Python3--基础知识回顾01
Python基础知识回顾
- 1. Python 的特点和应用概述
- 2. Python基础知识(语法,判断、循环)
- 2.1 Python的关键字
- 2.2 数据类型转换
- 2.3 Python推导式(重点)
-
- 2.3.1列表(list)推导式
- 2.3.2 字典(set)推导式
- 2.3.3 元组(tuple)推导式
- 2.4 python的数字
- 2.5 Python的列表
-
- 2.5.1 Python列表的访问(索引)、修改(=)、删除(del)、更新( append() )
- 2.5.2 Python列表操作符(重点)
- 2.5.3 Python(重点)
- 2.4 python的元组
- 2.4.1 元组基础知识
- 2.4.2 元组常用函数
- 2.5 python的字典(映射)
- 2.6 Python的日期与时间
- 2.7 Python的函数
- # 2.8 Python模块
-
- 2.8.1 Python中的包
- 3. 1 Python的文件IO
- 3. 2 Python异常处理(python程序在运行中出现的异常和错误)
- 4.Python3面向对象
-
- 4.1 类的声明
- 4.2 类的继承(单继承)
- 4.2 类的继承(多继承)
- 4.3 类属性与方法
1. Python 的特点和应用概述
Python是一种解释型,面向对象、动态数据类型的高级程序设计语言
![]()
- Python的特点(列举了自己所不熟悉的)
6.可移植
7.可扩展:如果你需要一段运行很快的关键代码,或者是想要编写一些不愿开放的算法,你可以使用C或C++完成那部分程序,然后从你的Python程序中调用。
8.数据库:Python提供所有主要的商业数据库的接口。
9.GUI编程:Python支持GUI可以创建和移植到许多系统调用。
10.可嵌入: 你可以将Python嵌入到C/C++程序,让你的程序的用户获得"脚本化"的能力。
- Python丰富的库
丰富的库 – Python 标准库确实很庞大。它可以帮助你处理各种工作,包括正则表达式、文档生成、单元测试、线程、数据库、网页浏览器、CGI、FTP、电子邮件、XML、XML-RPC、HTML、WAV 文件、密码系统、GUI(图形用户界面)、Tk 和其他与系统有关的操作。记住,只要安装了 Python,所有这些功能都是可用的。这被称作 Python 的“功能齐全”理念。除了标准库以外,还有许多其他高质量的库,如 wxPython、Twisted 和 Python 图像库等等。
- Python的应用
Youtube Reddit社交分享网站 Dropbox文件分享服务 豆瓣网 图书 唱片等文化产品的资料数据库网站 知乎 果壳(泛科技主题的网站) EVE(网络游戏)
Pycharm和Python的下载和安装
VScode和Python的下载和安装
2. Python基础知识(语法,判断、循环)
2.1 Python的关键字
在 Python 3 中,可以用中文作为变量名,非 ASCII 标识符也允许,但作为一名程序员,我们还是保持基本素养,哈哈哈,英文yyds
import keyword
keyword.kwlist
['False', 'None', 'True', 'and', 'as', 'assert', 'break', 'class',
'continue', 'def', 'del', 'elif', 'else', 'except', 'finally',
'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda',
'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try',
'while', 'with', 'yield']
单行注释用 # ,多行注释用 “”“” 内容 “”“” 或’'‘内容 ‘’’
我们可以使用反斜杠 \ 来实现多行语句
空行(便于日后代码的维护或重构)
函数之间或类的方法之间用空行分隔,表示一段新的代码的开始。类和函数入口
之间也用一行空行分隔,以突出函数入口的开始。
input() —等待用户输入
Python 可以在同一行中使用多条语句,语句之间使用分号 ; 分割
不换行输出 print( x, end=" " )
import 与 from…import
在 python 用 import 或者 from…import 来导入相应的模块。
