机器学习算法_明确解释:4种机器学习算法
您是涉足机器学习的数据科学家吗? 如果是,那么您应该阅读此内容。
定义,目的,流行算法和用例-全部说明

> Photo by Andy Kelly on Unsplash
机器学习已经从科幻小说转变为成为最可靠,最多样化的业务工具,它在提高每个业务操作的多面性方面已经走了很长一段路。
它对各种业务绩效的影响变得如此重要,以至于需要实施一流的机器学习算法以确保在这个竞争激烈的世界中许多行业的生存。
将ML实施到业务运营中需要大量资源,这是战略性步骤。 因此,既然我们了解了WHY机器学习算法的重要性,那么下一步就是了解如何使用ML算法进行救援。
第一步是要清楚地了解要使用机器学习解决的业务问题,并清楚地了解不同种类的机器学习算法所需的资源和工作量,以便您能够选择 表格中众多最佳算法。
在本文中,我们将介绍机器学习算法的主要类型,解释每种算法的目的,以及它们的优点。
机器学习算法的类型
1.监督机器学习算法

监督学习算法是这四种ML算法中最简单的一种。 这些算法需要模型开发人员的直接监督。 在这种情况下,开发人员标记样本数据语料库并设置算法将在其上操作的严格边界。
这是机器学习的一version不振的版本:
· 您选择什么样的信息输出(样本)来"填充"算法
· 您确定需要哪种结果(例如"是/否"或"是/否"或"销售价值/净信用损失/房价"等)
从机器的角度来看,此过程或多或少是"连接点"例程。
监督学习的主要目的是扩展数据范围,并根据标记的样本数据对不可用,将来或看不见的数据进行预测。
监督机器学习包括两个主要过程:分类和回归。
· 分类是从过去的数据样本中学习并手动训练模型以预测本质上是二进制结果(是/否,是/否,0/1)的过程。 例如:客户是否会在未来9个月内被减员,某人是否患有癌症等。分类算法可识别某些类型的对象并将其相应分类以预测两种可能结果之一。
· 回归是识别模式并计算连续结果预测的过程。 例如:预测房价或下个月的销售预测等。
最广泛使用的监督算法是:
· 线性回归
· Logistic回归;
· 随机森林
· 梯度助推树;
· 支持向量机(SVM);
· 神经网络;
· 决策树;
· 朴素贝叶斯;
· 最近的邻居。
监督学习算法用例
这些算法最常用的领域是销售,零售贸易和股票交易中的价格预测和趋势预测。 这些算法使用传入的数据来评估可能性并计算可能的结果。
2.无监督机器学习算法

无监督学习算法不涉及开发人员的直接控制。 监督机器学习的要求的要点是,我们应该事先了解过去数据的结果,以便能够预测看不见的数据的结果,但是在无监督机器学习算法的情况下,期望的结果是未知的并且尚未定义 。
有时候,您不想完全预测结果。 您只想执行细分或聚类。 例如-一家银行可能希望对其客户进行细分以了解其行为。 此业务问题需要使用无监督的机器学习算法,因为这里没有预测到特定的结果。
两者之间的另一个大区别是,有监督的学习仅使用标记的数据,而无监督的学习则以无标签的数据为基础。
无监督机器学习算法用于:
· 探索信息的结构;
· 提取宝贵的见解;
· 检测模式;
· 将其实施到其操作中以提高效率。
换句话说,无监督机器学习试图通过筛选和理解提供给它的信息来描述信息。
无监督学习算法采用以下技术来描述数据:
· 群集:这是一种数据探索,用于根据其内部模式将其划分为有意义的组(即群集),而无需事先了解组凭据。 凭证由各个数据对象的相似性以及与其他对象的相似性(也可以用于检测异常)方面定义。
· 降维:大多数时候,传入数据中有很多噪声。 机器学习算法使用降维来消除这种噪声,同时提取相关信息。
最广泛使用的无监督算法是:
· K-均值聚类;
· t-SNE(t分布随机邻居嵌入);
· PCA(主成分分析);
· 关联规则。
无监督学习算法用例
数字营销(用于根据特定凭据识别目标受众群体-它可以是行为数据,个人数据元素,特定软件设置等)和广告技术(此算法可用于开发更有效的广告内容定位和 同样用于识别广告系列效果的模式)是采用无监督学习算法的主要行业。 它们还用于需要客户信息探索和相关服务调整的地方。
3.半监督机器学习算法

