Human Pose Regression with Residual Log-likelihood Estimation阅读笔记
基于残差对数似然估计的人体姿态回归
ICCV 2021 Oral
论文链接
代码链接
摘要: 热图法通过似然热图模拟输出分布,在人体姿态估计领域独领风骚。相比之下,基于回归的方法效率更高,但性能较差。本文从极大似然估计(MLE) 角度开发一种高效并有效的基于回归的姿态估计方法。从极大似然估计的角度来看,采用不同的回归损失是对输出密度函数作出不同的假设,密度函数越接近真实分布,回归性能越好。鉴于此,我们提出了一种新的具有残差对数似然估计(RLE)的回归范式 来捕获潜在的输出分布。具体而言,RLE学习分布的变化,而非 unreferenced underlying distribution,以促进训练过程。通过重参数化设计,我们的方法与现有模型相兼容,且该方法有效、高效、灵活。广泛的综合实验展示了其在各种人体姿态估计任务中的潜力。与传统回归范式相比,使用RLE的回归在没有任何 test-time 开销的情况下为MSCOCO带来12.4 mAP改进。此外,我们的回归方法首次优于热图法,尤其在多人姿态估计方面。
文章目录
- 基于残差对数似然估计的人体姿态回归
- 1. Introduction
- 2. Related Work
- 3. Method
-
- 3.1. General Formulation of Regression 回归的一般公式
- 3.2. Regression with Normalizing Flows 正则化流回归
- 3.3. Implementation Details 实现细节
- 4. Experiments on COCO
-
- 4.1. Main Results
- 4.2. Ablation Study
- 5. Experiments on Human3.6M
- 6. Conclusion
- Appendix
-
- A. Normalizing Flows 正则化流
- D. Visualization of the Learned Distribution 学习分布的可视化
1. Introduction
人体姿态估计在计算机视觉领域被广泛研究。近年来,深度卷积神经网络取得了重大进展。现有方法能分成基于热图和基于回归两种。热图法在人体姿态估计领域引领风骚。热图法为每个关节生成似然热图,并用 argmax 或 soft argmax 操作将关节定位为点。尽管基于热图的方法具有优异的性能,但其计算和存储需求较高。 将热图扩展到3D或4D(空间+时间)代价高昂,此外,热图难以部署在 one-stage 方法中。基于回归的方法直接将输入映射为关节坐标输出,这对各种人体姿态估计任务和实时应用,尤其在边缘设备上,是灵活有效的。ResNet-50 backbone 上的一个标准的热图 (3 个 deconv 层) 耗费 1.4× FLOPs,但同样backbone上的回归仅耗费1/20000 FLOPs。 然而,回归的性能较差,一些挑战性情况,如遮挡、运动模糊和截断,GT 标签本身就具有模糊性。基于热图的方法利用似然热图对这些模糊性具有鲁棒性,而目前的回归方法容易受到这些噪声标签的影响。
本工作通过探索极大似然估计(MLE)来建模输出分布,从而促进人体姿态回归。从极大似然估计的角度来看,标准欧几里德距离损失( l 1 l_1 l1 或 l 2 l_2 l2)可视为输出符合恒定方差的分布族(拉普拉斯分布或高斯分布)的特定假设。直观而言,如果用真实的潜在分布 (underlying distribution) 代替不适当的假设来构造似然函数,则可以提高回归性能。