将整个模块(somemodule)导入,格式为: import somemodule
从某个模块中导入某个函数,格式为: from somemodule import somefunction
从某个模块中导入多个函数,格式为: from somemodule import firstfunc, secondfunc, thirdfunc
将某个模块中的全部函数导入,格式为: from somemodule import *
Python的数据类型
int bool float complex string
#查看python数据类型
type()
2.2 数据类型转换
隐式类型转换 - 自动完成
显式类型转换 - 需要使用类型函数来转换
内置数据类型强转以下几个内置的函数可以执行数据类型之间的转换。这些函数返回一个新的对象,表示转换的值。
int()
float()
str()
chr()
ord()
hex()
oct()
repr() 将对象 x 转换为表达式字符串
eval() 用来计算在字符串中的有效Python表达式,并返回一个对象
tuple() list() set() dict() frozenset() 传入序列,转换为元组、列表、集合、字典、不可变集合
2.3 Python推导式(重点)
Python 推导式是一种独特的数据处理方式,从一个数据序列构建另一个新的数据序列的结构体。
包括
列表(list)推导式
字典(dict)推导式
集合(set)推导式
元组(tuple)推导式
2.3.1列表(list)推导式
[表达式 for 变量 in 列表]
[表达式 for 变量 in 列表 if 条件]
# 例如
new_names = [name.upper()for name in names if len(name)>3]
列表生成元素表达式,可以是有返回值的函数。
2.3.2 字典(set)推导式
{ key_expr: value_expr for value in collection if condition }
listdemo = ['Google','Runoob', 'Taobao']
# 将列表中各字符串值为键,各字符串的长度为值,组成键值对
>>> newdict = {key:len(key) for key in listdemo}
>>> newdict
{'Google': 6, 'Runoob': 6, 'Taobao': 6}
2.3.3 元组(tuple)推导式
元组推导式可以利用 range 区间、元组、列表、字典和集合等数据类型,快速生成一个满足指定需求的元组。
(expression for item in Sequence )
a = (x for x in range(1,10))
Pyhon解释器的配置,交互式编程和脚本编程
python的运算符
2.4 python的数字
Python 数字数据类型用于存储数值。
数据类型是不允许改变的,这就意味着如果改变数字数据类型的值,将重新分配内存空间
\t \r \n
2.5 Python的列表
列表都可以进行的操作包括索引,切片,加,乘,检查成员
此外,Python 已经内置确定序列的长度以及确定最大和最小的元素的方法。
列表是最常用的 Python 数据类型,它可以作为一个方括号内的逗号分隔值出现。
列表的数据项不需要具有相同的类型
创建一个列表,只要把逗号分隔的不同的数据项使用方括号括起来即可
list4 = ['red', 'green', 'blue', 'yellow', 'white', 'black']
2.5.1 Python列表的访问(索引)、修改(=)、删除(del)、更新( append() )
list1 = ['Google', 'Runoob', 'Taobao']
list1.append('Baidu')
del list[2]
2.5.2 Python列表操作符(重点)
len()--->>>求长度
+ --->>>组合
["a"]*4 --->>>["a","a","a","a"] 重复
3 in [1,2,3] --->>>True 判断
for x in [1, 2, 3]: print(x, end=" ") --->>>迭代
常用
list() 将元组转换为列表
cmp() 比较两个列表的元素
len() 列表元素个数
max() 返回列表的最大值
min() 返回列表的最小值
2.5.3 Python(重点)
# 添加元素
list.append()
