论文阅读:GANimation: Anatomically-aware Facial Animation from a Single Image
转载请注明本文出处,谢谢。
论文链接:GANimation: Anatomically-aware Facial Animation from a Single Image

我们首先来看一下它的效果图。这张图是从左边的输入图像生成笑的表情。这里有一个可以调节的参数α,用于调节表情的变化程度。所以说他生成的表情不是离散的。像之前的一些方法只能生成离散数量的表情种类,这些表情种类是由数据集的标注决定的。笑就只有一种笑,生气就只有一种生气。这篇文章的表情的变化是可以平滑过渡的。
如果想要模型输出连续变化的结果,那么模型的输入也必须是连续的。就是说模型输入的想要得到的表情的这个条件,并不是一个离散的onehot编码的形式,而是一个连续的向量。

-
Action Unit (AU)

这篇文章用的数据集的label是由人脸各个区域的运动情况组成的。医学上会把人脸肌肉分为不同的区域,那么人脸做出表情的时候,某些区域会有不同程度的变化,比如说左边这个图,这个惊恐的表情,有这些部位会有不同程度的运动。这个数据集就是记录了人脸做各种表情的时候各个区域的变化程度。一般的表情数据集的label都是说这个人脸是什么表情,那这个数据集的label不是离散的各种表情的定义,而是用向量来表示各个区域不同程度的表情变化。通过调节表情向量就可以使这篇文章的模型输出不同程度的表情。这个向量就长下面这个样子,向量长度为N,表示脸部N个区域,每个值的范围从0到1.表示运动程度。
![]()
-
Architecture overview
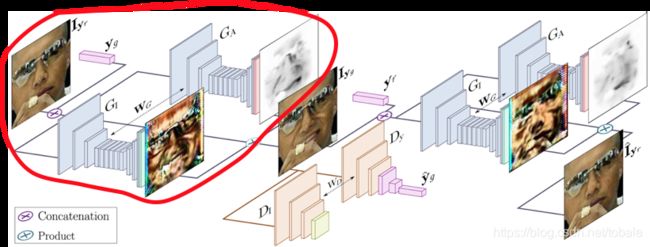
那么这个是网络结构,看起来乱糟糟的。那他其实是有两个生成器,一个判别器组成的。第一个生成器从原始输入图像生成目标表情的输出图像,第二个生成器从第一个生成器的输出图像,就是生成的目标表情的图像,来生成原始的输入图像。这有点像cyclegan,所以这个训练过程是无监督的。判别器的话是用于判断生成图像和生成的表情的质量。
现在这个用红线圈起来的是第一个生成器,他的输入是一幅图像和一个目标表情的条件,目标表情就是想要生成的表情向量。生成器有两个支路组成,一条是利用注意力机制生成的注意力掩膜A,这个注意力掩膜的作用是关注人脸,忽略背景,防止复杂的背景和光照变化产生的影响。另一条支路用于生成颜色掩膜C,就是变化后的人脸的颜色信息。把这两个输出和输入图像结合起来,就可以得到变化后的表情图像。
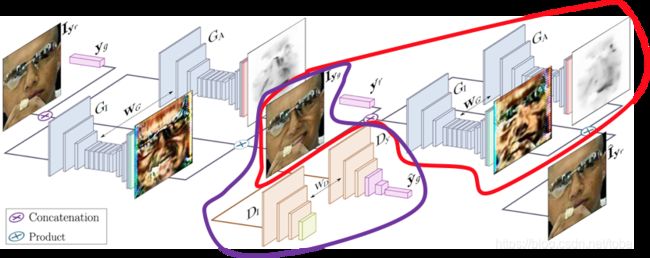
另外,还有一个生成器G,他的输入是之前的生成器的输出图像以及一个目标表情,这次的目标表情是之前生成器的输入图像的表情,就是原始图像的表情向量,这个生成器的作用就是看生成器能否恢复出原始图像。因此,这个网络是无监督训练的。
最后还有一个判别器D,判别器的输入是第一个生成器的输出图像,判别器的输出有两个,一个是对图像提取表情,还有一个是对图像提取特征,这两个都是用于判断生成图像和生成的表情的质量,计算损失。
本来流程图就乱糟糟的,再加上我画的就更乱了,我自己又重新画了一个简易版,看起来清爽一点。

