深度学习第一周 tensorflow实现mnist手写数字识别
本文为参加K同学365深度学习训练营第一周
文章目录
-
- 一、前言
- 二、电脑环境
- 三、前期准备
-
- 1、导入相关依赖项
- 2、设置GPU(我下载的tensorflow-gpu 默认使用GPU)
- 3、加载数据集
-
- 方法一、
- 方法二、
- 方法三、
- 四、数据预处理
- 五、搭建CNN网络
- 六、开始训练
- 七、绘制损失函数图像和准确度图像
- 八、保存模型
- 九、模型加载与测试
一、前言
MNIST是一个入门级的计算机视觉数据集,MNIST数据集来自美国国家标准与技术研究所, National Institute of Standards and Technology (NIST)。训练集由来自250个不同人手写的数字构成,其中50%是高中学生,50%来自人口普查局的工作人员,共计60000张。测试集也相同,共计10000张。整个数据集大小只有12M左右,包含各种尺寸是28*28的手写数字图片,此数据集是以二进制存储的。
数据集下载地址:https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz
二、电脑环境
电脑系统:Windows 10
语言环境:Python 3.8.8
编译器:Pycharm 2021.1.3
深度学习环境:TensorFlow 2.8.0,keras 2.8.0
显卡及显存:RTX 3070 8G
三、前期准备
1、导入相关依赖项
from tensorflow import keras
from keras.models import Sequential
from keras.layers import *
from keras.datasets import mnist
import numpy as np
import matplotlib.pyplot as plt
2、设置GPU(我下载的tensorflow-gpu 默认使用GPU)
只使用GPU
if gpus:
gpu0 = gpus[0] #如果有多个GPU,仅使用第0个GPU
tf.config.experimental.set_memory_growth(gpu0, True) #设置GPU显存用量按需使用
tf.config.set_visible_devices([gpu0],"GPU")
使用cpu和gpu
os.environ[“CUDA_VISIBLE_DEVICES”] = “-1”
3、加载数据集
方法一、
直接使用keras内置模块加载数据集,此时会涉及数据集的下载,因为使用的是google的相关可能会下载数据集失败
(x_train, y_train), (x_test, y_test) = mnist.load_data()
如果下载成功后数据集会保存在
C:\Users\用户名(此处填你自己的)\.keras\datasets中
如:我的C:\Users\liyuan\.keras\datasets

方法二、
如果直接加载数据集报错,数据集下载失败的话,可将链接放入迅雷中下载,下载后放到上面的文件夹中,也可以
方法三、
如果不想找上面文件夹,可使用下面代码直接加载数据集(前提已经下载好数据集)
path = "./数据集/手写数据集/mnist.npz" #数据所在路径
def load_mnist(path:str)->tuple:
with np.load(path, allow_pickle=True) as f:
x_train, y_train = f["x_train"], f["y_train"]
x_test, y_test = f["x_test"], f["y_test"]
return (x_train, y_train), (x_test, y_test)
(x_train, y_train), (x_test, y_test) = load_mnist(path=path)
print(x_train.shape) # (60000, 28, 28)
print(x_test,shape) # (10000, 28, 28)
数据展示,分别展示训练集和测试集各自的前十张图片
plt.figure(figsize=(20, 5)) # 创建一个画布,画布大小为宽20、高5(单位为英寸inch)
for i, imgs in enumerate(x_train[:10]):
# 将整个画布分成2行10列,绘制第i+1个子图。
plt.subplot(2, 10, i+1)
plt.imshow(imgs, cmap=plt.cm.binary)
plt.axis('off')
for i, imgs in enumerate(x_test[:10]):
# 将整个画布分成2行10列,绘制第i+11个子图。
plt.subplot(2, 10, i+11)
plt.imshow(imgs, cmap=plt.cm.binary)
plt.axis('off')
plt.show() #使用pycharm的需要加入这行代码才能将图像显示出来

