Python操作Excel
文章目录
- xlrd模块
-
- 安装xlrd库
- 打开Excel文件读取
- 获取指定工作表
- 操作指定行
- 操作指定列
- 操作指定单元格
- 使用示例
xlrd模块
xlrd是Python处理Excel表格数据的一个模块,能够对Excel中的数据进行读取。
安装xlrd库
在命令行或终端中输入以下命令进行安装:
pip install xlrd==1.2.0
说明一下: 由于下面将以读取xlsx格式的文件来演示xlrd模块的使用,因此此处安装xlrd时指明了版本号,否则pip会默认安装最新版本的xlrd,而最新版本的xlrd删除了对xlsx格式文件的支持。
打开Excel文件读取
open_workbook函数
使用xlrd模块中的open_workbook函数可以打开指定的Excel文件。比如:
import xlrd
data = xlrd.open_workbook('D:/github/Python-code/PythonProject/test.xlsx')
如果你的Python程序和Excel文件在同级目录下,也可以通过如下方法获得Excel文件的路径:
- 先使用os.path模块中的abspath函数,获得当前Python程序所在的绝对路径。
- 再使用os.path模块中的dirname函数,获得当前Python程序所在的目录的绝对路径。
- 最后使用os.path模块中的join函数,将Python程序所在的目录路径与Excel文件的文件名进行拼接。
这时在打开Excel文件时,将拼接得到的路径传入open_workbook函数即可。比如:
import xlrd
import os
file_path = os.path.dirname(os.path.abspath(__file__))
base_path = os.path.join(file_path, 'test.xlsx')
data = xlrd.open_workbook(base_path)
说明一下: open_workbook函数返回的是一个Book对象,这个对象代表的就是打开的Excel文件。
获取指定工作表
Excel工作表
工作表指的就是Excel文件中的Sheet,一个Sheet即为一个工作表。比如:
说明一下: 获取工作表指的是获取某个Excel文件的工作表,因此下面获取工作表的函数都是Book对象的成员函数,需要使用Book对象来进行调用。
sheets函数
使用sheets函数能够获取Book对象中所有的工作表,这些工作表将会以列表的形式返回,因此可以进一步通过索引的方式获取指定的工作表。比如:
table = data.sheets()[0] # 获取Sheet1工作表
说明一下: Sheet1的索引为0,Sheet2的索引为1,以此类推。
sheet_by_index函数
使用sheet_by_index函数能够通过索引的方式获取指定的工作表。比如:
table = data.sheet_by_index(0) # 获取Sheet1工作表
说明一下: 这里的索引规则与上述索引规则相同。
sheet_by_name函数
使用sheet_by_name函数能够通过名称的方式获取指定的工作表。比如:
table = data.sheet_by_name('Sheet1') # 获取Sheet1工作表
说明一下: 上述三个函数都会返回一个Sheet对象,这个对象代表的就是获取到的工作表。
sheet_names函数
使用sheet_names函数可以获取Book对象中所有工作表的名字,这些名字将会以列表的形式返回。比如:
print(data.sheet_names()) # ['Sheet1', 'Sheet2', 'Sheet3']
sheet_loaded函数
使用sheet_loaded函数可以检查某个工作表是否导入完毕。比如:
print(data.sheet_loaded(0)) # 检查Sheet1工作表是否导入完毕
print(data.sheet_loaded('Sheet1')) # 检查Sheet1工作表是否导入完毕
说明一下: 指定工作表时可以通过索引的方式指定,也可以通过名字的方式指定。
操作指定行
操作指定行指的是操作某个Excel工作表的行,因此下面操作指定行的函数都是Sheet对象的成员函数,需要使用Sheet对象来进行调用。
nrows
nrows是Sheet对象中的一个成员变量,通过该成员变量就能获取工作表中的行数。比如:
nrows = table.nrows # 获取工作表中的行数
row函数
使用row函数可以获取工作表的指定行中所有单元格对象组成的列表。比如:
print(table.row(0)) # 获取第0行中所有单元格对象组成的列表
row_slice函数
使用row_slice函数也可以获取工作表的指定行中所有单元格对象组成的列表。比如:
print(table.row_slice(0, start_colx=0, end_colx=None)) # 获取第0行中所有单元格对象组成的列表
说明一下:
- row_slice函数的start_colx参数,表示从指定行的第start_colx列的单元格开始获取,start_colx的默认值为0,即从指定行中第0列的单元格开始获取。
- row_slice函数的end_colx参数,表示在指定行中需要被获取的最后一个单元格的下一个单元格的列下标,end_colx的默认值为None,即一直获取到最后一个单元格为止。
row_types函数
使用row_types函数可以获取工作表的指定行中所有单元格的数据类型组成的列表。比如:
print(table.row_types(0, start_colx=0, end_colx=None)) # 获取第0行中所有单元格的数据类型组成的列表