为此,我们提出了一种新的有效回归范式:残差对数似然估计(Residual Log-likelihood Estimation: RLE),利用 归一化流(normalizing flow) 来估计潜在分布,并促进人体姿态回归。给定似然函数的一个可处理的预设假设,RLE估计残差对数似然,即分布的变化,相比于原始的 unreferenced underlying distribution,它更容易优化。 此外,我们为流模型设计了一种 重参数化策略,来学习潜在分布的内在特征,该策略使我们的回归框架可行,并能利用现成流模型来近似分布,而无需复杂的网络架构。
训练过程中,可以同时优化回归模型和 RLE 模块。由于潜在分布的形式未知,因此 RLE 模块也通过极大似然估计过程进行训练。此外,RLE 模块不参与推理阶段。换句话说,该方法可以在没有任何测试时间开销的情况下显著改进回归模型。
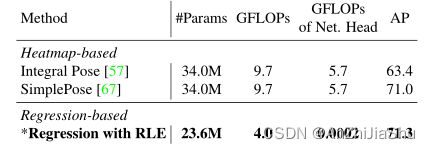
我们提出的回归框架是通用的,它可以应用于各种人体姿态估计算法(例如two-stage 方法,one-stage 方法)和各种任务(例如单人和多人2D/3D 姿态估计)。我们在三个姿态估计数据集上测试了该方法,包括MPII、MSCOCO和Human3.6M。RLE具有简单而有效的架构,将传统回归方法提升了12.4 mAP,并实现了优于热图法的性能,此外,它比热图法具有更高的计算和存储效率。具体而言,在MSCOCO数据集上,以 ResNet-50 为backbone的回归模型以4.0 GFLOP 实现了71.3 mAP,基于热图的SimplePose 以9.7 GFLOP实习71.0 mAP。我们希望我们的方法将启发该领域反思基于回归方法的潜力。
贡献总结如下:
- 我们提出了一种新的有效回归范式,具有重参数化设计和残差对数似然估计(RLE)。该方法在没有任何测试时间开销的情况下增强了人体姿态回归。
- 回归法首次优于热图法的性能,且计算和存储效率更高。
- 将其应用于各种人体姿态估计方法展示了其潜力。所有这些方法改进都很大。
2. Related Work
基于热图的姿态估计。 Tompson等人(Joint training of a convolutional network and a graphical model for human pose estimation)提出用似然热图来表示人类关节位置。自此,热图法在2D姿态估计领域独占鳌头。先驱工作设计强大的CNN模型来估计单人姿态估计的热图,许多工作将这一思想扩展到遵循 top-down 框架的多人姿态估计任务上,即检测和单人姿态估计。Bottom-up 框架从热图中检索多个身体关节,并将其分组为不同的人体姿态。Pavlakos等人首先将热图扩展到3D空间。Sun等人(Direct end-to-end multi-person pose estimation 2019)利用 soft argmax操作以可微的方式从热图中检索关节位置,这允许端到端训练,soft argmax可以防止量化误差,但仍需要生成高分辨率特征和热图。
基于回归的姿态估计。 人体姿态估计只有少数工作是基于回归的。Toshev等人首次利用卷积网络进行人体姿态估计。Carreira等人提出了一种迭代误差反馈(IEF)网络来提高回归模型的性能。周等人和田等人在 one-stage 目标检测框架中提出了直接姿态回归。Nie等人将 long-range displacement 分解为accumulative shorter displacement,但它易受遮挡的影响。Wei等人使用预定义的 pose anchors 回归 displacement。在3D 姿态估计中,孙等人提出了合成姿态回归,以学习三维人体姿态的内部结构。Rogez等人将人体姿态分类为一组K个 anchor-poses,并提出了一个回归模块将anchor细化为最终预测。Tow-stage 方法通过回归将 2D 姿态提升到 3D 空间,但这些2D姿态仍是基于热图预测的。尽管之前的工作已取得很大的进展,但是纯回归方法和基于热图的方法间仍存在巨大的性能差距。
