Pytorch 深度学习实践 第9讲--刘二大人
B站 刘二大人 ,传送门PyTorch深度学习实践——多分类问题
说明: 1、softmax的输入不需要再做非线性变换,也就是说softmax之前不再需要激活函数(relu)。softmax两个作用,如果在进行softmax前的input有负数,通过指数变换,得到正数。所有类的概率求和为1。
2、y的标签编码方式是one-hot。我对one-hot的理解是只有一位是1,其他位为0。(但是标签的one-hot编码是算法完成的,算法的输入仍为原始标签)
3、多分类问题,标签y的类型是LongTensor。比如说0-9分类问题,如果y = torch.LongTensor([3]),对应的one-hot是[0,0,0,1,0,0,0,0,0,0].(这里要注意,如果使用了one-hot,标签y的类型是LongTensor,糖尿病数据集中的target的类型是FloatTensor)
4、CrossEntropyLoss <==> LogSoftmax + NLLLoss。也就是说使用CrossEntropyLoss最后一层(线性层)是不需要做其他变化的;使用NLLLoss之前,需要对最后一层(线性层)先进行SoftMax处理,再进行log操作。
代码说明:1、第8讲 from torch.utils.data import Dataset,第9讲 from torchvision import datasets。该datasets里面init,getitem,len魔法函数已实现。
2、torch.max的返回值有两个,第一个是每一行的最大值是多少,第二个是每一行最大值的下标(索引)是多少。
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
# prepare dataset
batch_size = 64
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))]) # 归一化,均值和方差
train_dataset = datasets.MNIST(root='../dataset/mnist/', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_dataset = datasets.MNIST(root='../dataset/mnist/', train=False, download=True, transform=transform)
test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size)
# design model using class
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.l1 = torch.nn.Linear(784, 512)
self.l2 = torch.nn.Linear(512, 256)
self.l3 = torch.nn.Linear(256, 128)
self.l4 = torch.nn.Linear(128, 64)
self.l5 = torch.nn.Linear(64, 10)
def forward(self, x):
x = x.view(-1, 784) # -1其实就是自动获取mini_batch
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = F.relu(self.l3(x))
x = F.relu(self.l4(x))
return self.l5(x) # 最后一层不做激活,不进行非线性变换
model = Net()
# construct loss and optimizer
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
# training cycle forward, backward, update
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
# 获得一个批次的数据和标签
inputs, target = data
optimizer.zero_grad()
# 获得模型预测结果(64, 10)
outputs = model(inputs)
# 交叉熵代价函数outputs(64,10),target(64)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d, %5d] loss: %.3f' % (epoch+1, batch_idx+1, running_loss/300))
running_loss = 0.0
