基于Prompt-tuning实现情感分类
自去年来,prompt-tuning在NLP领域开始大放异彩,并随着刘鹏飞老师关于prompt的综述而广为人知。

Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing
最近笔者也是刚刚开始了解到prompt,所以想借此记录一下自己的学习过程。
我们知道,自大规模的预训练模型出现后,自然语言处理任务就开始倾向从预训练模型fine-tune而不是从0开始学习。
预训练模型采用自监督任务从海量无监督数据中获取“知识”,利用其大规模参数存储“知识”,而fine-tuning就是调整PLMs的参数,解决下游任务。
人们发现预训练与下游任务存在“gap” ,就是说我们在基于预训练模型进行下游任务时是在让预训练模型去迁就任务。而基于prompt的方法可以让任务去迁就预训练模型,将这些任务都转换为语言模型的任务,也就是完形填空(mask language model),prompt tuning被大家认为是可以广泛激发出预训练语言模型中的知识。
对prompt的仔细介绍和研究前沿现状大家可以参考刘志远老师团队的这次报告,讲的非常好,值得反复咀嚼。
BMMeetup第1期:大模型Prompt Tuning技术
那么这里需要区分的一点就是,Prompt-Oriented Fine-Tuning 与 Prompt Tuning,二者同样是将下游任务转换成Language Modeling 形式,但是在Prompt-Oriented Fine-Tuning中,预训练模型的参数是可tune的,而伴随着预训练模型的越来越大,我们理想中的 Prompt Tuning它是希望冻住预训练模型的参数,只需要调整模板或者少量参数就可以在下游任务中取得很好的效果。
当然prompt的模板设计也有很多种,Hard Prompt(Auto-Generated Hard Prompt)、Soft Prompt、Hybrid Prompt等,我们今天来实践最简单的hard prompt来实现情感分类,这种简单的prompt预训练模型的参数肯定要是可调的,我们通过它与fine tuning进行比较来看一看加入prompt的效果。
这一部分的代码参考自以下两位博主的代码,在做实验的过程中他们也细心回答了我很多问题!
Prompt进行情感分类-Pytorch实现_王小小小飞的博客-CSDN博客
基于prompt learning的情感分类示例代码_znsoft的博客-CSDN博客_情感分类代码
任务大致描述是这样的:
数据集来自Twitter 2013,数据集中有三种类别{positive, negative, neutral},在预处理过程中我们去掉neutral类型的数据。
在prompt-oriented fine-tuning的任务中,我们构造一个这样的模板"it was [MASK].sentence"将判断positive转换成完形填空预测good,将判断negative转换为完形填空预测bad。
在fine-tuning任务中,我们在预训练模型后加一层mlp,做二分类。
prompt-oriented fine-tuning任务的代码如下:
prompt-oriented fine-tuning实际上是一个多分类任务,类别是checkpoint的词表大小。
import torch
import time
from transformers import BertConfig, BertTokenizerFast, BertForMaskedLM
from transformers import get_cosine_schedule_with_warmup
import pandas as pd
from d2l import torch as d2l
import matplotlib.pyplot as plt
import matplotlib
matplotlib.use('WebAgg')
# SVG 意为可缩放矢量图形
d2l.use_svg_display()
# 定义模型
checkpoint = "bert-large-uncased"
tokenizer = BertTokenizerFast.from_pretrained(checkpoint)
config = BertConfig.from_pretrained(checkpoint)
class BERTModel(torch.nn.Module):
def __init__(self, checkpoint, config):
super(BERTModel, self).__init__()
self.bert = BertForMaskedLM.from_pretrained(checkpoint, config=config)
def forward(self, input_ids, attention_mask, token_type_ids):
outputs = self.bert(input_ids, attention_mask, token_type_ids)
logit = outputs[0]
return logit
# 构建数据集
class MyDataSet(torch.utils.data.Dataset):
def __init__(self, sentences, attention_mask, token_type_ids, label):
super(MyDataSet, self).__init__()
self.sentences = torch.tensor(sentences, dtype=torch.long)
self.attention_mask = torch.tensor(attention_mask, dtype=torch.long)
self.token_type_ids = torch.tensor(token_type_ids, dtype=torch.long)
self.label = torch.tensor(label, dtype=torch.long)
def __len__(self):
return self.sentences.shape[0]
def __getitem__(self, idx):
return self.sentences[idx], self.attention_mask[idx], self.token_type_ids[idx], self.label[idx]
# 加载数据
def load_data(file_path):
data = pd.read_csv(file_path, sep="\t", header=None, names=["sn", "polarity", "text"])
data = data[data["polarity"] != "neutral"]
yy = data["polarity"].replace({"negative":0, "positive":1,"neutral":2})
return data.values[:, 2:3].tolist(), yy.tolist()
pos_id = tokenizer.convert_tokens_to_ids("good")
neg_id = tokenizer.convert_tokens_to_ids("bad")
# 数据预处理
mask_pos = 3
prefix = "It was [MASK]. "
def preprocess_data(file_path):
x_train, y_train = load_data(file_path)
Inputid = []
Labelid = []
token_type_ids = []
attention_mask = []
for i in range(len(x_train)):
