ECCV 2022|DynamicDepth:动态场景下的多帧自监督深度估计
前言:本文别名DynamicDepth (github),如本文的名字所示,本文着重处理的就是动态场景下的多帧自监督深度估计问题。因为MVS在动态场景下会失效,所以在动态区域的多帧深度并不可靠。现在的已有方法例如ManyDepth,利用teacher-student网络结构,让多帧部分的网络在不可信区域向单帧部分的网络学习,但是所谓不可信区域的判断准则仅仅是依靠多帧深度和单帧深度的差异来计算的,不一定准确。所以DynamicDepth提出的核心论点就是显示地构建动态区域的优化。
文章目录
-
- 解决的问题
- 基本流程
- 实施细节
-
- 动态物体解耦(DOMD)
- 遮挡感知成本量
- 训练细节
- 总结
- 参考资料

会议/期刊:2022ECCV
论文题目:《Disentangling Object Motion and Occlusion for Unsupervised Multi-frame Monocular Depth》
论文链接:Disentangling Object Motion and Occlusion for Unsupervised Multi-frame Monocular Depth
开源代码:AutoAILab/DynamicDepth(github.com)
YouTube:[ECCV 2022] Disentangling Object Motion and Occlusion for Unsupervised Multi-frame Monocular Depth - YouTube
解决的问题
先前的工作都是存在以下缺陷:
- 针对运动物体,都是在损失函数水平上解决不匹配问题,而不能利用运动物体的帧间关系推导出几何关系
- 并未解决物体运动引起的遮挡问题
- 运动方向估计网络(我认为是指光流法)增加模型复杂性,不适用于柔性目标