list.extend(seq)
list.insert(index, obj)
# 删除
list.remove(obj)
list.pop([index=-1])
list.index(obj) # 索引
# 排序和反转
list.sort(cmp=None, key=None, reverse=False)
list.reverse()
2.4 python的元组
2.4.1 元组基础知识
Python 的元组与列表类似,不同之处在于元组的元素不能修改。
元组使用小括号,列表使用方括号。
tup2 = (1, 2, 3, 4, 5 )
tup3 = "a", "b", "c", "d"
元组中只包含一个元素时,需要在元素后面添加逗号
任意无符号的对象,以逗号隔开,默认为元组
元组运算符 与 与列表运算符相同
2.4.2 元组常用函数
元组内置函数
cmp(tuple1,tuple2)
len(tuple)
min(tuple)
tuple(seq)
2.5 python的字典(映射)
字典是另一种可变容器模型,且可存储任意类型对象
字典的每个键值 key:value 对用冒号 : 分割,每个键值对之间用逗号 , 分割,整个字典包括在花括号 {} 中 ,格式如下所示:
d = {key1 : value1, key2 : value2 }
键一般是唯一的,如果重复最后的一个键值对会替换前面的,值不需要唯一
值可以取任何数据类型,但键必须是不可变的,如字符串,数字或元组。
tinydict = {'Alice': '2341', 'Beth': '9102', 'Cecil': '3258'}
访问字典里的值:
#!/usr/bin/python
tinydict = {'Name': 'Zara', 'Age': 7, 'Class': 'First'}
print "tinydict['Name']: ", tinydict['Name']
print "tinydict['Age']: ", tinydict['Age']
访问(索引),删除(del),修改(=)
字典的特性
1.键唯一
2.键不可变,用数字,字符串,元组。用列表不行
内置函数与方法
cmp()
len()
str()输出字典可打印的字符串表示
type()返回变量类型
dict.clear() 删除字典的所有元素
popitem() 返回并删除字典中的最后一对键和值
pop(key[,default]) 删除字典给定键 key 所对应的值,返回值为被删除的值。key值必须给出。 否则,返回default值。
dict.copy() 返回字典的浅复制
dict.update(dict2) 把字典dict2的键/值对更新到dict里
**dict.fromkeys(seql,val)** 以seql作键,val作值(重要)
dict.get(key,default=None) 返回指定键的值
dict.has_key(key) 如果键在字典dict里返回true,否则返回false
dict.keys() 以列表返回一个字典所有的键
dict.values() 以列表返回字典中的所有值
2.6 Python的日期与时间
Python 提供了一个 time 和 calendar 模块可以用于格式化日期和时间。
1970年后的时间戳
import time # 引入time模块
cur_time = time.time() #用于获取当前时间戳==
- 时间元组
很多Python函数用一个元组装起来的9组数字处理时间
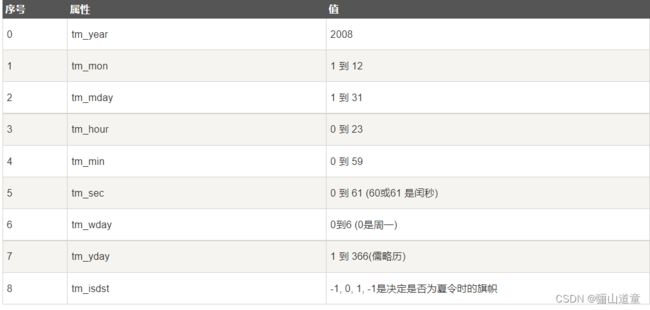
几个时间函数(获取当前时间:time.localtime:
localtime = time.localtime(time.time())
print "本地时间为 :", localtime
打印结果:
本地时间为 : time.struct_time(tm_year=2016, tm_mon=4, tm_mday=7, tm_hour=10, tm_min=3, tm_sec=27, tm_wday=3, tm_yday=98, tm_isdst=0)
获取格式化的时间time.asctime()可以根据需要选取各种格式:
localtime = time.asctime( time.localtime(time.time()) )
print "本地时间为 :", localtime
格式化日期time.strftime(format[, t])
根据格式化符号,可查.