本项工作首次将回归法的性能提高到与热图法相当的水平。我们的方法灵活,可以应用于各种人体姿态估计算法。
Normalizing Flow in Human Pose Estimation 人体姿态估计的正则化流。 最近的一些工作利用正则化流在3D人体姿态估计中建立先验。Xu等人提出了基于正则化流的具有运动学先验的3D人体形状和关节姿态模型。Zanfir等人使用正则化流为其弱监督方法建立SMPL关节角度先验。Biggs等人通过正则化流从模糊图像中采样最佳输出,从而学习姿态先验。与先前方法不同,我们利用正则化流来估计潜在的输出分布(我认为这也是一种先验)。
Adaptive Loss Function 自适应损失函数。 我们方法的输出分布是可学习的,因此损失函数也可学习。有一些关注自适应损失函数的工作,Imani等人提出了直方图损失,使用直方图(即热图)来表示输出分布。一些工作定义了一个损失函数的 superset,并通过调整函数的参数来改变loss。吴等人使用教师模型动态改变学生模型的损失函数。Barron提出了常见损失函数的泛化,该函数在训练过程中自动适应。与先前的方法不同,我们没有预先设置分布族的形式。在极大似然估计框架内,损失函数可以学习为任意形式。
3. Method
本工作旨在将基于回归方法的性能提升到与热图法相当水平。与基于热图的方法相比,基于回归的方法有很多优点:i)它摆脱了高分辨率热图,具有较低的计算和存储复杂度。ii)它具有连续输出,且不存在量化问题。iii)它能以低代价扩展到各种各样的场景(例如:one-stage 方法、基于视频的方法、3D场景)。但现有的回归法的致命缺陷是性能较差,这限制了其广泛使用。§3.1节从极大似然估计角度回顾回归的一般公式。然后,§3.2节提出了残差对数似然估计(RLE),这是一种利用归一化流捕捉潜在残差对数似然函数并提升人体姿态回归的方法。§3.3节描述了具体的实施细节。

3.1. General Formulation of Regression 回归的一般公式
标准的回归范式是对回归输出 u ^ \hat{u} u^ 应用 l 1 或 l 2 l_1或l_2 l1或l2损失,根据经验为不同的任务选择不同的损失函数。本节从极大似然角度回顾了回归问题。考虑图像 I I I,回归模型预测一个指示 ground truth 出现在位置 x 的概率分布 P Θ ( x ∣ I ) Θ P_Θ(x|I) \quad Θ PΘ(x∣I)Θ代表可学习模型的参数。由于标签固有的模糊性,标记的位置 µ g µ_g µg 可看作 human annotator 在 ground truth 附近采样的观察值。学习过程是优化模型参数Θ,使观察到的标签 µ g µ_g µg的可能性最大。因此MLE的损失函数定义如下:
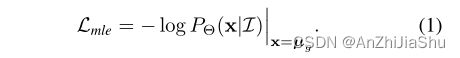
在此公式中,不同的回归损失本质上是输出概率分布的不同假设。例如,在一些目标检测和 dense correspondences 工作中,假设密度服从高斯分布,模型需要预测两个值: u ^ 和 σ ^ \hat{u}和\hat{σ} u^和σ^ (均值,方差)来建立密度函数:
![]()
为了最大化观察到的标签µg的似然,损失函数变为:
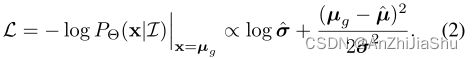
如果假设密度函数具有常数方差,即 σ ^ \hat{σ} σ^为常数,则 loss 退化为标准的 l 2 l_2 l2 loss: L = ( µ g − µ ^ ) 2 L = (µ_g − \hat{µ})^2 L=(µg−µ^)2。此外,若假设密度服从拉普拉斯分布且方差恒定,则损失函数将成为标准的 l 1 l_1 l1 loss。推理阶段,用于控制分布位置的值 µ ^ \hat{µ} µ^ 用作回归输出。
