2021 Domain Adaptation(李宏毅
在前面介绍的模型中,一般我们都会假设训练资料和测试资料符合相同的分布。而如果训练资料和测试资料是来自于不同的分布,这样就会让模型在测试集上的效果很差,这种问题称为Domain shift。(域的转变)
Domain Adaptation领域自适应学习,就是将在A domain上学到的东西应用到B domain上,这个技术 也可以看作是transfer learning的其中一个环节(在A任务上学到的技能可以用到B任务上)。


Domain Shift,其实有很多种不同的类型:
模型输入的资料的分布有变化(源域黑白,目标域彩色)
输出的分布也可能有变化(源域均匀分布,目标域极端分布)
输入跟输出虽然分布可能是一样的,但它们之间的关係变了(源域中叫做“0”,目标域中叫做"1")
今天只专注在,输入资料不同的 Domain Shift 的上面。
Source Domain 是我们的训练资料,Target Domain 是我们的测试资料.
那么对于 Domain Shift的问题,具体的做法随着我们对于目标领域的了解程度不同而不同,主要有以下几种情况:
1、少量有标注的目标领域资料
处理思想:先用原始资料训练一个模型,然后用目标资料对模型进行微调,类似于BERT,只稍微跑個兩 三個(Edpa)就足夠了。
处理遇到的困难:因为target domain的资料非常少,不要跑太多iteration,否则可能會 Overfit 到 Target 的這些少量的資料上。为了避免Overfit的情况,有很多solution,比如說 把 Learning Rate 調小一點,要让微调前后模型参数不要差很多,或者让微调前后模型输入和输出的关系不要差很多,等等方法。

2、大量无标注的目标领域资料

怎麼找出這樣一個 Feature Extractor ?
其实我们可以 把一个一般的 Classifier,就分成 Feature Extractor,跟 Label Predictor 两个部分
(用 Domain Adversarial Training时,你要把一个Classifier里 哪几层当作 Feature Extractor, Label Predictor, 這個是你自己決定的 )
如何训练Feature Extractor,跟 Label Predictor?
我们把 Feature Extractor 的 Output 拿出来看,希望两个 Domain 的图片丢进去产生的 Feature,它们看起来分不出差异。

那怎么让红色和蓝色的点 分不出差异?就需要Domain Adversarial Training技术:
训练一个domain classifier,二元分类器
而 Feature Extractor 它学习的目标,就是要去想办法骗过这个 Domain Classifier,让它分辨不出来。(与Generative Adversaria Network (GAN)很相似)
(Domain Adversarial Training最早的paper是發表在 2015 年的 ICML 上面、比 Gan 還要稍微晚一點點、不過它們幾乎可以說是同時期的作品)

用 表示各个模型的参数,右边两个式子是找出能使loss最小的 ,目的是找出能让predictor和classifier分类越正确的模型参数。左边的式子就是站在predictor这边桶classifier一刀。
但是左边这个式子存在问题,本来是想用 -Ld来表示让classifier分不清向量来源。但是 -Ld不也可以用来表示误判吗,把source误判为target,
所以这未必是最好的做法,当然这招还是有用的。

刚才这整套想法,还是有一个限制,我们看下面的问题:

那我们今天训练的目标,就是要让这些正方形它的分布,跟这个圈圈三角形合起来的分布越接近越好,所以我们是不是应该要让右边的状况发生 (就是希望类对齐),而避免让左边的状况发生呢?
一个可能的想法是,我们既然知道蓝色的圈圈跟蓝色的三角形它们的分界点在哪里,那我们应该要让这些方形(虽然我们不知道它是哪一个类别),但我们让这些方形远离这一个分界点,这在文献上就有很多不同的做法。
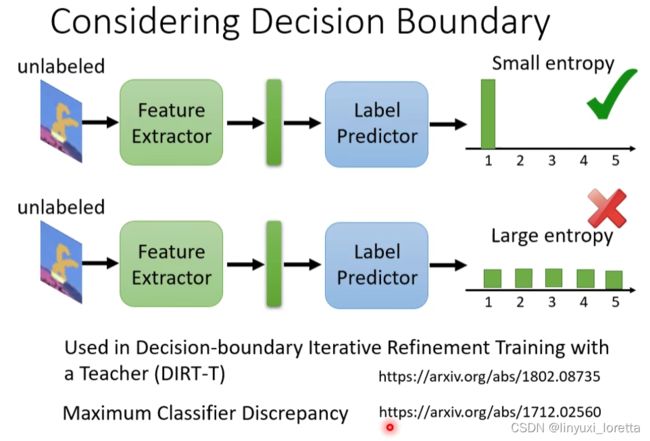
一个最简单的做法是,我有很多 Unlabeled 的图片,丢到 Feature Extractor,再丢到 Label Predictor 以后,我不知道它是哪一个类别,但是我希望它离 Boundary 越远越好
如果今天输出的结果非常地集中,叫做离 Boundary 远
如果今天输出的结果每一个类别都非常地接近,叫做离 Boundary 近
我们到目前为止,好像都假设 Source Domain 跟 Target Domain,它的类别都要是一模一样的,但是真的会如此吗?
怎麼解決 Source Domain 跟 Target Domain它可能有不一樣的 Label 的問題, 参见Universal Domain Adaptation 这篇文章。

