鸡!”。
该比赛提供了PUBG游戏数据中玩家的行为数据,希望参赛选手能够构建模型对玩家每局最终排名进行预测。
赛题数据
赛题训练集案例如下:
- 训练集5万数据,共150w行
- 测试集共5000条数据,共50w行
赛题数据文件总大小150MB,数据均为csv格式,列使用逗号分割。
测试集中label字段team_placement为空,需要选手预测。完整的数据字段含义如下:
- match_id:本局游戏的id
- team_id:本局游戏中队伍id,表示在每局游戏中队伍信息
- game_size:本局队伍数量
- party_size:本局游戏中队伍人数
- player_assists:玩家助攻数
- player_dbno:玩家击倒数
- player_dist_ride:玩家车辆行驶距离
- player_dist_walk:玩家不幸距离
- player_dmg:输出伤害值
- player_kills:玩家击杀数
- player_name:玩家名称,在训练集和测试集中全局唯一
- kill_distance_x_min:击杀另一位选手时最小的x坐标间隔
- kill_distance_x_max:击杀另一位选手时最大的x坐标间隔
- kill_distance_y_min:击杀另一位选手时最小的y坐标间隔
- kill_distance_y_max:击杀另一位选手时最大的x坐标间隔
- team_placement:队伍排名
方案解读
PyCaret是一个代码量超低的机器学习库,它有效的自动化了机器学习工作流。实现了端到端的机器学习和模型管理工具,可以成倍地加快机器学习的学习、部署和实践速度,本人使用PyCaret进行完成赛题。
由于本次任务是较为复杂的回归问题,首先选定使用XGBoost作为模型进行测试,后续我又尝试了多种模型包括Deep VM ANN CNN等,并进行了参数优化。
PyCaret的回归模块是一个有监督的机器学习模块,用于估计因变量(通常称为 "结果变量",或 "目标")和一个或多个自变量(通常称为 "特征","预测因素",或 "协变量")之间的关系。回归的目的是预测连续值,如预测销售金额、预测数量、预测温度等。它提供了几个预处理功能,通过设置功能为建模准备数据。这个模块包含了超过25个随时可用的算法和多个图来分析训练模型的性能。
这个函数初始化训练环境并创建转换管道。设置函数必须在执行任何其他函数之前调用。它需要两个强制性参数:数据和目标。所有其他的参数都是可选的。
from pycaret.datasets import get_data
data = get_data('insurance')
from pycaret.regression import *
s = setup(data, target = 'charges')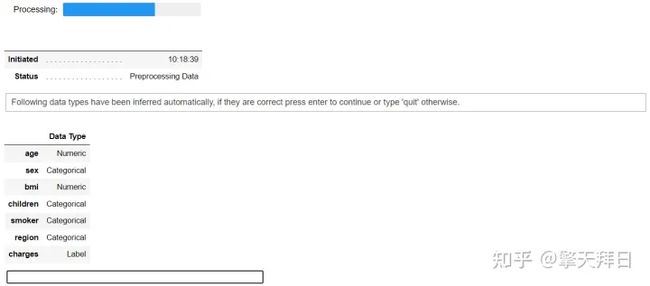
当设置被执行时,PyCaret的推理算法将根据某些属性自动推断出所有特征的数据类型。数据类型应该被正确推断出来,但情况并非总是如此。为了处理这个问题,PyCaret会显示一个提示,要求确认数据类型,一旦你执行设置。如果所有的数据类型都是正确的,你可以按回车键,或者键入退出退出设置。
另外,你也可以在设置中使用 numeric_features 和 categorical_features 参数来预先定义数据类型。

比较模型
这个函数使用交叉验证法对模型库中所有可用的估计器的性能进行训练和评估。这个函数的输出是一个带有交叉验证平均分数的评分网格。可以使用get_metrics函数访问CV期间评估的指标。可以使用add_metric和remove_metric函数添加或删除自定义指标。
best = compare_models()
print(best)
分析模型
这个函数分析训练过的模型在测试集上的表现。在某些情况下,它可能需要重新训练模型。
evaluate_model(best)
evaluate_model 只能在笔记本中使用,因为它使用了 ipywidget 。你也可以使用 plot_model 函数来单独生成图。
plot_model(best, plot = 'residuals')
plot_model(best, plot = 'feature')
预测
该函数使用训练好的模型预测Label。当数据为零时,它在测试集(在设置函数中创建)上预测标签和分数。
predict_model(best)
评估指标是在测试集上计算的。第二个输出是pd.DataFrame,包括对测试集的预测(见最后两列)。要在未见过的(新)数据集上生成标签,只需在predict_model函数中传递数据集。
predictions = predict_model(best, data=data)
predictions.head()
保存模型
save_model(best, 'my_best_pipeline')
重载模型
loaded_model = load_model('my_best_pipeline')
print(loaded_model)
结语
本文主要简略介绍个人参赛至今为止的进展和经验,想上车的小伙伴请私信联系,后续将继续更新进展和尝试更多模型参数,另外提供代码和模型预测文件。