从这个角度来看,损失函数取决于分布 P Θ ( x ∣ I ) P_Θ(x|I) PΘ(x∣I)的形状。因此,更精确的密度函数可以产生更好的结果。然而,由于潜在分布的解析表达式未知,该模型不能简单回归多个值来构建如等式2所示的密度函数。为了估计潜在分布并促进人体姿态回归,下一节通过利用归一化流提出一种新的回归范式。
3.2. Regression with Normalizing Flows 正则化流回归
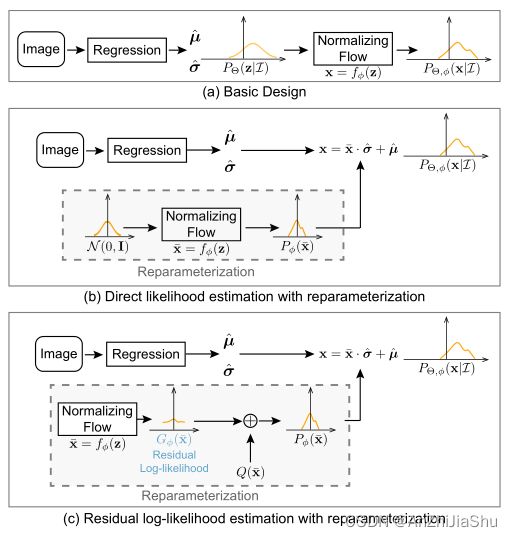
本小节介绍利用标准化流进行回归的范式的三种变体(见图2)。
Basic Design。 图2(a) 阐述了具有正则化流回归范式的基本设计。这里,正则化流通过可逆映射转换简单分布来学习构造复杂分布。将随机变量z上的分布 P Θ ( z ∣ I ) P_Θ(z|I) PΘ(z∣I)视为初始密度函数。它由回归模型 Θ 的输出 µ ^ 和 σ ^ \hat{µ}和\hat{σ} µ^和σ^定义。简单起见,假定:
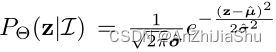
即,服从高斯分布,选择一个平滑可逆映射 f ϕ : R 2 → R 2 f\phi:R^2→ R^2 fϕ:R2→R2 将 z 转换为x,即 x = f ϕ ( z ) x=f{\phi}(z) x=fϕ(z),其中 ϕ \phi ϕ 是流模型的可学习参数。
变换后的变量x遵循另一个分布 P Θ , ϕ ( x ∣ I ) P_{Θ,\phi}(x | I) PΘ,ϕ(x∣I)。概率密度函数 P Θ , ϕ ( x ∣ I ) P_{Θ,\phi}(x | I) PΘ,ϕ(x∣I)取决于回归模型 Θ 和流模型 f ϕ f{\phi} fϕ,其可计算为:
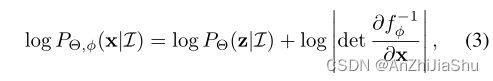
z = f ϕ − 1 z=f_{\phi}^{-1} z=fϕ−1 是 f ϕ f_{\phi} fϕ 的逆。这样,给定任意x,反向计算出z,可以通过等式3估计相应的对数概率。此外, P Θ , ϕ ( x ∣ I ) P_{Θ,\phi}(x | I) PΘ,ϕ(x∣I) 是可学习的,只要 f ϕ f_{\phi} fϕ足够复杂,就可以拟合任意分布。实际中,可以依次组合几个简单的映射来构造任意复杂的函数:
![]()
对学习的分布 P Θ , ϕ ( x ∣ I ) P_{Θ,\phi}(x | I) PΘ,ϕ(x∣I)执行极大似然过程。因此,损失函数公式为:
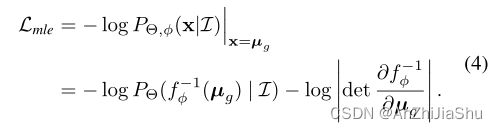
Note: 潜在的最优分布 P o p t ( x ∣ I ) P_{opt}(x | I) Popt(x∣I)未知。通过极大化标记位置的似然,以无监督 的方式学习流模型。例如,对于标签与 human annotators 偏差较大的挑战性案例(例如遮挡),预测的分布应该具有较大的方差来最大化对数概率。
重参数化。 虽然基本设计似乎合理,但在实践中并不可行。 f ϕ f_{\phi} fϕ的学习依赖于公式4 损失函数中的 l o g ∣ d e t ∂ f ϕ − 1 ∂ µ g ∣ log|det\frac{\partial f_{\phi}^{-1}}{\partial µ_g}| log∣det∂µg∂fϕ−1∣ 和 f ϕ − 1 ( µ g ) f^{−1}_{\phi}(µ_g) fϕ−1(µg)。因此, ϕ \phi ϕ将学习拟合 µ g µ_g µg在所有图像中的分布。然而,我们想要了解的分布是关于输出如何偏离输入图像上的 ground truth 条件,而非 ground truth 本身在图像上的分布。
