logistic回归神经网络全流程python实现
概述
笔记来源:zergtant/pytorch-handbook
程序版本:python 3.8
数据集来源:Index of /ml/machine-learning-databases/statlog/german
数据集说明:UCI German Credit 数据集,是德国信用数据集。是根据个人的银行贷款信息和申请客户贷款逾期发生情况来预测贷款违约倾向的数据集,包含24个维度,1000条数据。
目录
- 读取数据集
- 数据归一化
- 打乱数据
- 划分训练集和测试集
- 定义网络模型
- 定义测试集上的准确率函数(可选)
- 设置网络参数(损失函数、梯度下降法)
- 训练过程
- 输出
代码实现
读取数据
首先将“german.data-numeric.data-numeric”文件下载到和程序存放位置相同的文件夹下。
通过下列代码段,实现将数据集读取并转化为 .txt 格式,并存储到变量data中。
data=np.loadtxt("german.data-numeric")数据归一化处理
将数据归一化处理,目的是使数据的分布保证在同一水平下,使输出数据更有说服力。
n,l=data.shape
for j in range(l-1):
meanVal=np.mean(data[:,j])
stdVal=np.std(data[:,j])
data[:,j]=(data[:,j]-meanVal)/stdVal在这里采用了![]() ,减掉平均值再除以标准差,是一种常用的归一化手段。
,减掉平均值再除以标准差,是一种常用的归一化手段。
打乱数据
这句函数的意思是将data数据重新打乱再排列成同尺寸的表。
np.random.shuffle(data)划分训练集测试集
这里很简单,可以看出,前900行被划成训练集,900行以后被划分成测试集,而且最后一列为标签lab数据,单独提取出来。
train_data=data[:900,:l-1]
train_lab=data[:900,l-1]-1
test_data=data[900:,:l-1]
test_lab=data[900:,l-1]-1定义模型
定义一个简单的网络,只有一个线性层。通过一个sigmoid函数进行二分类输出0或1
class LR(nn.Module):
def __init__(self):
super(LR,self).__init__()
self.fc=nn.Linear(24,2) # 由于24个维度已经固定了,所以这里写24
def forward(self,x):
out=self.fc(x)
out=torch.sigmoid(out)
return out定义测试集上的准确率(可选)
在这里定义主要是为了输出会使用得到,不是必要流程。
def test(pred,lab):
t=pred.max(-1)[1]==lab
return torch.mean(t.float())其中, t=pred.max(-1)[1]==lab 比较难理解,在这里单独进行说明。
首先 ”==“ 的优先级比 ‘=’ 高。先对pred每行求最大值,并返回了第二个值,再与传入的标签 lab 做匹配,返回true或false。
设置网络参数
net=LR()
criterion=nn.CrossEntropyLoss() # 使用CrossEntropyLoss损失
optm=torch.optim.Adam(net.parameters()) # Adam优化
epochs=1000 # 训练1000次开始训练
for i in range(epochs):
# 指定模型为训练模式,计算梯度
net.train()
# 输入值都需要转化成torch的Tensor
x=torch.from_numpy(train_data).float()
y=torch.from_numpy(train_lab).long()
y_hat=net(x)
loss=criterion(y_hat,y) # 计算损失
optm.zero_grad() # 前一步的损失清零
loss.backward() # 反向传播
optm.step() # 优化
if (i+1)%100 ==0 : # 这里我们每100次输出相关的信息
# 指定模型为计算模式
net.eval()
test_in=torch.from_numpy(test_data).float()
test_l=torch.from_numpy(test_lab).long()
test_out=net(test_in)
# 使用我们的测试函数计算准确率
accu=test(test_out,test_l)
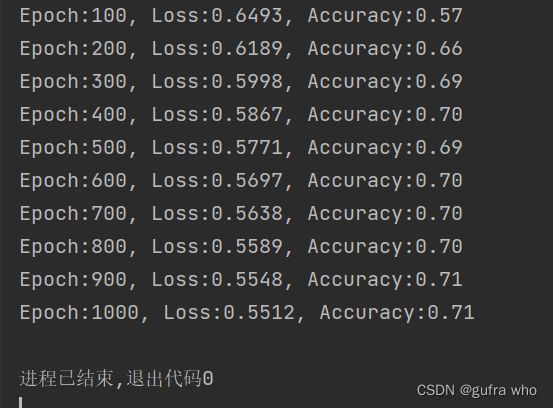
print("Epoch:{},Loss:{:.4f},Accuracy:{:.2f}".format(i+1,loss.item(),accu))先将数据格式转化为tensor格式;再输入网络,计算损失值;设置损失清零,反向传播;设置每100步输出一次,计算损失率等输出。
结果