text = prefix + x_train[i][0]
encode_dict = tokenizer.encode_plus(text, max_length=60, padding="max_length", truncation=True)
input_ids = encode_dict["input_ids"]
token_type_ids.append(encode_dict["token_type_ids"])
attention_mask.append(encode_dict["attention_mask"])
label_id, input_id = input_ids[:], input_ids[:]
if y_train[i] == 0:
label_id[mask_pos] = neg_id
label_id[:mask_pos] = [-1] * len(label_id[:mask_pos])
label_id[mask_pos + 1:] = [-1] * len(label_id[mask_pos + 1:])
else:
label_id[mask_pos] = pos_id
label_id[:mask_pos] = [-1] * len(label_id[:mask_pos])
label_id[mask_pos + 1:] = [-1] * len(label_id[mask_pos + 1:])
Labelid.append(label_id)
Inputid.append(input_id)
return Inputid, Labelid, token_type_ids, attention_mask
# 构建数据集
train_batch_size = 32
test_batch_size = 32
Inputid_train,Labelid_train,typeids_train,inputnmask_train=preprocess_data("/home/cjw/PaparCode/Twitter2013/twitter-2013train-A.tsv")
Inputid_dev,Labelid_dev,typeids_dev,inputnmask_dev=preprocess_data("/home/cjw/PaparCode/Twitter2013/twitter-2013dev-A.tsv")
Inputid_test,Labelid_test,typeids_test,inputnmask_test=preprocess_data("/home/cjw/PaparCode/Twitter2013/twitter-2013test-A.tsv")
train_iter = torch.utils.data.DataLoader(MyDataSet(Inputid_train, inputnmask_train, typeids_train, Labelid_train), train_batch_size, True)
valid_iter = torch.utils.data.DataLoader(MyDataSet(Inputid_dev, inputnmask_dev, typeids_dev, Labelid_dev), train_batch_size, True)
test_iter = torch.utils.data.DataLoader(MyDataSet(Inputid_test, inputnmask_test, typeids_test, Labelid_test), test_batch_size, True)
train_len = len(Inputid_train)
test_len = len(Inputid_test)
train_loss = []
eval_loss = []
train_acc = []
eval_acc = []
# 训练函数
def train(net, train_iter, test_iter, lr, weight_decay, num_epochs, devices):
total_time = 0
net = torch.nn.DataParallel(net.to(devices[0]))
loss = torch.nn.CrossEntropyLoss(ignore_index=-1)
optimizer = torch.optim.AdamW(net.parameters(), lr=lr, weight_decay=weight_decay)
schedule = get_cosine_schedule_with_warmup(
optimizer, num_warmup_steps=len(train_iter), num_training_steps=num_epochs*len(train_iter)
)
for epoch in range(num_epochs):
start_of_epoch = time.time()
cor = 0
loss_sum = 0
net.train()
for idx,(ids,att_mask,type,y) in enumerate(train_iter):
optimizer.zero_grad()
ids, att_mask,type, y = ids.to(devices[0]), att_mask.to(devices[0]),type.to(devices[0]),y.to(devices[0])
out_train = net(ids,att_mask,type)
l = loss(out_train.view(-1, tokenizer.vocab_size), y.view(-1))
l.backward()
optimizer.step()
schedule.step()
loss_sum += l.item()
if(idx + 1) % 20 == 0:
print("Epoch {:04d} | Step {:06d}/{:06d} | Loss {:.4f} | Time {:.0f}".format(
epoch + 1, idx + 1, len(train_iter), loss_sum / (idx + 1), time.time() - start_of_epoch)
)
truelabel=y[:, mask_pos]
out_train_mask=out_train[:, mask_pos, :]
predicted=torch.max(out_train_mask,1)[1]
cor += (predicted == truelabel).sum()
cor = float(cor)
acc = float(cor /train_len)
eval_loss_sum = 0.0
net.eval()
correct_test = 0
with torch.no_grad():
for ids, att, tpe, y in test_iter:
ids, att, tpe, y = ids.to(devices[0]), att.to(devices[0]), tpe.to(devices[0]), y.to(devices[0])
out_test = net(ids , att , tpe)
loss_eval = loss(out_test.view(-1, tokenizer.vocab_size), y.view(-1))
eval_loss_sum += loss_eval.item()
ttruelabel = y[:, mask_pos]
tout_train_mask = out_test[:, mask_pos, :]
predicted_test = torch.max(tout_train_mask, 1)[1]