为使我们的回归框架可行并与现成的流模型兼容,我们进一步设计了具有重参数化策略的回归范式。新范式如图2(b)所示。我们假设所有潜在分布共享相同的密度函数族,但在输入 I I I上具有不同的均值和方差。首先,利用流模型 f ϕ f_{\phi} fϕ将一个 zero-mean initial 分布 z ˉ ∼ N ( 0 , I ) \bar{z}∼ N(0,I) zˉ∼N(0,I)映射到一个 zero-mean deformed 分布 x ˉ ∼ P ϕ ( x ˉ ) \bar{x}∼ P_{\phi}(\bar{x}) xˉ∼Pϕ(xˉ)。然后回归模型Θ预测两个值, µ ^ 和 σ ^ \hat{µ}和\hat{σ} µ^和σ^ 来控制分布的位置和规模。最终分布 P Θ , ϕ ( x ∣ I ) P_{Θ,\phi}(x | I) PΘ,ϕ(x∣I) 通过将 x shifting 并 rescaling 得到 x ˉ \bar{x} xˉ来获得,其中 x = x ˉ ⋅ σ ^ + µ ^ x=\bar{x}·\hat{σ}+\hat{µ} x=xˉ⋅σ^+µ^。
因此,具有重参数化的损失函数可以写成:
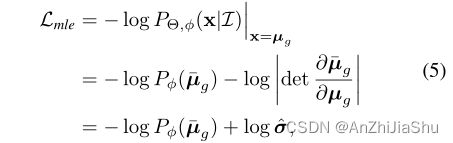
![]()
通过重参数化设计,现在流模型可以专注于学习能反映输出与ground truth 偏差的 µ g µ_g µg的分布。
残差似然估计。 在重参数化之后,可以以端到端的方式训练回归框架。回归值 µ ˉ \bar{µ} µˉ的训练和流动模型 f ϕ f_{\phi} fϕ耦合依靠等式5损失函数中的对数项数 l o g P ϕ ( μ ˉ ) log P_{\phi}(\bar{μ}) logPϕ(μˉ) 耦合在一起。然而,这两个模型间存在复杂的依赖关系。回归模型的训练完全依赖于流模型 f ϕ f_{\phi} fϕ估计的分布。 在训练的初始阶段,分布的形状远不正确,增加了训练回归模型的难度,并可能降低模型性能。
为简化训练过程,我们开发了一种 gradient shortcut 方式来减少这两个模型间的依赖性。从形式上讲,由流模型 P ϕ ( x ˉ ) P_{\phi}(\bar{x}) Pϕ(xˉ)估计的分布试图拟合最优潜在分布 P o p t ( x ˉ ) P_{opt}(\bar{x}) Popt(xˉ),其可分为三项:
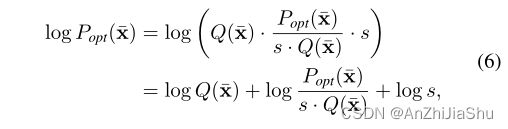
Q ( x ˉ ) Q(\bar{x}) Q(xˉ) 可以是一个简单的分布,例如高斯分布,即 Q ( x ˉ ) = N ( 0 , I ) Q(\bar{x}) = N(0, I) Q(xˉ)=N(0,I)。 l o g P o p t ( x ˉ s . Q ( x ˉ ) ) log\frac{P_{opt}(\bar{x}}{s.Q(\bar{x})}) logs.Q(xˉ)Popt(xˉ) 项称为残差似然(residual log-likelihood),常数s确保残差项是一个分布 。我们假设 Q ( x ˉ ) Q(\bar{x}) Q(xˉ)可以大致匹配潜在分布,但并不完全匹配。残差对数似然是为了补偿差异。因此,我们以与等式6相同的方式拆分 P ϕ ( x ˉ ) P_{\phi}(\bar{x}) Pϕ(xˉ) 的对数概率:
![]()
G ϕ ( x ˉ ) G_{\phi}(\bar{x}) Gϕ(xˉ) 是由流模型学习的分布。 s = 1 ∫ G ϕ ( x ˉ ) Q ( x ˉ ) d x ˉ s = \frac{1}{\int G_{\phi}(\bar{x})Q(\bar{x})d\bar{x}} s=∫Gϕ(xˉ)Q(xˉ)dxˉ1的值能被 Riemann sum 近似。s的推导见补充文件。