基本流程
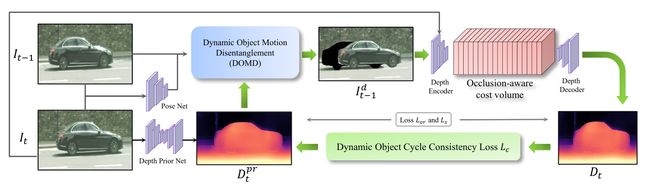
- 首先使用一个深度先验估计网络(Depth Prior Net)输出深度图 D t p r D^{pr}_{t} Dtpr,姿态估计网络(Pose Net)输出帧间运动关系
- 将2个结果输入DOMD模块中,解决物体运动引起的不匹配问题,得到运动物体被解耦的帧 I t − 1 d I^{d}_{t-1} It−1d
- I t − 1 d I^d_{t-1} It−1d、 I t I_t It 会进入到遮挡感知模块,用于解决遮挡问题,得到预测出的深度图 D t D_t Dt
- 在训练的时候,动态物体周期一致损失将使得深度图先验 D t D_t Dt 和深度图预测结果 D t p r D^{pr}_{t} Dtpr 互相提高
实施细节
动态物体解耦(DOMD)
首先我们来回顾一下动态场景会对多帧深度学习造成什么样的影响?
如下图所示,在MVS的静态假设下,我们认为被拍摄的物体没有移动。从 t 时刻和 t−1 时刻观察该物体,他们的位置都在 W ′ W^′ W′(两条线相交于一点),因此他们在图象上的对应区域是 C t C_t Ct 和 C t − 1 C_{t−1} Ct−1 。但是在实际场景中,物体已经从 W t − 1 W_{t−1} Wt−1 移动到 W t W_t Wt ,在图像上匹配的区域应该是 C t − 1 d C_{t−1}^d Ct−1d 和 C t C_t Ct 。
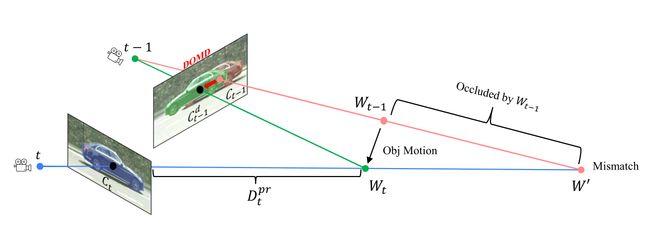
用动画来表示:
为了避免这种匹配错误,本文提出的DOMD模块先利用预训练的分割网络分割出人,车等动态区域,得到分割掩码 ( S t − 1 , S t ) (S_{t−1}, S_t) (St−1,St),和两帧图片 ( I t − 1 , I t ) (I_{t−1}, I_t) (It−1,It) 作为输入,生成解耦后的图片 I t − 1 d I_{t-1}^d It−1d
M o : ( I t , I t − 1 , S t − 1 , S t ) ↦ I t − 1 d \mathrm{M}_{\mathrm{o}}:\left(I_{t}, I_{t-1}, S_{t-1}, S_{t}\right) \mapsto I_{t-1}^{d} Mo:(It,It−1,St−1,St)↦It−1d
具体来说,我们首先使用单帧深度先验网络 θ D P N θ_{DPN} θDPN 来预测初始深度先验 D t p r D^{pr}_t Dtpr , D t p r D^{pr}_t Dtpr用于将 C t C_t Ct 重投影到 C t − 1 d C^{d}_{t-1} Ct−1d , C t − 1 d C^{d}_{t-1} Ct−1d表示 t-1 时刻相机看 W t W_t Wt点的像素块。最后,得到 I t − 1 d I_{t-1}^d It−1d。该过程用公式可以表达如下, p i t − 1 pi_{t-1} pit−1 表示映射关系:
C a = I a ⋅ S a , C t − 1 d = π t − 1 ( π t − 1 ( C t , D t p r ) ) , I t − 1 d = I t − 1 ( C t − 1 → C t − 1 d ) C_{a}=I_{a} \cdot S_{a}, \quad C_{t-1}^{d}=\pi_{t-1}\left(\pi_{t}^{-1}\left(C_{t}, D_{t}^{p r}\right)\right), \quad I_{t-1}^{d}=I_{t-1}\left(C_{t-1} \rightarrow C_{t-1}^{d}\right) Ca=Ia⋅Sa,Ct−1d=πt−1(πt−1(Ct,Dtpr)),It−1d=It−1(Ct−1→Ct−1d)
这个过程有点像crop-粘贴的操作,其结果是,t时刻帧不再有动态物体
该过程如下所示:
遮挡感知成本量
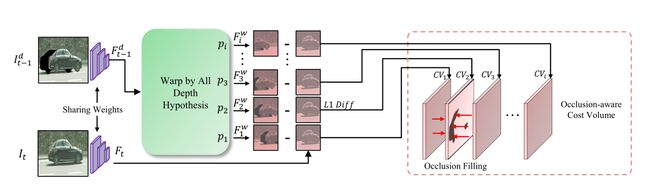
在DOMD进行crop-粘贴的操作之后,图片中已不存在动态物体,但是新的问题又出现了,那就是遮挡区域,如下图的输入部分,我们可以看到crop后的部分区域是黑色的,因为该部分实际被遮挡了,因此本文在构建cost volume的时候需要考虑到被遮挡的情况。如上图所示,被遮挡部分的特征被临近部分的数据所填充,这样可以促进训练的梯度流向附近的non-occluded区域。
cost values的公式计算:
C V i = ∣ F t − F i w ∣ 1 , F i w = π t ( π t − 1 − 1 ( F t − 1 d , p i ) ) C V_{i}=\left|F_{t}-F_{i}^{w}\right|_{1}, \quad F_{i}^{w}=\pi_{t}\left(\pi_{t-1}^{-1}\left(F_{t-1}^{d}, p_{i}\right)\right) CVi=∣Ft−Fiw∣1,Fiw=πt(πt−1−1(Ft−1d,pi))
训练细节
我们使用帧 i t − 1 , i t , i t + 1 {i_{t−1},i_t,i_{t+1}} it−1,it,it+1 进行训练,使用 i t − 1 , i t {i_{t−1},i_t} it−1,it 进行测试。本文的所有动态对象都是由预训练好的语义分割模型EffcientPS得到
总结

由上图可知,DynamicDepth相比于之前的工作,其深度预测更准确,特别是在Cityscapes上,原因是该数据集包含更多动态对象。
具体来说,其贡献可以总结为以下几点:
- 提出了一种新的动态物体运动解耦(DOMD)模块,该模块利用初始深度先验和分割网络来解决最终深度预测中的物体运动不匹配问题
- 设计了一种针对运动物体周期性的训练方案(Dynamic Object Cycle Consistent training scheme),相辅相成提高先验深度估计和最终深度估计
- 我们设计了一个遮挡感知损失缓解DOMD解耦后运动目标的遮挡问题
但Dynamic依然存在的问题是:利用了预训练的分割网络,导致预测的深度结果和分割网络的性能密切相关
参考资料
单目多帧自监督深度估计(2021-2022)研究进展 - 知乎 (zhihu.com)