格式化成2016-03-20 11:45:39形式
print time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
格式化成Sat Mar 28 22:24:24 2016形式
print time.strftime("%a %b %d %H:%M:%S %Y", time.localtime())
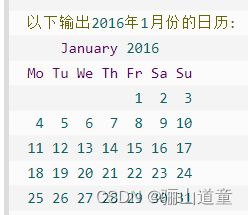
获取某月月历
import calendar
cal = calendar.month(2016, 1)
print "以下输出2016年1月份的日历:"
print cal
time.clock( ) 用以浮点数计算的秒数返回当前的CPU时间。用来衡量不同程序的耗时,比time.time()更有用。
time.sleep(secs)
推迟调用线程的运行,secs指秒数。
calendar.isleap(year)
calendar.weekday(year,month,day)返回给定日期的日期码。0(星期一)到6(星期日)。月份为 1(一月) 到 12(12月)。
2.7 Python的函数
定义一个函数;
def关键字开头,后跟函数名括号和参数冒号
[tab]函数体
[tab]返回值
def functionname( parameters ):
"函数_文档字符串"
function_suite
return [expression]
Python 传不可变对象实例 strings, tuples, 和 numbers 是不可更改的对象,而 list,dict 等则是可以修改的对象,类似 c++ 的值传递\
可变类型:类似 c++ 的引用传递,如 列表,字典
传可变对象实例
- 参数:
必备参数:必备参数须以正确的顺序传入函数。调用时的数量必须和声明时的一样
关键字参数:使用关键字参数允许函数调用时参数的顺序与声明时不一致,因为 --------------------------Python 解释器能够用参数名匹配参数值
默认参数:
**不定长参数:**可能需要一个函数能处理比当初声明时更多的参数。这些参数叫做不定长参数,和上述2种参数不同,声明时不会命名(加星号)
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# 可写函数说明
def printinfo( arg1, *vartuple ):
"打印任何传入的参数"
print "输出: "
print arg1
for var in vartuple:
print var
return
# 调用printinfo 函数
printinfo( 10 )
printinfo( 70, 60, 50 )
# 2.8 Python模块
当你导入一个模块,Python 解析器对模块位置的搜索顺序是:
当前目录\shell变量的PYTHONPATH的每个目录\如果都找不到,会查看默认路径。
例如在UNIX下的典型目录:
set PYTHONPATH=/usr/local/lib/python
- 命名空间和作用域
Python 会智能地猜测一个变量是局部的还是全局的,它假设任何在函数内赋值的变量都是局部的
因此,如果要给函数内的全局变量赋值,必须使用 global 语句。
global VarName 的表达式会告诉 Python, VarName 是一个全局变量
- dir() 函数一个排好序的字符串列表,内容是一个模块里定义过的名字
返回的列表容纳了在一个模块里定义的所有模块,变量和函数。如下一个简单的实例
import math
content = dir(math)
globals() 和 locals() 函数可被用来返回全局和局部命名空间里的名字
reload() 函数
当一个模块被导入到一个脚本,模块顶层部分的代码只会被执行一次。
因此,如果你想重新执行模块里顶层部分的代码,可以用 reload() 函数。该函数会重新导入之前导入过的模块
2.8.1 Python中的包
包是一个分层次的文件目录结构,它定义了一个由模块及子包,和子包下的子包等组成的 Python 的应用环境
包就是文件夹,但该文件夹下必须存在 init.py 文件, 该文件的内容可以为空。init.py 用于标识当前文件夹是一个包。

3. 1 Python的文件IO
open() 方法
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
参数说明:
file: 必需,文件路径(相对或者绝对路径)。
mode: 可选,文件打开模式 w r b + a
buffering: 设置缓冲
encoding: 一般使用utf8
errors: 报错级别
newline: 区分换行符
closefd: 传入的file参数类型
opener: 设置自定义开启器,开启器的返回值必须是一个打开的文件描述符。
file.open()
file.write()
file.append()
file.seek(offset[, whence])
file.isatty()
file.readline([size])
file.seek(offset[, whence])
3. 2 Python异常处理(python程序在运行中出现的异常和错误)
- 异常处理
异常即是一个事件,该事件会在程序执行过程中发生,影响了程序的正常执行。 - 断言(Assertions)
捕捉异常可以使用try/except语句。
Python异常处理中的标准异常
例如常见:
RuntimeError 一般的运行时错误
AttributeError 对象没有这个属性
ImportError 导入模块/对象失败
NameError 未声明/初始化对象 (没有属性)
UnboundLocalError 访问未初始化的本地变量
SyntaxError Python 语法错误
Warning 警告的基类
try:
fh = open("testfile", "w")
fh.write("这是一个测试文件,用于测试异常!!")