通过这种方式, G ϕ ( x ˉ ) G_{\phi}(\bar{x}) Gϕ(xˉ)将尝试拟合潜在的残差似然 P o p t ( x ˉ ) s . Q ( x ˉ ) \frac{P_{opt}(\bar{x})}{s.Q(\bar{x})} s.Q(xˉ)Popt(xˉ),而非学习整个分布。最后,结合再参数化设计(等式5)和残差对数似然估计(等式7),总损失函数可以定义为:
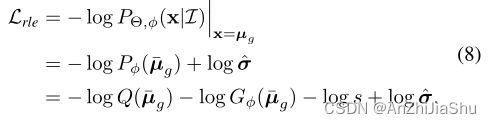
该过程由图2(c)阐述。
训练过程中,来自 Q ( µ ˉ g ) Q(\bar{µ}_g) Q(µˉg)的反向传播梯度不依赖于流模型,这加速了回归模型的训练。此外,正如ResNet的假设,优化残差映射易于优化原始未引用映射。在极端情况下,若预设近似 Q ( x ˉ ) Q(\bar{x}) Q(xˉ)是最优的,则将残差对数概率推到零比通过在 f ϕ f_{\phi} fϕ中的一堆可逆映射拟合一个 identity mapping 更容易。残差对数似然估计的有效性在§4.1中被验证。
3.3. Implementation Details 实现细节
训练阶段,以端到端的方式同步优化回归模型和流模型。用残差对数似然估计损失 L r l e L_{rle} Lrle替换标准回归损失( l 1 和 l 2 l_1和l_2 l1和l2)。默认情况下,初始密度设置为拉普拉斯分布。在测试阶段,预测的平均值 μ ˉ \bar{μ} μˉ 作为回归输出。因此,在推理过程中不需要运行流模型。(推理就不需要流模型预测先验了) 该特性使该方法灵活,易于应用于各种回归算法,而无需任何测试时间开销。此外,可以从 σ ˉ \bar{σ} σˉ获得预测置信度:

其中, σ i ˉ \bar{σ_i} σiˉ 是第 i 个关节的学习偏差,K表示关节总数。偏差 σ i ˉ \bar{σ_i} σiˉ 用sigmoid函数预测,因此有 σ i ˉ ∈ ( 0 , 1 ) 和 c ˉ ∈ ( 0 , 1 ) \bar{σ_i}∈(0,1)和\bar{c}∈(0,1) σiˉ∈(0,1)和cˉ∈(0,1)。
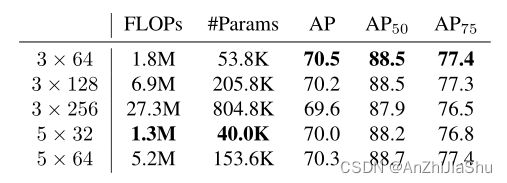
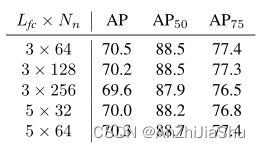
Flow Model 流模型。 提出的回归范式与流模型无关,因此,可以应用各种现成的流模型。 实验采用 RealNVP 进行快速训练。具有 N n N_n Nn个神经元的 L f c L_{fc} Lfc个全连接层的可逆函数表示为 L f c × N n L_{fc} × N_n Lfc×Nn,默认情况下,设 L f c = 3 , N n = 64 L_{fc} = 3 , N_n = 64 Lfc=3,Nn=64。流模型是轻量级的,几乎不影响训练速度。补充文件(§A)中提供了流模型架构的更详细描述。
任务。 本文提出的回归范式是通用的,可用于各种人体姿态估计任务中。实验在五个任务中的七种不同算法上验证了我们提出的回归范式:single-person 2D pose estimation, top-down 2D pose estimation, one-stage 2D pose estimation, single-stage 3D pose estimation 和 two-stage 3D pose estimation。详细的训练设置见§4和§5。补充文件中提供了单人2D姿态估计的实验。
4. Experiments on COCO
Implementation Details 实现细节。 我们将RLE嵌入到 top-down 方法和one-stage 方法中。对于 top-down 方法,我们采用了一种简单的架构,该架构由一个ResNet-50 backbone 组成,其后接一个平均池化层和一个FC层。FC层由K×4个神经元组成,其中 4 表示 µ ˉ 和 σ ˉ \bar{µ} 和 \bar{σ} µˉ和σˉ,K=17表示身体关键点的数量。在validation set 和 test-dev set 上使用 SimplePose 提供的human detector。遵循 HRNet 进行数据增强和训练设置。消融实验采用端到端方法 Mask R-CNN。实现基于Detectron2,堆叠8个卷积层,后接是平均池化层和FC层形成关键点头。我们训练270000次迭代,每个GPU 4个图像,总共4个GPU。其他参数与原始Detectron2相同。