Python读取Excel单元格的内容返回以下几种类型:
| 类型 | 对应值 |
|---|---|
| XL_CELL_EMPTY | 0 |
| XL_CELL_TEXT | 1 |
| XL_CELL_NUMBER | 2 |
| XL_CELL_DATE | 3 |
| XL_CELL_BOOLEAN | 4 |
| XL_CELL_ERROR | 5 |
| XL_CELL_BLANK | 6 |
比如一个单元格中的内容是float类型的,那么row_types函数返回的列表中该单元格对应的数字就是2。
row_values函数
使用row_values函数可以获取工作表的指定行中所有单元格的数据组成的列表。比如:
print(table.row_values(0, start_colx=0, end_colx=None)) # 获取第0行中所有单元格的数据组成的列表
row_len函数
使用row_len函数可以获取工作表的指定行中有效单元格的个数
print(table.row_len(0)) # 获取第0行中有效单元格的个数
操作指定列
操作指定列指的是操作某个Excel工作表的列,因此下面操作指定列的函数也都是Sheet对象的成员函数,需要使用Sheet对象来进行调用。
ncols
ncols是Sheet对象中的一个成员变量,通过该成员变量就能获取工作表中的列数。比如:
ncols = table.ncols # 获取工作表中的列数
col函数
使用col函数可以获取工作表的指定列中所有单元格对象组成的列表。比如:
print(table.col(0)) # 获取第0列中所有单元格对象组成的列表
col_slice函数
使用col_slice函数也可以获取工作表的指定列中所有单元格对象组成的列表。比如:
print(table.col_slice(0, start_rowx=0, end_rowx=None)) # 获取第0列中所有单元格对象组成的列表
说明一下:
- col_slice函数的start_rowx参数,表示从指定列的第start_rowx行的单元格开始获取,start_rowx的默认值为0,即从指定列中第0行的单元格开始获取。
- col_slice函数的end_rowx参数,表示在指定列中需要被获取的最后一个单元格的下一个单元格的行下标,end_rowx的默认值为None,即一直获取到最后一个单元格为止。
col_types函数
使用col_types函数可以获取工作表的指定列中所有单元格的数据类型组成的列表。比如:
print(table.col_types(0, start_rowx=0, end_rowx=None)) # 获取第0列中所有单元格的数据类型组成的列表
col_values函数
使用col_values函数可以获取工作表的指定列中所有单元格的数据组成的列表。比如:
print(table.col_values(0, start_rowx=0, end_rowx=None)) # 获取第0列中所有单元格的数据组成的列表
操作指定单元格
操作指定单元格指的是操作某个Excel工作表的单元格,因此下面操作指定单元格的函数也都是Sheet对象的成员函数,需要使用Sheet对象来进行调用。
cell函数
使用cell函数可以获取工作表中指定位置的单元格对象。比如:
print(table.cell(0, 1)) # 获取第0行第1列的单元格对象
cell_type函数
使用cell_type函数可以获取工作表中指定位置单元格的数据类型。比如:
print(table.cell_type(0, 1)) # 获取第0行第1列单元格的数据类型
cell_value函数
使用cell_value函数可以获取工作表中指定位置单元格中的数据。比如:
print(table.cell_value(0, 1)) # 获取第0行第1列的单元格中的数据
使用示例
现有如下Excel表格,请求出3班数学成绩的平均分
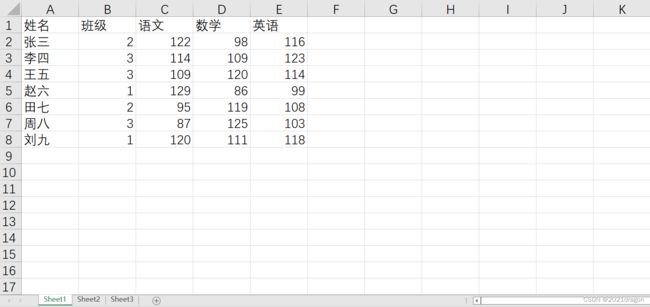
步骤如下:
- 使用open_workbook函数打开该Excel文件进行读取。
- 使用sheet_by_index函数获取Sheet1工作表。
- 通过成员变量nrows获取表格的行数。
- 使用for循环遍历表格中的每一行,通过cell_value函数判断每一行的同学是否是3班的同学,如果是则将该同学的数学成绩累加到total变量,同时用count变量同级3班同学的人数。
- 表格遍历结束后,total除以count所得到的值便是3班数学成绩的平均分。
代码如下:
import xlrd
import os
# 1.打开Excel文件读取
file_path = os.path.dirname(os.path.abspath(__file__))
base_path = os.path.join(file_path, 'test.xlsx')
data = xlrd.open_workbook(base_path)
# 2.获取指定工作表
table = data.sheet_by_index(0)
# 3.求3班数学成绩平均分
nrows = table.nrows # 获取行数
total = 0
count = 0
for i in range(1, nrows): # 遍历每一行,统计3班人数和数学成绩总和
if table.cell_value(i, 1) == 3:
total += table.cell_value(i, 3)
count += 1
print(f'3班数学成绩平均分={total/count}') # 3班数学成绩平均分=118.0
说明一下: 表格的第一行表头,遍历时无需遍历下标为0行,因此在range函数中指定的起始值为1。