except IOError:
print "Error: 没有找到文件或读取文件失败"
else:
print "内容写入文件成功"
fh.close()
1.如果当try后的语句执行时发生异常,python就跳回到try并执行第一个匹配该异常的except子句,异常处理完毕,控制流就通过整个try语句(除非在处理异常时又引发新的异常)
2.如果在try后的语句里发生了异常,却没有匹配的except子句,异常将被递交到上层的try,或者到程序的最上层(这样将结束程序,并打印默认的出错信息)。
3.如果在try子句执行时没有发生异常,python将执行else语句后的语句(如果有else的话),然后控制流通过整个try语句。
try:
fh = open("testfile", "w")
fh.write("这是一个测试文件,用于测试异常!!")
except IOError:
print "Error: 没有找到文件或读取文件失败"
else:
print "内容写入文件成功"
fh.close()
python test.py
内容写入文件成功
$ cat testfile # 查看写入的内容
这是一个测试文件,用于测试异常!!
4.Python3面向对象
4.1 类的声明
class MyClass:
#构造方法,类实例化后自动调用(可有参,可无参)
def __init__(self, imapart):
self.data=imapart
"""一个简单的类实例"""
i = 12345
def f(self):
return 'hello world'
# 实例化类
x = MyClass()
# 访问类的属性和方法
print("MyClass 类的属性 i 为:", x.i)
print("MyClass 类的方法 f 输出为:", x.f())
注意:
类实例化后,可以使用其属性,实际上,创建一个类之后,可以通过类名访问其属性。
类的方法与普通的函数只有一个特别的区别——它们必须有一个额外的第一个参数名称, 按照惯例它的名称是 self。
obj.name
4.2 类的继承(单继承)
先找子类重写父类方法
#!/usr/bin/python3
#类定义
class people:
#定义基本属性
name = ''
age = 0
#定义私有属性,私有属性在类外部无法直接进行访问
__weight = 0
#定义构造方法
def __init__(self,n,a,w):
self.name = n
self.age = a
self.__weight = w
def speak(self):
print("%s 说: 我 %d 岁。" %(self.name,self.age))
#单继承示例
class student(people):
grade = ''
def __init__(self,n,a,w,g):
#调用父类的构函
people.__init__(self,n,a,w)
self.grade = g
#覆写父类的方法
def speak(self):
print("%s 说: 我 %d 岁了,我在读 %d 年级"%(self.name,self.age,self.grade))
s = student('ken',10,60,3)
s.speak()
super() 函数是用于调用父类(超类)的一个方法。
super(Child,c).myMethod() #用子类对象调用父类已被覆盖的方法
super() 是用来解决多重继承问题的,直接用类名调用父类方法在使用单继承的时候没问题,但是如果使用多继承,会涉及到查找顺序(MRO)、重复调用(钻石继承)等种种问题。
4.2 类的继承(多继承)
class DerivedClassName(Base1, Base2, Base3):
<statement-1>
.
.
.
<statement-N>
4.3 类属性与方法
__private_attrs:两个下划线开头,声明该属性为私有,不能在类的外部被使用或直接访问。在类内部的方法中使用时 self.__private_attrs。
关注我,后续继续追加,认为重要的基础知识!