对于 one-stage 方法,采用 sota 方法(Point-set anchors for object detection, instance segmentation and pose estimation)。将其2K-channel 回归头替换为4K-channel头,来预测 µ ˉ 和 σ ˉ \bar{µ}和\bar{σ} µˉ和σˉ。实施基于其的官方代码,其他训练细节也相同。
4.1. Main Results
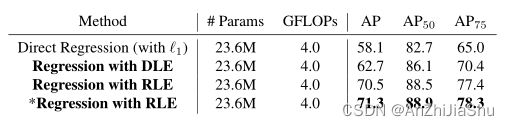
与传统回归的比较。
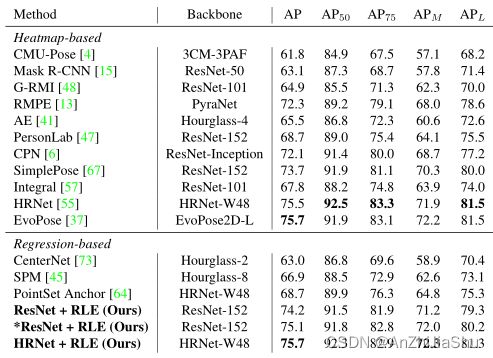
与基于热图的方法的比较。 直接回归方法首次优于基于热图的方法的性能。
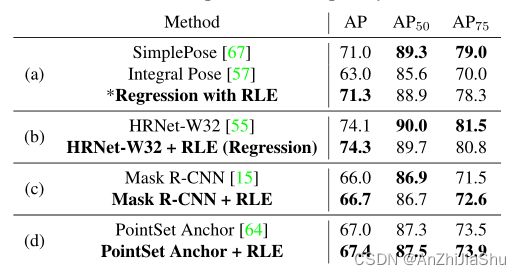
在COCO test-dev 上与SOTA的比较。 实验结果验证了热图并非人体姿态估计的唯一解决方案。基于回归的方法具有很大的潜力,可以实现优于热图的性能。
与预测正确性的相关性。 估计的标准偏差 σ ˉ \bar{σ} σˉ建立了与预测正确性的相关性。对于更不确定的结果,该模型将输出更大的 σ ˉ \bar{σ} σˉ。因此, σ ˉ \bar{σ} σˉ的作用与热图中的置信度score 相同。 利用公式9将偏差转换为置信度。为了分析 σ ˉ \bar{σ} σˉ的相关性和预测正确性,我们在COCO验证集上计算置信度和 OKS to the ground truth 间的 Pearson correlation coefficient 。基于热图的预测的置信度是热图的最大值。表 4表明,与基于热图的方法相比,RLE与OKS的相关性更强(相对提高15.2%)。在实际应用和其他下游任务中,可靠的置信度分数是有用且必要的。RLE解决了基于回归方法中 confidence scores 的不足,并提供了比热图法更可靠的分数。

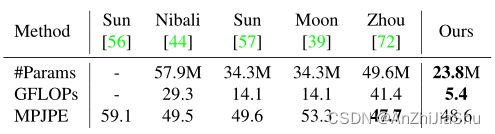
计算复杂性。
4.2. Ablation Study
RealNVP Architecture。 表11中比较了RealNVP模型的不同网络架构。结果表明,在不同的RealNVP架构下,最终AP保持稳定。我们认为对于流模型而言,学习残差对数似然是很容易的。因此,结果对架构的变化具有鲁棒性。
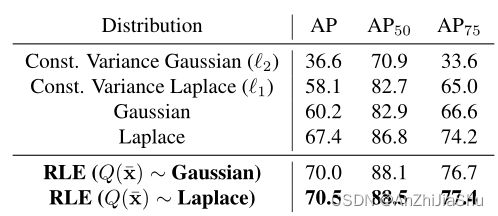
Initial Density。 为检验输出分布的假设如何影响MLE中的回归性能,我们将不同密度函数的结果与我们的方法进行了比较。若假设拉普拉斯分布和高斯分布具有恒定方差,则它们将退化为标准的 l 1 和 l 2 l_1 和 l_2 l1和l2 loss。如表7所示,我们方法的学习分布提供了超过21.3%的改进。此外,我们还研究了假设输出服从具有可学习偏差 σ σ σ 的高斯和拉普拉斯分布的 baseline。具有可学习σ的分布优于具有常方差的分布,但仍低于RLE。
此外,还测试了RLE的不同初始密度 Q ( x ˉ ) Q(\bar{x}) Q(xˉ)。原始高斯分布和拉普拉斯分布之间存在较大差距。 然而,通过RLE学习密度的变化,这两种分布间的差异显著减少。结果表明,RLE对初始密度的不同假设具有鲁棒性。
5. Experiments on Human3.6M
Ablation Study.

