时间序列异常检测论文TranAD: Deep Transformer Networks for Anomaly Detection in Multivariate Time Series Data
由于工作需要,想用一下这篇论文的方法,但感觉其代码还是有很多不清除的地方,简单总结一下。
关于论文的内容介绍,可以参考:【VLDB】融合transformer和对抗学习的多变量时间序列异常检测算法TranAD论文和代码解读 - 知乎
说得比较清楚了,我就不重复了。但是读代码的时候还是有很多不明白的地方。这里以Data文件夹下的SWaT数据集为例进行分析。首先,打开train.xlsx,可以看到就是两个metrics的时间序列(ECG1和ECG2),总共有7680个时间点。在代码中是通过下列代码准备数据的:
trainD, testD = next(iter(train_loader)), next(iter(test_loader))
trainO, testO = trainD, testD
if model.name in ['Attention', 'DAGMM', 'USAD', 'MSCRED', 'CAE_M', 'GDN', 'MTAD_GAT', 'MAD_GAN'] or 'TranAD' in model.name:
trainD, testD = convert_to_windows(trainD, model), convert_to_windows(testD, model)打印一下trainD在下面这个函数调用前的shape:
torch.Size([7680, 2])可见这个是很好理解的,再打印一下调用之后的shape:
torch.Size([7680, 10, 2])10就是滑动窗口的长度,具体构建过程论文中也有写。
下面重点看一下模型训练部分:
elif 'TranAD' in model.name:
l = nn.MSELoss(reduction = 'none')
data_x = torch.DoubleTensor(data); dataset = TensorDataset(data_x, data_x)
bs = model.batch if training else len(data)
dataloader = DataLoader(dataset, batch_size = bs)
n = epoch + 1; w_size = model.n_window
l1s, l2s = [], []
if training:
for d, _ in dataloader:
local_bs = d.shape[0]
window = d.permute(1, 0, 2)
elem = window[-1, :, :].view(1, local_bs, feats)
z = model(window, elem)
l1 = l(z, elem) if not isinstance(z, tuple) else (1 / n) * l(z[0], elem) + (1 - 1/n) * l(z[1], elem)
if isinstance(z, tuple): z = z[1]
l1s.append(torch.mean(l1).item())
loss = torch.mean(l1)
optimizer.zero_grad()
loss.backward(retain_graph=True)
optimizer.step()
scheduler.step()
tqdm.write(f'Epoch {epoch},\tL1 = {np.mean(l1s)}')
return np.mean(l1s), optimizer.param_groups[0]['lr']首先注意到,这里又构建了一遍dataloader,不得不佩服这种重复工作的精神。
dataloader = DataLoader(dataset, batch_size = bs)其中bs:bs = model.batch,也就是等于128。所以,在for循环里面打印一下d的shape:
torch.Size([128, 10, 2])这也是很好理解的。让我比较费解的是下面这几条语句:
local_bs = d.shape[0]
window = d.permute(1, 0, 2)
elem = window[-1, :, :].view(1, local_bs, feats)
z = model(window, elem)为啥呢,这个window就是论文里的W?那elem是啥?
论文里介绍了一个C_t,感觉也是说得不明就里:

如果一直是到现在的时间t,那岂不是就是变长了,训练的时候该怎么做呢?
先print一下Window和elem的shape:
window:
torch.Size([10, 128, 2])
elem:
torch.Size([1, 128, 2])这个嘛,我只能说论文写得太烂了。好奇具体有什么物理意义,我写了一个小例子看看:
a=torch.Tensor([[[1,2],
[3,4],
[5,6]],
[[7,8],
[9,10],
[11,12]],
[[13,14],
[15,16],
[17,18]],
[[19,20],
[21,22],
[23,24]]]
)
print(a)
print(a.shape)
window = a.permute(1, 0, 2)
print(window)
elem = window[-1, :, :].view(1, 4, 2)
print(elem)打印出来的结果如下:
tensor([[[ 1., 2.],
[ 3., 4.],
[ 5., 6.]],
[[ 7., 8.],
[ 9., 10.],
[11., 12.]],
[[13., 14.],
[15., 16.],
[17., 18.]],
[[19., 20.],
[21., 22.],
[23., 24.]]])
torch.Size([4, 3, 2])
tensor([[[ 1., 2.],
[ 7., 8.],
[13., 14.],
[19., 20.]],
[[ 3., 4.],
[ 9., 10.],
[15., 16.],
[21., 22.]],
[[ 5., 6.],
[11., 12.],
[17., 18.],
[23., 24.]]])
tensor([[[ 5., 6.],
[11., 12.],
[17., 18.],
[23., 24.]]])看到这个例子我不明白了,上面
[1,2],
[3,4],
[5,6]可以看作是论文中的一个W_t,前面的一个d是128个W_t的集合,也就是T=128,但是permute之后的意义全变了啊,其实在我的例子里,[7,8]也就是[3,4],但是这样一来,序列长度就是128了,而且在训练的时候,感觉是用后面的metric value预测前面,这不就是leakage了吗?看到知乎上也有很多人吐槽的:
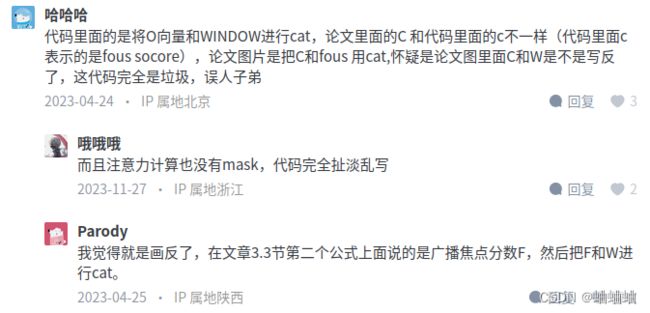
这些评论说的是对的,虽然Focus的单词都拼错了,但是确实是W和F拼接:
def encode(self, src, c, tgt):
src = torch.cat((src, c), dim=2)
src = src * math.sqrt(self.n_feats)
src = self.pos_encoder(src)
memory = self.transformer_encoder(src)
tgt = tgt.repeat(1, 1, 2)
return tgt, memory
def forward(self, src, tgt):
# Phase 1 - Without anomaly scores
c = torch.zeros_like(src)
x1 = self.fcn(self.transformer_decoder1(*self.encode(src, c, tgt)))
# Phase 2 - With anomaly scores
c = (x1 - src) ** 2
x2 = self.fcn(self.transformer_decoder2(*self.encode(src, c, tgt)))
return x1, x2这也太不靠谱了。不得不说,印度学生真的不能相信啊。我已经花了两天多在这个model上了,真是感觉不值,不得不再吐槽一句,学术界真的是太垃圾太浮躁了。