数据分析案例 |【01】电影数据分析
文章目录
-
-
-
- 一、准备数据
- 二、数据分析小题目
- 三、开始分析问题
- 四、完整代码
-
-
一、准备数据
电影数据 提取码:nxi7
二、数据分析小题目
- 获取评分的平均分
- 获取导演数量
- 呈现Rating、Runtime的分布情况
- 对电影进行分类统计genre
三、开始分析问题
首先使用
pandas中的read_csv读取表格中的数据。
data = pd.read_csv('./IMDB-Movie-Data.csv')
data.head(20)
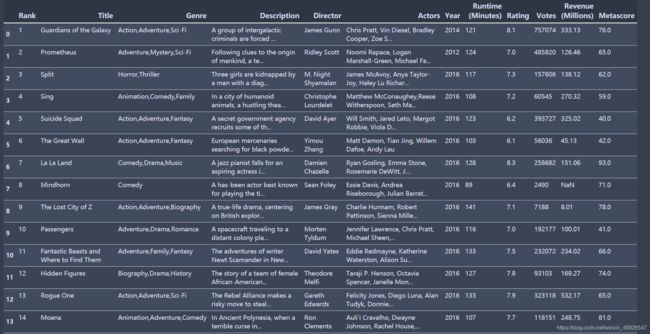
- 获取评分中的平均分
可知,
rating这个一列就是评分的数据,题中要求评分的平均分。
"""一、获取评分的平均分
result ==> 6.72
"""
score = data['Rating'].mean() // 在这里直接取出这个列的值,在通过mean求均值即可。
print(round(score, 2)) // 使用round函数对结果保留两位小数
- 获取导演数量
可直接读取导演这一列数据,但需要考虑一点不同电影的导演可能是同一个。所有最后要在对导演进行去重操作。在
numpy中可直接.unique()即可去重。
"""二、获取导演数量
1、取出所有的列
2、需要去重
result ==> 644
"""
data['Director'].unique().shape[0]
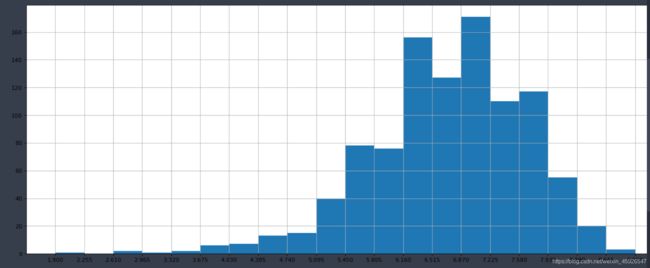
- 呈现Rating、Runtime的分布情况
"""三、呈现Rating、Runtime的分布情况
1、取出数据
2、将数据进行分割成20组来确定x轴刻度
"""
plt.figure(figsize=(20, 8), dpi=80) # 创建画布
temp = data['Rating'].values # 取值
plt.hist(temp, bins=20) # 绘制图像
x = np.linspace(temp.min(), temp.max(), 21) # 在最大值和最小值中切片取出21个值
plt.xticks(x) # 加入x轴坐标
plt.grid() # 加入网格
plt.show()
- 对电影进行分类统计genre
"""四、对电影进行分类统计genre
1、将改列取出,并取出所有的类别进行去重,获取类别
2、重新创建一个建表以类别为列索引
3、对改表进行赋值操作
4、在进行求和排序
"""
temp_list = [i.split(',') for i in data["Genre"]] # 将每一部电影的类型都切割成数组
columns = set([j for i in temp_list for j in i]) # 取出所有类型,并去重
zero_df = pd.DataFrame(np.zeros([data.shape[0], len(columns)]), columns=columns, dtype="int64") # 重新构建为0的数组
for i in range(data.shape[0]):
zero_df.loc[i, temp_list[i]] = 1 # 遍历每一部电影的类型
x = zero_df.sum().sort_values()# 求和排序
x_list = range(len(index)) # x轴个数
index = x.index # x轴标签
plt.figure(figsize=(20, 8), dpi=80) # 设置画布
rects = plt.bar(x_list,x, width=0.5)
# 配置标签
plt.xticks(x_list, index, rotation=45, fontsize=20)
plt.yticks(range(min(x),max(x),50), fontsize=20)
# 设置每个条行的值
for rect in rects:
height = rect.get_height()
plt.text(rect.get_x() + rect.get_width() / 2, height+1, str(height), ha='center',fontsize=20)
plt.show()

本次是一个小习题,在初步学习了
pandas、numpy、matplotlib的同学们可以练习一下这道题,来提升一下自己对这几个模块的掌握程度。图形绘制在练习完上面的,可以自己在使用一下其他绘制方法,绘制成其他图形看看效果如何,来提升自己的能力。
四、完整代码
import as pd
import numpy as np
from matplotlib import pyplot as plt
"""一、获取评分的平均分
result ==> 6.72
"""
score = data['Rating'].mean()
print(round(score, 2))
"""二、获取导演数量
1、取出所有的列
2、需要去重
result ==> 644
"""
num = data['Director'].unique().shape[0]
print(num)
"""三、呈现Rating、Runtime的分布情况
1、取出数据
2、将数据进行分割成20组来确定x轴刻度
"""
plt.figure(figsize=(20, 8), dpi=80) # 创建画布
temp = data['Rating'].values # 取值
plt.hist(temp, bins=20) # 绘制图像
x = np.linspace(temp.min(), temp.max(), 21) # 在最大值和最小值中切片取出21个值
plt.xticks(x) # 加入x轴坐标
plt.grid() # 加入网格
plt.show()
"""四、对电影进行分类统计genre
1、将改列取出,并取出所有的类别进行去重,获取类别
2、重新创建一个建表以类别为列索引
3、对改表进行赋值操作
4、在进行求和排序
"""
temp_list = [i.split(',') for i in data["Genre"]] # 将每一部电影的类型都切割成数组
columns = set([j for i in temp_list for j in i]) # 取出所有类型,并去重
zero_df = pd.DataFrame(np.zeros([data.shape[0], len(columns)]), columns=columns, dtype="int64") # 重新构建为0的数组
for i in range(data.shape[0]):
zero_df.loc[i, temp_list[i]] = 1 # 遍历每一部电影的类型
x = zero_df.sum().sort_values()# 求和排序
x_list = range(len(index)) # x轴个数
index = x.index # x轴标签
plt.figure(figsize=(20, 8), dpi=80) # 设置画布
rects = plt.bar(x_list,x, width=0.5)
# 配置标签
plt.xticks(x_list, index, rotation=45, fontsize=20)
plt.yticks(range(min(x),max(x),50), fontsize=20)
# 设置每个条行的值
for rect in rects:
height = rect.get_height()
plt.text(rect.get_x() + rect.get_width() / 2, height+1, str(height), ha='center',fontsize=20)
plt.show()