def test():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1) # dim = 1 列是第0个维度,行是第1个维度
total += labels.size(0)
correct += (predicted == labels).sum().item() # 张量之间的比较运算
print('accuracy on test set: %d %% ' % (100*correct/total))
if __name__ == '__main__':
for epoch in range(10):
train(epoch)
test()下采样过程(Subsampling)
下采样的目的是减少特征图像的数据量,降低运算需求。在下采样过程中,通道数(Channel)保持不变,图像的宽度和高度发生改变。
全连接层(Fully Connected)
先将原先多维的卷积结果通过全连接层转为一维的向量,再通过多层全连接层将原向量转变为可供输出的向量。
在前文的卷积过程与下采样过程,实际上是一种特征提取的手段或者过程,真正用于分类的过程是后续的全连接层。
============================================================================
卷积原理分析
卷积原理
单通道卷积
需要从原始数据的左上角开始依次选取与核的规格相同的输入数据进行数乘操作,并将求得的数值作为一个Output值进行填充。
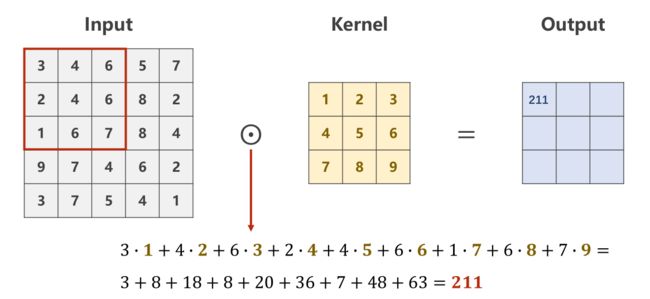
单通道卷积过程示例
Patch在原图上进行滑动时,每次只滑动一个像素,即包含重复计算的部分
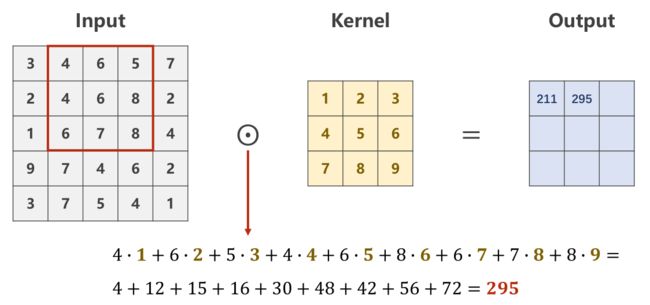
单通道卷积patch的滑动
最后求得的Output的像素矩阵,即是对原图像,在设定的卷积核下的卷积结果,是一个规格为如下的图像。
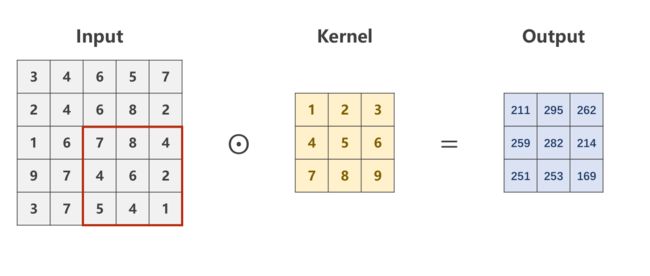
单通道卷积结果
多通道卷积
对于多通道图像,每一个通道是一个单通道的图像都要有一个自己的卷积核来进行卷积。

多通道卷积过程
对于分别求出来的矩阵,需要再次进行求和才能得到最后的输出矩阵,最终的输出矩阵仍然是一个如下所示的图像。

多通道卷积结果
将平面的图像转为立体的角度即如下图
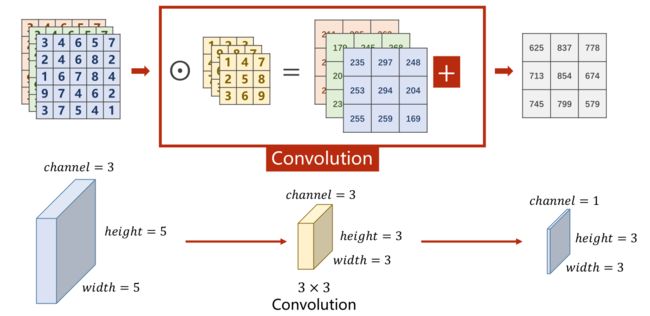
3通道卷积示例图
改进多通道
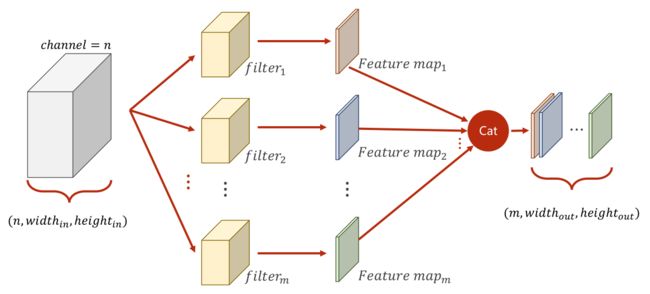
改进多通道示图
总结及代码
-
每个卷积核的通道数与原输入图像通道数一致
-
卷积核的个数决定输出通道数
-
卷积核的大小与图像大小无关
-
若卷积核大小3x3,则经卷积之后图像宽高均 -2(无Padding);若想保持图像宽高不变,则需要边缘填充,kernel_size=3,则Padding=1 ; kernel_size=5,则Padding=2;
-
以上一条,即 Padding = kernel_size / 2 [进行整除操作]
上述中所提到的卷积核,是指的多通道的卷积核,而非前文中提到的二维的。
综上所述
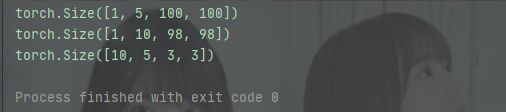
import torch
in_channels, out_channels = 5, 10
width, height = 100, 100
kernel_size = 3 #默认转为3*3,最好用奇数正方形
#在pytorch中的数据处理都是通过batch来实现的
#因此对于C*W*H的三个维度图像,在代码中实际上是一个B(batch)*C*W*H的四个维度的图像
batch_size = 1
#生成一个四维的随机数
input = torch.randn(batch_size, in_channels, width, height)
#Conv2d需要设定,输入输出的通道数以及卷积核尺寸
conv_layer = torch.nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size)
output = conv_layer(input)
print(input.shape)
print(output.shape)
print(conv_layer.weight.shape)代码结果