与sota的比较。

6. Conclusion
本文从极大似然估计的角度提出了一种有效回归范式。学习过程是为了最大化观察值(observation) 的概率。我们利用归一化流模型学习关于可处理初始密度函数的残差对数似然。综合实验验证了该方法的有效性。基于回归的方法首次优于基于热图方法的性能。基于回归的方法有效且灵活。我们希望我们的方法能启发该领域反思回归的潜力。
Appendix
A. Normalizing Flows 正则化流
正则化流的思想是通过利用一个可学习的函数: x = f ϕ ( z ˉ ) x=f_{\phi}(\bar{z}) x=fϕ(zˉ)转化更简单的分布 P ( z ˉ ) P(\bar{z}) P(zˉ) 来表示复杂的分布 P ϕ ( x ˉ ) P_{\phi}(\bar{x}) Pϕ(xˉ)。如§3.2所述, P ϕ ( x ˉ ) P_{\phi}(\bar{x}) Pϕ(xˉ)的概率计算为:

函数 f ϕ f_{\phi} fϕ必须是可逆的,因为我们需要计算 z ˉ = f ϕ − 1 ( x ˉ ) \bar{z}=f^{−1}_{\phi}(\bar{x}) zˉ=fϕ−1(xˉ)。实际上,我们可以依次组合几个简单映射来构造任意复函数,即 x = f ϕ ( z ) = f K ◦ ⋅ ⋅ ⋅ ◦ f 2 ◦ f 1 ( z ) x=f_{\phi}(z)=f_K◦· · ·◦f_2◦f_1(z) x=fϕ(z)=fK◦⋅⋅⋅◦f2◦f1(z),其中K表示映射函数的数量,且 z K = x z_K=x zK=x。x的对数概率(log-probability)变为:
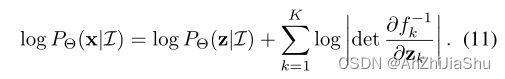
RealNVP。 本文采用RealNVP来学习潜在的残差对数似然。RealNVP将每层 f k f_k fk设计为:

其中, g k , h k : R d → R D − d gk, hk: R^d → R^{D−d} gk,hk:Rd→RD−d 是两个任意的神经网络,D 是输入向量的维度,d是D维变量的拆分位置。运算符 ⊙ \odot ⊙表示逐点乘积。为了链接多个函数 f k f_k fk,在每一步之前对输入进行排列。在我们的实验中,K设置为6。在每个函数 f k fk fk中,我们对 g k 和 h k g_k和h_k gk和hk 均采用带 N n N_n Nn个神经元的 L f c L_{fc} Lfc个全连接层。每个全连接层后跟一个Leaky-RELU层。
计算复杂性。 RealNVP模型速度快,轻量级。表11显示了训练期间的计算复杂度和模型参数列。可以看出,流模型具有计算效率和存储效率。训练期间的开销可以忽略不计。
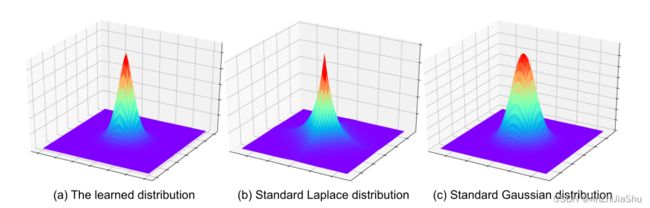
D. Visualization of the Learned Distribution 学习分布的可视化
学习分布的可视化如图4所示。学习分布的峰值比高斯分布更尖锐,边缘比拉普拉斯分布更平滑。