四、数据预处理
我们需要将验证集和测数据数据增加一个维度,并将其像素从0-255划分到0-1之间减少计算量,我们还需要将标签集进行热编码处理
# 图片预处理
x_train = x_train.reshape(60000,28,28,1)/255.
x_test = x_test.reshape(10000,28,28,1)/255.
# 标签热编码
y_train = keras.utils.to_categorical(y_train)
y_test = keras.utils.to_categorical(y_test)
五、搭建CNN网络
# 网络模型
model = Sequential([
Conv2D(filters=32,kernel_size=3,activation='relu',input_shape=(28,28,1)),
MaxPool2D((2,2)),
Conv2D(filters=64,kernel_size=3,activation='relu'),
MaxPool2D((2,2)),
Flatten(),
Dense(64,activation='relu'),
Dense(10,activation='softmax') # 输出为10类别
])
# 设置优化器相关
model.compile(optimizer=keras.optimizers.SGD(learning_rate=0.01),loss=keras.losses.binary_crossentropy,metrics=['acc'])
evaluate = model.evaluate(x_test,y_test)
print(evaluate)
六、开始训练
# batch_size为一个批次送入网络的数据大小,epochs为迭代次数即,一个完整的数据集送入网络训练几次
history=model.fit(x_train,y_train,batch_size=60,epochs=10,verbose=1,validation_data=(x_test,y_test))
'''
这里设置的batch_size为60,训练集有60000个,所有要训练60000/60=1000
个batch,epochs=10所以所有数据要训练十次,verbose为是否显示下列的内
容,validation_data设置验证集
1000/1000 [==============================] - 6s 2ms/step - loss: 0.1005 - acc: 0.8818 - val_loss: 0.0369 - val_acc: 0.9552
Epoch 2/10
1000/1000 [==============================] - 2s 2ms/step - loss: 0.0305 - acc: 0.9636 - val_loss: 0.0231 - val_acc: 0.9750
Epoch 3/10
1000/1000 [==============================] - 2s 2ms/step - loss: 0.0225 - acc: 0.9739 - val_loss: 0.0195 - val_acc: 0.9782
Epoch 4/10
1000/1000 [==============================] - 2s 2ms/step - loss: 0.0187 - acc: 0.9782 - val_loss: 0.0166 - val_acc: 0.9813
Epoch 5/10
1000/1000 [==============================] - 2s 2ms/step - loss: 0.0161 - acc: 0.9818 - val_loss: 0.0149 - val_acc: 0.9835
Epoch 6/10
1000/1000 [==============================] - 2s 2ms/step - loss: 0.0144 - acc: 0.9840 - val_loss: 0.0142 - val_acc: 0.9827
Epoch 7/10
1000/1000 [==============================] - 2s 2ms/step - loss: 0.0130 - acc: 0.9854 - val_loss: 0.0141 - val_acc: 0.9841
Epoch 8/10
1000/1000 [==============================] - 2s 2ms/step - loss: 0.0119 - acc: 0.9866 - val_loss: 0.0131 - val_acc: 0.9848
Epoch 9/10
1000/1000 [==============================] - 2s 2ms/step - loss: 0.0110 - acc: 0.9877 - val_loss: 0.0123 - val_acc: 0.9851
Epoch 10/10
1000/1000 [==============================] - 2s 2ms/step - loss: 0.0102 - acc: 0.9890 - val_loss: 0.0120 - val_acc: 0.9853
313/313 [==============================] - 1s 2ms/step - loss: 0.0120 - acc: 0.9853
[0.011959183029830456, 0.9853000044822693]
'''
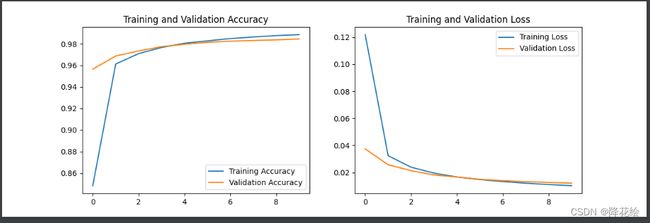
七、绘制损失函数图像和准确度图像
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(10)
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
八、保存模型
model.save('mnist2.h5') # 路径和名字
九、模型加载与测试


上两图是我在画图软件上自己写的数字
加载并验证
from tensorflow import keras
from keras.models import Sequential
from keras.layers import *
import cv2
import os
model = keras.models.load_model('mnist2.h5')
print(model.summary())
img_dataset=[]
data_path='./数据集/手写数据集/自写'
for i in os.listdir(data_path):
img_dataset.append(os.path.join(data_path,i))
for i in img_dataset:
img = cv2.imdecode(np.fromfile(i, dtype=np.uint8), 0).reshape(1,28,28,1)/255.
print(np.argmax(model.predict(img)),i)
'''
效果
2 ./数据集/手写数据集/自写\0.png
6 ./数据集/手写数据集/自写\1.png
2 ./数据集/手写数据集/自写\2.png
3 ./数据集/手写数据集/自写\3.png
4 ./数据集/手写数据集/自写\4.png
5 ./数据集/手写数据集/自写\5.png
6 ./数据集/手写数据集/自写\6.png
7 ./数据集/手写数据集/自写\7.png
8 ./数据集/手写数据集/自写\8.png
4 ./数据集/手写数据集/自写\9.png
'''
错了三个 效果还不错
这个是我的模型和自写的数字数据集
链接:https://pan.baidu.com/s/15Pw8e-5MWzXNoAQPN_PyEQ?pwd=sdxx
提取码:sdxx