Q&A:
如果 Feature Extractor 是 CNN而不是 Linear Layer,那 Domain Classifier Input就是feature map拉直的 Latent Embedding、這樣 Latent Space 學到的東西、把兩個 Domain 分部彌平會不會有影響、因為 Feature Map 本來就有 Space 的關係、現在卻硬是被拉直
说的很对,就是 Feature Extractor它是一個複雜的 Network、然後我們硬是要 把兩個 Domain 的東西拉在一起、會不會變成它只是為了拉在一起而拉在一起、他根本没学到我们本来希望、這個 Feature Space 學到的東西呢。
会。所以domain adaption沒有大家想像得那麼容易 Train 起來
你知道我們在 Train 的時候、有兩件事互相結抗、也就是說一方面既騙過 Domain Classifier、一方面又分類分得好、那就同時把兩個 Domain Align 在一起、同時 Latent Space我們又希望它的分布是正確的、比如說我們覺得 1 跟 7 比較像、為了要讓 Classifier 做好、那今天你的 Feature Extractor就會讓 1 跟 7 比較像、
我们期待说,藉由需要把 Label Predictor 的 Performance衝高這件事情、latent representation 裡面的這個 Space仍然是保留一個比較好的 Latent Space、但是這件事不一定總是會成功了
如果你今天你給要骗过 Domain Classifier这件事的权重太大,你的 Model 就會學到說 它都只想騙過 Domain Classifier、它就不會產生好的 Latent Space
所以实作的时候也是有些参数要调的,
3、少量无标注的目标领域资料
刚才我们是假设 Target Domain 没有 Labeled Data,但至少有一大堆数据,这个时候还可以说,我要把两个 Space 拉在一起。
但是假设目标域不只没有 Label,而且 Data 还很少,比如说我就只有一张而已,这个时候你 Target Domain 只有一张,只有一个点,根本没有办法跟 Source Domain 把他align 在一起,此时怎么办?
Testing Time Training,它的缩写是 TTT,链接在图上。
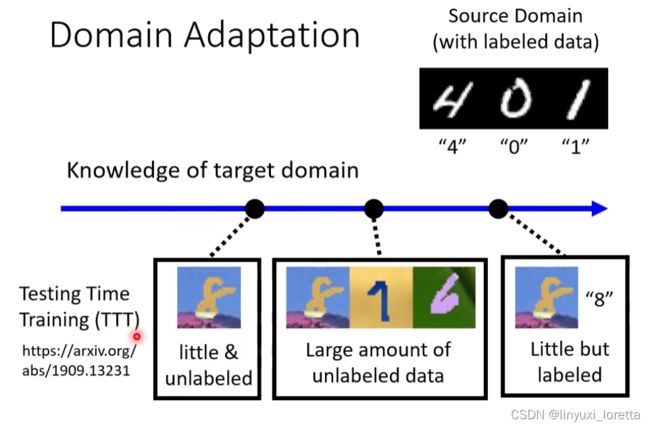
4、没有目标领域资料

其实还有一个更严峻的状况,如果我们对 Target Domain 一无所知的话,怎么办呢?
这个时候我们就不叫 Domain 的 Adaptation,通常就叫 Domain Generalization,
因为我们并不是要Adapt 到某一個特定的 Domain 上、我們對那個特定的 Domain 已經一無所知了、我们是希望机器学到Domain Generalization,在 Testing 的时候,不管来什么神奇的 Domain,它都可以处理,那 Domain Generalization,又分成两种状况:
(1)训练资料非常地丰富,本来就包含了各式各样不同的 Domain。
假设要做猫狗的分类器,那现在在训练资料里面有真实的、素描的、水彩画的猫和狗的照片。因为训练资料有多个 Domain,我们希望模型可以学到如何弥平 Domain 间的差异,如果测试资料是卡通的猫跟狗,它也可以处理。
(2)还有另外一种真的不知如何下手的状况,假设训练资料只有一个 Domain ,而测试资料有多种不同的 Domain。
在文献上也是有人试着去解惑这种问题的,在概念上就是有点像是 Data Augmentation,虽然你只有一个 Domain 的资料,想个 Data Augmentation 的方法,去产生多个 Domain 的资料,然后你就可以套上面这个方案来做做看,看能不能够在测试的时候,新的 Domain 都可以做好。