-
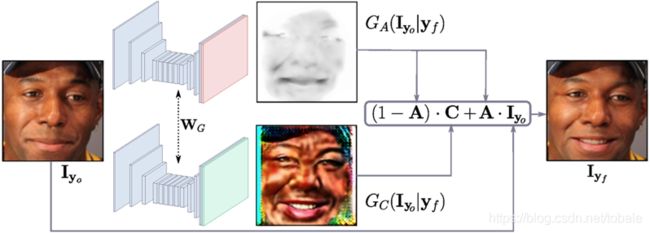
Attention-based generator
刚才说的注意力掩膜,颜色掩膜和输入图像就是这么结合的。
-
Learning the model
这个模型的损失函数一共有四项,第一项是图像对抗损失,它的作用是使生成图像的分布趋向于训练图像的分布,就是让生成的图像看起来更真实。这个损失是从WGAN改过来的,因为原始的GAN用JS散度很难训练,很容易梯度消失或者梯度爆炸。现在这个损失的意义就是最大化生成图像通过判别器得到的结果,最小化原始图像通过判别器得到的结果,另外再加入一个梯度惩罚项,让梯度控制在一定范围里。
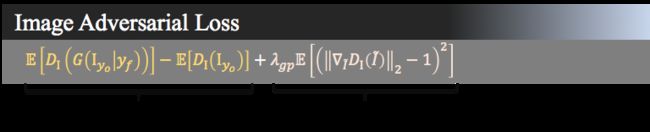
第二个损失是注意力机制的损失,因为数据集没有注意力掩膜的groundtruth,注意力掩膜就很容易过饱和,就是所有值趋向于1。注意力损失的第一项是全差分损失,全差分损失本来是用于图像的平滑,第二项是一个L2的惩罚项。

第三个损失是表情的损失,就是分别把原始图像和生成图像输入判别器,分别得到的表情和表情向量的groundtruth计算损失。

最后一项是身份损失,就是强迫第二个生成器的输出和原始图像更接近。保证生成的人脸和原始图像是同一个人。
最后总的损失就是这几个损失之和。

-
Experimental Evaluation – Single Action Units Edition
然后是实验部分,第一组实验是只让目标表情向量中的某一项有四种强度的变化,其余项保持不变,就可以观察到输出图像只有某一个区域有变化,就是说明模型真的是学习到了表情向量中的每一项对人脸某个区域的控制。

同样是这组实验,作者验证了注意力掩膜和颜色掩膜对表情向量中某一项的响应。比如说最后一个很明显,当表情向量中,眼睛区域有变化的时候,注意力掩膜和颜色掩膜都可以对这一块作出比较强烈的响应。

-
Experimental Evaluation – Simultaneous Edition of Multiple AUs
第二组实验是同时修改表情向量中的若干项,以及变化程度的参数,就可以得到一组线性插值的连续的表情变化。

-
Experimental Evaluation – Discrete Emotions Editing
第三组实验是离散表情的生成,以及和其他方法的对比。本文和其他方法最大的不同是注意力掩膜,注意力掩膜可以避免生成器对人脸以外的区域投入太多的关注,更大程度上是对人脸区域的变化,保证了图像的完整和高分辨率。

-
Experimental Evaluation – High Expression Variability
第四组实验是说明根据表情向量可以对输入图像做各种极端表情的生成。

-
Experimental Evaluation – Images in the Wild
最后一组实验说明了借助注意力掩膜,只关注人脸区域的表情变化,可以避免对人脸以外背景区域的修改,就可以很好地适应直接在图像中对表情修改,不需要其他的后处理。
