孤立森林(Isolation Forests)
简介
孤立森林是一个经典的异常检测算法,能处理大规模的多维数据。
孤立森林认为异常样本通常few and different:相比正常样本,它们数量上比较少,特征值差异比较大。因此,异常样本更容易被孤立。孤立森林通过构建二叉树的方法孤立每一个异常样本——因为异常样本容易被孤立的特征,异常样本更靠近根节点,正常样本 at the deeper end of the tree。构建的这棵树被称为孤立树(Isolation Tree, iTree)。iTrees的集合即iForest。anomalies are those instances which have short average path lengths on the iTrees。
算法原理
iForest的训练方法与超参数的选择

孤立森林将训练集通过不放回采样的方式采样得到t个子集。超参数t是iTree的个数,每棵iTree由子集构建而成。子集的大小为超参数subsampling size,通常很小,如128 。这里有下面几个问题:1. 为什么要通过随机采样得到的子集去构造iTree? 2. 超参数如何设?3. iTree是如何生成的?
为什么要通过随机采样得到的子集去构造iTree?
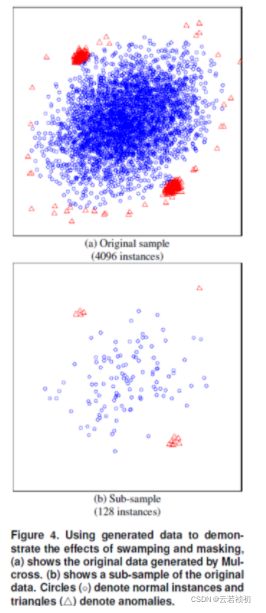
采用小样本训练模型的方法能够有效解决swamping和masking问题,如上图所示。
swamping和masking是异常检测中比较关键的问题。swamping指的是错误地将正常样本预测为异常。当正常样本很靠近异常样本时,隔离异常时需要的拆分次数会增加,使得从正常样本中区分出异常样本更加困难。masking指的是存在大量异常点隐藏了他们的本来面目。 当异常簇比较大,并且比较密集时,同样需要更多的拆分才能将他们隔离出来。上面的这两种情况使得孤立异常点变得更加困难。造成上面两种情况的原因都与数据量太大有关。孤立树的独有特点使得孤立森林能够通过子采样建立局部模型,减/小swamping和masking对模型效果的影响。其中的原因是:子采样可以控制每棵孤立树的数据量;每棵孤立树专门用来识别特定的子样本。
超参数如何设?
Sub-sampling size:when ψ increases to a desired value, iForest detects reliably and there is no need to increase further because it increases processing time and memory size without any gain in detection performance. Empirically, we find that setting to 256 generally provides enough details to perform anomaly detection across a wide range of data.
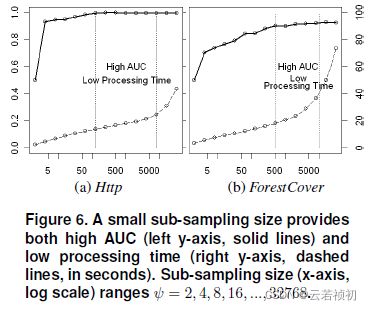
Number of tree: that path lengths usually converge well before t = 100.
iTree是如何生成的?

iTree是一棵完全二叉树,它包含2种节点:external-node with no child, or an internal-node with one test and exactly two daughter nodes (Tl,Tr). A test consists of an attribute q and a split value p such that the test q < p divides data points into Tl and Tr.
Given a sample of data X = {x1, ..., xn} of n instances from a d-variate distribution, to build an isolation tree (iTree), we recursively divide X by randomly selecting an attribute q and a split value p, until either: (i) the tree reaches a height limit, (ii) |X| = 1 or (iii) all data in X have the same values.
简而言之,二叉树的每个节点通过随机选取特征q随机选取阈值p来划分数据,直到二叉树达到限定的高度或数据无法再划分。
iForest异常检测方法
将测试数据送入iForest,可以得到每个样本的异常分数,该分数越高,则代表异常的可能性越大。计算样本的异常值的过程如下:将测试数据在iTree树上沿着对应的条件分支往下走,直到达到叶子节点,并记录这过程中经过的路径长度h(x),利用如下公式进行异常分数的计算:
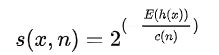
其中,
![]()
是二叉搜索树的平均路径长度,用来对结果进行归一化处理。
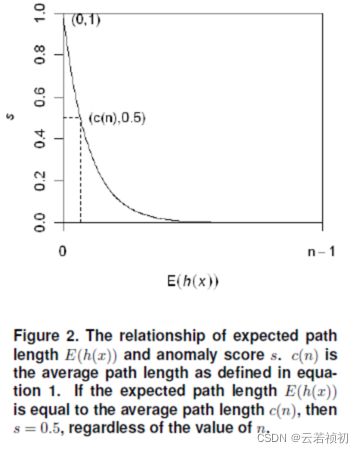
上图可以看到路径长度与异常分数的关系,如果计算出的路径长度越大,则异常分数越小。
路径长度的计算伪代码如下,就是沿着二叉树不断划分直到达到叶子节点。

这里有一个问题: 为什么随机划分样本空间时路径短的样本更可能是异常的?论文中关于此的阐述如下:
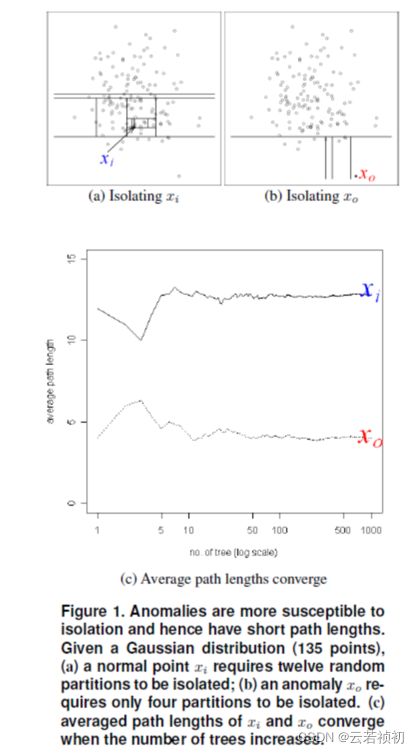
This random partitioning produces noticeable shorter paths for anomalies since (a) the fewer instances of anomalies result in a smaller number of partitions – shorter paths in a tree structure, and (b) instances with distinguishable attribute-values are more likely to be separated in early partitioning.Hence, when a forest of random trees collectively produce shorter path lengths for some particular points, then they are highly likely to be anomalies.
代码实现
sklearn.ensemble.IsolationForesthttps://scikit-learn.org/stable/modules/generated/sklearn.ensemble.IsolationForest.html#sklearn.ensemble.IsolationForest https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.IsolationForest.html#sklearn.ensemble.IsolationForest
https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.IsolationForest.html#sklearn.ensemble.IsolationForest
我的实验发现
用在一维数据上时,score和sample_size的关联很大,当sample_size小,score不准,当sample_size变大,score越来越趋近原始数据的数据分布,效果类似于给原始数据做归一化!