基于评分卡的风控模型开发
Project:基于评分卡的风控模型开发
一、基本信息
– 基本属性:包括了借款人当时的年龄
– 偿债能力:包括了借款人的月收入、负债比率
– 信用往来:两年内35-59天逾期次数、两年内60-89天逾期次数、两年内90天或高于90天逾期的次数
– 财产状况:包括了开放式信贷和贷款数量、不动产贷款或额度数量。
– 其他因素:包括了借款人的家属数量
– 时间窗口:自变量的观察窗口为过去两年,因变量表现窗口为未来两年
二、开发流程
Step1,数据探索性分析 违约率分析 缺失值分析 对于某个字段的统计分析(比如RevolvingUtilizationOfUnsecuredLines)
Step2,数据缺失值填充,采用简单规则,如使用中位数进行填充
Step3,变量分箱
1)对于age字段,分成6段 [-math.inf, 25, 40, 50, 60, 70, math.inf]
2)对于NumberOfDependents(家属人数)字段,分成6段 [-math.inf,2,4,6,8,10,math.inf]
3)对于3种逾期次数,即NumberOfTime30-59DaysPastDueNotWorse,NumberOfTime60-89DaysPastDueNotWorse,NumberOfTimes90DaysLate,分成10段 [-math.inf,1,2,3,4,5,6,7,8,9,math.inf]
4)对于其余字段,即RevolvingUtilizationOfUnsecuredLines, DebtRatio, MonthlyIncome, NumberOfOpenCreditLinesAndLoans, NumberRealEstateLoansOrLines 分成5段
Step4,特征筛选 使用IV值衡量自变量的预测能力,筛选IV值>0.1的特征字段
Step5,对于筛选出来的特征,计算每个bin的WOE值
Step6,使用逻辑回归进行建模
训练集、测试集切分
计算LR的准确率
Step7,评分卡模型转换 设p为客户违约的概率,那么正常的概率为1-p 客户违约概率p可以表示
评分卡的分值计算,可以通过 分值表示为比率对数的 线性表达式来定义,即 Score计算公式类似 y=kx + b ,A和B是常数,A称为“补偿”,B称为“刻度”,公式中的负号可以使得违约概率越低,得分越高
三、评估指标KS
评估指标KS( Kolmogorov-Smirnov ):
由两位苏联数学家A.N. Kolmogorov和N.V. Smirnov提出
在风控中,KS常用于评估模型区分度。区分度越大,说明模型的风险排序能力(ranking ability)越强
计算每个分箱区间累计坏账户占比与累计好账户占比差的绝对值,得到KS曲线 在这些绝对值中取最大值,得到此变量最终的KS值
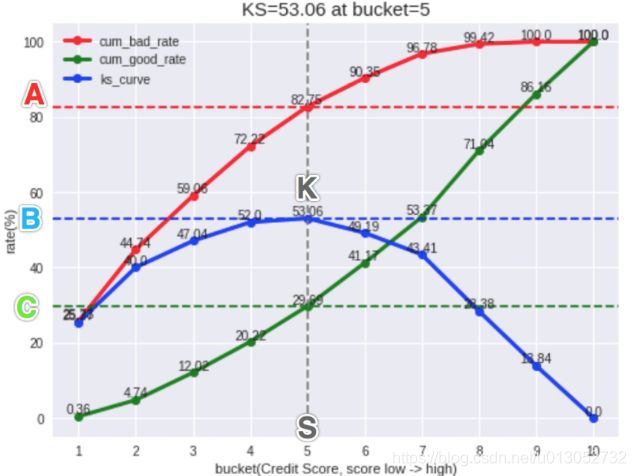
KS统计量是好坏距离或区分度的上限
KS越大,表明正负样本区分程度越好
四、WOE编码
特征离散化,是将数值型特征(一般是连续型的)转变为离散特征,比如woe转化,将特征进行分箱,再将每个分箱映射到woe值上,即转换为离散特征
采用woe编码的好处:
1)简化模型,使模型变得更稳定,降低了过拟合的风险
2)对异常数据有很强的鲁棒性,实际工作中的那些很难解释的异常数据一般不会做删除处理,如果特征不做离散化,这个异常数据带入模型,会给模型带来很大的干扰