Hierarchical Attention Prototypical Networks for Few-Shot Text Classification
Abstract
目前文本分类任务的有效方法大多基于大规模的标注数据和大量的参数,但当监督训练数据少且难以收集时,这些模型就无法使用。 在本文中,我们提出了一种用于少样本文本分类的分层注意原型网络(HAPN)。 我们为我们的模型设计了特征级别、词级别和实例级别的多交叉注意力,以增强语义空间的表达能力。 我们在两个标准的基准小样本文本分类数据集——FewRel 和 CSID 上验证了我们的模型的有效性,并实现了最先进的性能。 分层注意层的可视化表明我们的模型可以分别捕获更重要的特征、单词和实例。 此外,我们的注意力机制增加了支持集的可扩展性并加快了训练阶段的收敛速度。
1 Introduction
深度学习中占主导地位的文本分类模型(Kim,2014;Zhang 等人,2015a;Yang 等人,2016;Wang 等人,2018)需要大量标记数据来学习大量参数。 然而,在只有少量数据可用的情况下,此类方法可能难以学习语义空间。 少样本学习已成为解决这一挑战的有效方法,它可以使用少量数据训练具有少量参数但性能良好的神经网络。 这种方法的一个典型例子是原型网络(Snell et al., 2017),它将少数支持实例的向量平均为类原型,并计算目标查询与每个原型之间的距离,然后将查询分类到最近的原型类。 但是,原型网络比较粗糙,没有考虑数据中各种噪声的不利影响,削弱了原型的辨别力和表现力。
在本文中,我们提出了一种分层注意原型网络,用于通过在三个层次上使用注意机制来进行小样本文本分类。 对于特征级别的注意力,我们使用卷积神经网络来获得不同类别的特征分数。 对于单词级别的注意力,我们采用注意力机制来学习实例中每个单词隐藏状态的重要性。 对于实例级多交叉注意,借助支持集和目标查询之间的多交叉注意,我们可以确定同一类中不同实例的重要性,并使模型能够得到每个类的更具判别力的原型。
在实际场景中,我们将 HAPN 应用于具有不同 character 的开放域聊天机器人的意图检测。 如果我们为老人创建一个聊天机器人,用户意图将集中在孩子、健康或期望上,因此我们可以定义具体的意图并提供相关的响应。 而且由于只需要很少的数据,我们可以快速扩展类的数量。 该模型帮助聊天机器人准确识别用户意图,使对话过程更流畅、知识更丰富、更可控。
我们的贡献主要分为三个部分:首先,我们提出了一个用于少镜头文本分类的分层注意原型网络,然后我们在 FewRel 和 CSID 数据集上实现了最先进的性能,实验证明了我们的模型更快,更可扩展。
2 Related Works
2.1 Text Classification
文本分类是自然语言处理中的一项重要任务,并且提出了许多模型来解决它。 传统方法主要关注特征工程,例如词袋或 n-gram (Wang and Manning, 2012) 或 SVMs (Tang et al., 2015)。 Kim (2014) 等基于神经网络的方法将卷积神经网络应用于句子分类。 然后,Johnson 和 Zhang (2015) 使用 one-hot word order CNN,以及 Zhang 等人(2015b) 应用字符级 CNN。 C-LSTM (Zhou et al., 2015) 结合了 CNN 和 RNN 用于句子表示和文本分类。 杨等人(2016)探索文档分类的层次结构,他们使用基于 GRU 的注意力来构建句子的表示,并使用另一个基于 GRU 的注意力将它们聚合成文档表示。 但上述监督学习方法需要大规模的标记数据,无法对看不见的类别进行分类。
2.2 Few-Shot Learning
Few-Shot Learning (FSL) 旨在通过用每个类中的少量实例训练一个分类器来解决分类问题,它可以应用于看不见的类。早期的工作旨在使用迁移学习方法,Caruana (1994) 和 Bengio (2011) 采用来自预训练模型的目标任务。然后科赫等人 (2015) 探索了一种孪生神经网络 【学习相似性】的学习方法,该方法采用独特的结构对输入之间的相似性进行排序。Vinyals 等人(2016)使用匹配网络将一个小的标记支持集和一个未标记的示例映射到它的标签,并且不需要进行微调以适应新的类类型。原型网络 (Snell et al., 2017) 【学习度量空间】通过计算每个类的查询和原型表示之间的距离并将查询分类到最近的原型类来学习模型可以在其中表现良好的度量空间。宋等人(2018)提出了一个双分支关系网络,【学习比较】它学习将查询与少量标记的样本支持数据进行比较。 Dual TriNet 结构 (Chen et al., 2018) 可以有效直接地增强多层视觉特征以提升少样本分类。但以上工作主要集中在计算机视觉领域,在NLP领域的研究和应用极为有限。 最近,Yu 等人 (2018) 提出了一种自适应度量学习方法,该方法自动从一组从元训练任务中获得的度量中确定最佳加权组合,用于新出现的小样本任务,例如意图分类,Han 等人(2018) ) 提出了一个关系分类数据集 —— FewRel,并为此采用了最新的最先进的小样本学习方法,Gao 等人 (2019) 提出了一种基于混合注意力的原型网络,用于嘈杂的小样本关系分类。 然而,这些方法没有考虑挖掘语义信息或更精确地减少噪声的影响。 而在大多数现实情况下,我们可能会逐渐增加实例的数量,因此模型容量需要更多的关注。
3 Task Definition
在few-shot文本分类任务中,我们的目标是学习一个函数:G(D, S, x) → y。 D为标注数据,我们将D分为三部分:Dtrain、Dvalidation和Dtest,每部分都有特定的标签空间。 我们使用 Dtrain 优化参数,使用 Dvalidation 选择最佳超参数,使用 Dtest 评估模型。
Vinyals 等人 (2016)提出的“episode” 训练策略已被证明是有效的。 对于每个训练 episode,我们首先从 Dtrain 中采样一个标签集 L,然后使用 L 对支持集 S 和查询集 Q 进行采样,最后将 S 和 Q 输入模型并最小化损失。 如果 L 包含 N 个不同的类,并且 S 的每个类包含 K 个实例,我们称目标问题为 N-way K-shot learning。 对于本文,我们考虑 N = 5 或 10,K = 5 或 10。
确切地说,在一个 episode 中,我们得到一个支持集 S:

由每个类 li ∈ L 的 ni 个文本实例组成,xi_j 表示它是属于类 li 的 j 个支持实例,实例 xi_j 包括 Ti,j 个词{w1, w2, . . . , wTi,j }。
那么 x 是要分类的查询集 Q 的未标记实例,y ∈ L 是经过G 的预测之后的输出标签 。
4 Method
 4.1 Model Overview
4.1 Model Overview
分层注意原型网络的整体架构如图 1 所示。我们在以下小节中介绍不同的组件:
Instance Encoder. 支持集或查询集中的每个实例将首先通过将每个单词转换为嵌入来表示为输入向量。考虑到模型的轻量级和速度,我们使用一层卷积神经网络(CNN)来实现这一部分。 为了便于比较,其细节与韩等人(2018)提出的相同。
Hierarchical Attention. 为了从稀有数据中获取更重要的信息,我们采用了分层注意机制。特征级注意力提高或降低每个类中不同特征的重要性,词级注意力突出实例意义的重要词,实例级多交叉注意力可以为不同的查询实例提取重要的支持实例,这三种注意力机制共同提高了我们模型的分类性能。
Prototypical Networks 原型网络计算一个原型向量作为每个类的表示,这个向量是属于该类的嵌入支持实例的平均向量。 我们比较所有原型向量和目标查询向量之间的距离,然后将此查询分类到最近的一个
4.2 Instance Encoder
实例编码器部分包括两层:嵌入层和实例编码层。
4.2.1 Embedding Layer
给定一个有T个词的实例x。我们使用一个嵌入矩阵W_E,w_t = W_E w_t,将每个词嵌入为向量。

其中d为单词的嵌入维数。
4.2.2 Encoding Layer
下面我们应用Zeng 等人 (2014)卷积神经网络作为编码层,通过窗口大小为 m 的卷积核获取每个单词的隐藏注释:
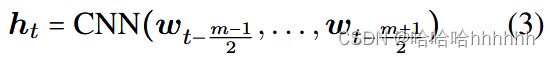
特别是,如果单词 wt 有一个位置嵌入 pt,我们应该连接 wt 和 pt
![]()
其中⊕是一个连接,ht如下

然后,我们聚合所有 ht 以获得实例 x 的整体表示

最后,我们将这两层定义为一个综合函数

该函数中的 θ 是要学习的网络参数
4.3 Prototypical Networks
原型网络 (Snell et al., 2017) 分别在小样本图像分类和小样本文本分类 (Han et al., 2018; Gao et al., 2019) 任务中取得了优异的性能,因此我们的模型基于原型网络,旨在获得推广。
原型网络的基本思想简单而高效:我们可以使用一个原型向量 ci 作为类 li 的代表特征,每个原型向量可以通过对其支持集中的所有嵌入实例进行平均来计算

然后,L 中类的概率分布可以通过 softmax 函数在所有原型向量和目标查询 q 之间的距离上产生

正如 Snell 等人(2017) 提到的,平方欧几里得距离是一个合理的选择,但是,我们将在 4.4.1 节介绍一种更有效的方法,将平方欧几里德距离与类特征分数相结合,并取得一定的改进
4.4 Hierarchical Attention
我们在这项工作中专注于句子级别的文本分类。所提出的模型得到一个特征分数向量并将每个类的支持集转换为向量表示,我们在此基础上构建一个分类器来执行小样本文本分类。
4.4.1 Feature Level Attention
4.4.2 Word Level Attention
4.4.3 Instance Level Multi Cross Attention
之前的原型网络使用支持实例的平均向量作为类原型。 由于支持实例的多样性和缺乏,每个支持向量和原型之间的差距可能很大,同时,不同的查询实例可以用多种方式表示,因此当支持集中的每个实例面对目标查询实例时,它们对类原型的贡献并不相同。 为了突出支持实例的重要性,支持实例是正确分类查询实例的有用线索,我们提出了一种多交叉注意机制。
给定类 li 的支持集 S′i ∈ Rni×d 和查询向量 q′∈ Rd,它们都通过实例编码器和词级注意力进行编码。 对查询 q′,我们认为 S′i 中的每个支持向量 sji 都有自己的权重 βji 。 所以公式(8)将改写为

其中我们定义 rji = βji sji 为加权原型向量,βji 的定义如下

其中 fφ 是一个线性层,|⋅|是 element-wise 绝对值,⊙ 是 element-wise 乘积,我们使用这两个操作得到 sji 和 q’ 之间的差异信息 τ 1 和 τ 2 ,然后将它们连接起来 都作为多交叉注意力信息mca,则fφ(·)是一个线性层,σ(·)是一个tanh激活函数,sum{·}表示向量中所有元素的求和运算。 最后,γji 是支持集 si 中 j 个实例的权重,我们使用 softmax 函数将其归一化为 βji。
通过多交叉注意力机制,原型可以更加关注那些与查询相关的支持实例,提高支持集的capacity(容量or 能力?)。