correct_test += (predicted_test == ttruelabel).sum()
correct_test = float(correct_test)
acc_test = float(correct_test / test_len)
if epoch % 1 == 0:
print(("epoch {}, train_loss {}, train_acc {} , eval_loss {} ,acc_test {}".format(
epoch + 1, loss_sum / (len(train_iter)), acc, eval_loss_sum / (len(test_iter)), acc_test))
)
train_loss.append(loss_sum / len(train_iter))
eval_loss.append(eval_loss_sum / len(test_iter))
train_acc.append(acc)
eval_acc.append(acc_test)
end_of_epoch = time.time()
print("epoch {} duration:".format(epoch + 1), end_of_epoch - start_of_epoch)
total_time += end_of_epoch - start_of_epoch
print("total training time: ",total_time)
# 开始训练
net = BERTModel(checkpoint, config)
num_epochs, lr, weight_decay, devices = 20, 2e-5, 1e-4, d2l.try_all_gpus()
print("baseline:",checkpoint)
print("training...")
train(net, train_iter, test_iter, lr, weight_decay, num_epochs, devices)
# 绘acc/loss曲线
epoch = []
for i in range(num_epochs):
epoch.append(i)
plt.figure()
plt.plot(epoch, train_acc, label='Train acc')
plt.plot(epoch, eval_acc, label='Test acc')
plt.title('Training and Testing accuracy')
plt.legend()
plt.xlabel('epoch')
plt.ylabel('acc')
plt.figure()
plt.plot(epoch, train_loss, label='Train loss')
plt.plot(epoch, eval_loss, label='Test loss')
plt.title('Training and Testing loss')
plt.legend()
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()fine-tuning任务的代码如下:
import torch
import time
from transformers import BertConfig, BertTokenizerFast, BertModel
from transformers import get_cosine_schedule_with_warmup
import pandas as pd
from d2l import torch as d2l
import matplotlib.pyplot as plt
import matplotlib
matplotlib.use('WebAgg')
# SVG 意为可缩放矢量图形
d2l.use_svg_display()
# 定义模型
checkpoint = "bert-large-uncased"
tokenizer = BertTokenizerFast.from_pretrained(checkpoint)
config = BertConfig.from_pretrained(checkpoint)
class BERTModel(torch.nn.Module):
def __init__(self, checkpoint, config):
super(BERTModel, self).__init__()
self.bert = BertModel.from_pretrained(checkpoint, config=config)
self.fc = torch.nn.Linear(1024, 2)
def forward(self, input_ids, attention_mask, token_type_ids):
output = self.bert(input_ids, attention_mask, token_type_ids)
logit = self.fc(output.last_hidden_state[:, 0])
logit = logit.softmax(dim=1)
return logit
# 构建数据集
class MyDataSet(torch.utils.data.Dataset):
def __init__(self, sentences, attention_mask, token_type_ids, label):
super(MyDataSet, self).__init__()
self.sentences = torch.tensor(sentences, dtype=torch.long)
self.attention_mask = torch.tensor(attention_mask, dtype=torch.long)
self.token_type_ids = torch.tensor(token_type_ids, dtype=torch.long)
self.label = torch.tensor(label, dtype=torch.long)
def __len__(self):
return self.sentences.shape[0]
def __getitem__(self, idx):
return self.sentences[idx], self.attention_mask[idx], self.token_type_ids[idx], self.label[idx]
# 加载数据
def load_data(file_path):
data = pd.read_csv(file_path, sep="\t", header=None, names=["sn", "polarity", "text"])
data = data[data["polarity"] != "neutral"]
yy = data["polarity"].replace({"negative":0, "positive":1,"neutral":2})
return data.values[:, 2:3].tolist(), yy.tolist()
# 数据预处理
def preprocess_data(file_path):
x_train, y_train = load_data(file_path)
token_type_ids = []
attention_mask = []
input_ids = []
for i in range(len(x_train)):
text = x_train[i][0]
encode_dict = tokenizer.encode_plus(text, max_length=60, padding="max_length", truncation=True)