半监督学习算法代表了监督算法和非监督算法之间的中间立场。 本质上,半监督模型将两者的某些方面结合在一起成为自己的事物。
让我们了解半监督算法的工作原理:
· 半监督的机器学习算法使用一组有限的标记样本数据来确定操作的要求(即训练自身)。
· 该限制导致了部分训练的模型,该模型随后获得标记未标记数据的任务。 由于样本数据集的限制,结果被认为是伪标记数据。
· 最后,将标记和伪标记的数据集进行组合,从而创建一种独特的算法,该算法结合了监督学习和无监督学习的描述性和预测性方面。
半监督学习使用分类过程来识别数据资产,并使用聚类过程将其分组为不同的部分。
半监督学习算法用例
法律和医疗保健行业以及其他行业,借助半监督学习来管理Web内容分类,图像和语音分析。
在Web内容分类的情况下,半监督学习适用于爬网引擎和内容聚合系统。 在这两种情况下,它都使用各种各样的标签来分析内容并将其按特定配置进行排列。 但是,此过程通常需要人工输入才能进一步分类。
在图像和语音分析的情况下,算法会执行标记以基于样本语料库提供具有连贯转录的可行的图像或语音分析模型。 例如,它可以是MRI或CT扫描。 利用少量的示例性扫描,可以提供一种可以识别图像异常的相干模型。
4.强化机器学习算法

强化学习通常被理解为机器学习人工智能。
本质上,强化学习就是开发一个自我维持的系统,该系统在连续的尝试和失败序列中,会根据标记的数据组合以及与传入数据的交互来改善自身。
强化ML采用一种称为探索/开发的技术。 机制很简单-进行操作,观察结果,然后下一个操作考虑第一个操作的结果。 这是一个迭代算法。
使用此算法,机器可以训练以做出特定决策。 它是这样工作的:机器处于反复试验不断训练自身的环境中。 该机器将从过去的经验中吸取教训,并尝试捕获最佳的知识以做出准确的业务决策。
最常见的强化学习算法包括:
· Q学习
· 时间差异(TD);
· 蒙特卡洛树搜索(MCTS);
· 异步演员批判代理(A3C)。
强化学习算法用例
增强机器学习适合于可用信息有限或不一致的情况。 在这种情况下,算法可以基于与数据和相关过程的交互来形成其操作过程。
现代NPC和其他视频游戏经常使用这种类型的机器学习模型。 强化学习为AI对玩家动作的反应提供了灵活性,从而提供了可行的挑战。 例如,碰撞检测功能对移动的车辆使用这种ML算法。
自动驾驶汽车也依赖于强化学习算法。 例如,如果自动驾驶汽车(例如,Waymo)检测到向左转弯的道路-它可能会激活"向左转"场景,依此类推。
强化学习的这种变化中最著名的例子是AlphaGo,它与世界上第二好的围棋选手并驾齐驱,并通过计算当前棋盘位置上的动作序列击败了他。
另一方面,营销和广告技术部门也使用强化学习。 通过紧密适应用户的行为和周围环境,这种类型的机器学习算法可使重新定位操作更加灵活和高效,以实现转换。
此外,强化学习用于放大和调整聊天机器人的自然语言处理(NLP)和对话生成,以:
· 模仿输入消息的样式
· 制定更具吸引力,内容丰富的应对措施
· 根据用户反应找到相关的响应。
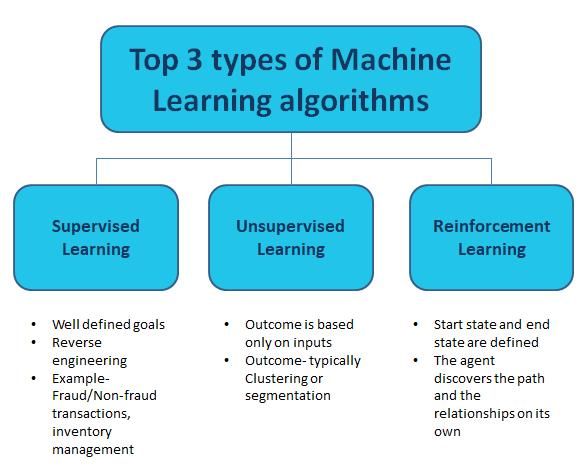
总之,要记住的最重要的ML算法类型是"监督","不受监督"和"强化"。
请继续关注此空间,以获取有关统计,数据分析和机器学习的更多信息!
(本文翻译自Juhi的文章《Clearly Explained: 4 types of Machine learning algorithms》,参考:https://towardsdatascience.com/clearly-explained-4-types-of-machine-learning-algorithms-71304380c59a)