input_ids.append(encode_dict["input_ids"])
token_type_ids.append(encode_dict["token_type_ids"])
attention_mask.append(encode_dict["attention_mask"])
return input_ids, y_train, token_type_ids, attention_mask
Inputid_train,Labelid_train,typeids_train,inputnmask_train=preprocess_data("/home/cjw/PaparCode/Twitter2013/twitter-2013train-A.tsv")
Inputid_dev,Labelid_dev,typeids_dev,inputnmask_dev=preprocess_data("/home/cjw/PaparCode/Twitter2013/twitter-2013dev-A.tsv")
Inputid_test,Labelid_test,typeids_test,inputnmask_test=preprocess_data("/home/cjw/PaparCode/Twitter2013/twitter-2013test-A.tsv")
train_batch_size = 32
test_batch_size = 32
train_iter = torch.utils.data.DataLoader(MyDataSet(Inputid_train, inputnmask_train, typeids_train, Labelid_train), train_batch_size, True)
valid_iter = torch.utils.data.DataLoader(MyDataSet(Inputid_dev, inputnmask_dev, typeids_dev, Labelid_dev), train_batch_size, True)
test_iter = torch.utils.data.DataLoader(MyDataSet(Inputid_test, inputnmask_test, typeids_test, Labelid_test), test_batch_size, True)
train_len = len(Inputid_train)
test_len = len(Inputid_test)
train_loss = []
eval_loss = []
train_acc = []
eval_acc = []
# 训练函数
def train(net, train_iter, test_iter, lr, weight_decay, num_epochs, devices):
total_time = 0
net = torch.nn.DataParallel(net.to(devices[0]))
loss = torch.nn.CrossEntropyLoss(ignore_index=-1)
optimizer = torch.optim.AdamW(net.parameters(), lr=lr, weight_decay=weight_decay)
schedule = get_cosine_schedule_with_warmup(
optimizer, num_warmup_steps=len(train_iter), num_training_steps=num_epochs*len(train_iter)
)
for epoch in range(num_epochs):
start_of_epoch = time.time()
cor = 0
loss_sum = 0
net.train()
for idx,(ids,att_mask,type,y) in enumerate(train_iter):
optimizer.zero_grad()
ids, att_mask,type, y = ids.to(devices[0]), att_mask.to(devices[0]),type.to(devices[0]),y.to(devices[0])
out_train = net(ids,att_mask,type)
l = loss(out_train, y)
l.backward()
optimizer.step()
schedule.step()
loss_sum += l.item()
if(idx + 1) % 20 == 0:
print("Epoch {:04d} | Step {:06d}/{:06d} | Loss {:.4f} | Time {:.0f}".format(
epoch + 1, idx + 1, len(train_iter), loss_sum / (idx + 1), time.time() - start_of_epoch)
)
out_train = out_train.argmax(dim=1)
cor += (out_train == y).sum()
cor = float(cor)
acc = float(cor /train_len)
eval_loss_sum = 0.0
net.eval()
correct_test = 0
with torch.no_grad():
for ids, att, tpe, y in test_iter:
ids, att, tpe, y = ids.to(devices[0]), att.to(devices[0]), tpe.to(devices[0]), y.to(devices[0])
out_test = net(ids , att , tpe)
loss_eval = loss(out_test, y)
eval_loss_sum += loss_eval.item()
out_test = out_test.argmax(dim=1)
correct_test += (out_test == y).sum()
correct_test = float(correct_test)
acc_test = float(correct_test / test_len)
if epoch % 1 == 0:
print(("epoch {}, train_loss {}, train_acc {} , eval_loss {} ,acc_test {}".format(
epoch + 1, loss_sum / (len(train_iter)), acc, eval_loss_sum / (len(test_iter)), acc_test))
)
train_loss.append(loss_sum / len(train_iter))
eval_loss.append(eval_loss_sum / len(test_iter))
train_acc.append(acc)
eval_acc.append(acc_test)
end_of_epoch = time.time()
print("epoch {} duration:".format(epoch + 1), end_of_epoch - start_of_epoch)
total_time += end_of_epoch - start_of_epoch
print("total training time: ",total_time)
# 开始训练
net = BERTModel(checkpoint, config)
num_epochs, lr, weight_decay, devices = 20, 2e-5, 1e-4, d2l.try_all_gpus()
print("baseline:",checkpoint)
print("training...")
train(net, train_iter, test_iter, lr, weight_decay, num_epochs, devices)
epoch = []
for i in range(num_epochs):
epoch.append(i)
plt.figure()
plt.plot(epoch, train_acc, label='Train acc')
plt.plot(epoch, eval_acc, label='Test acc')
plt.title('Training and Testing accuracy')
plt.legend()
plt.xlabel('epoch')
plt.ylabel('acc')
plt.figure()
plt.plot(epoch, train_loss, label='Train loss')
plt.plot(epoch, eval_loss, label='Test loss')
plt.title('Training and Testing loss')
plt.legend()
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()那么我跑的结果是这样的:
首先是在bert-base上两个模型的比较:
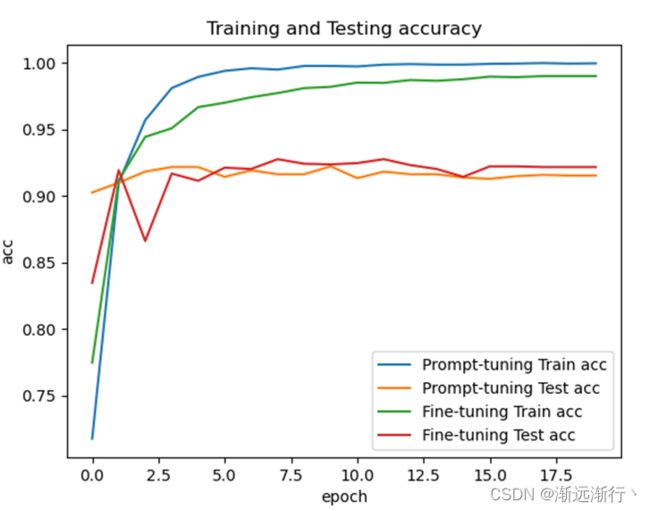
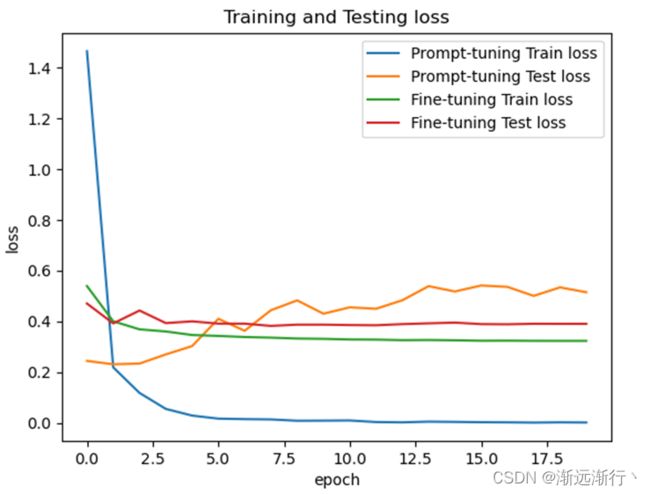
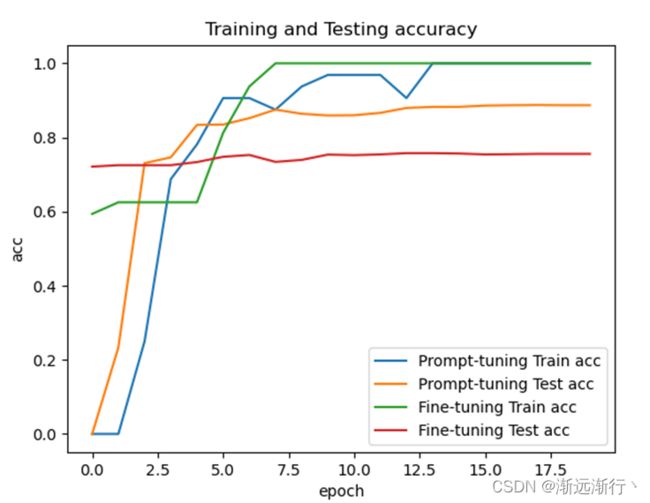
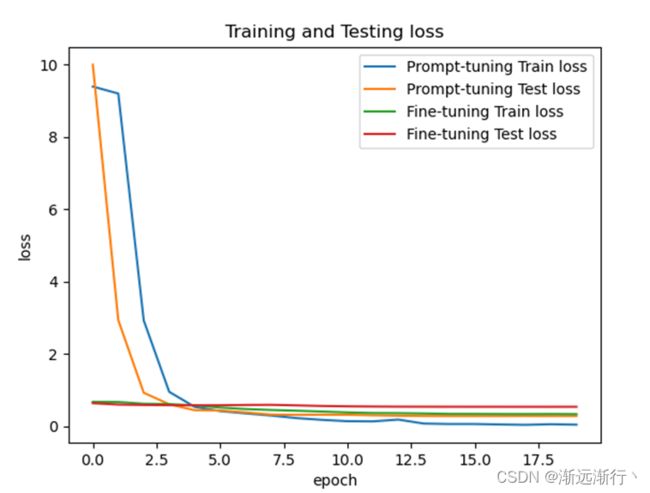
在bert-large-uncased上的比较:
接着是bert-base-uncased少次学习情况,一个batch的train_iter进行训练,拿所有测试集测试:
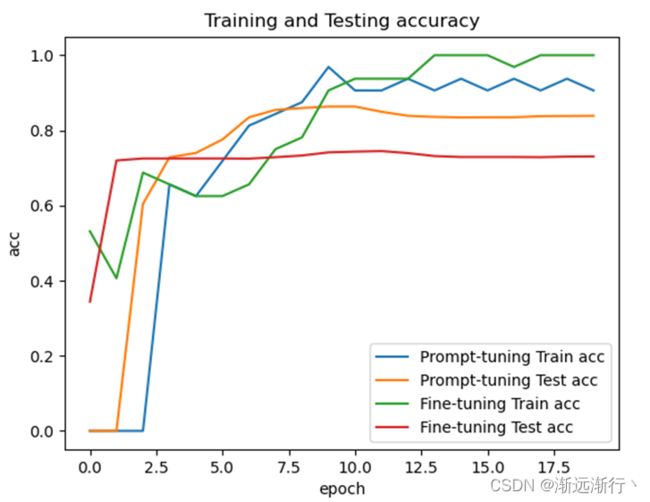
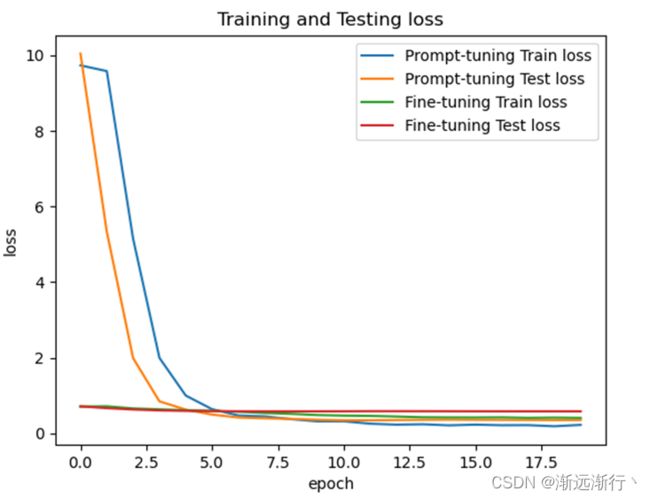
可以看到首先prompt-oriented fine-tuning收敛要更快,可以想到是因为它更贴近预训练模型,并且在测试集上的效果prompt-oriented fine-tuning要更好,并且在少次学习情景下prmpt方法明显提升大。
另外还可以看到的就是数据集相比模型太小,很容易过拟合,两个模型在扫一到两遍数据之后就可以达到几乎最好的性能。其次就是模型越大,二者的性能都会越好。