层次聚类-Hierarchical Clustering
一、概述
层次聚类(Hierarchical Clustering)是聚类算法的一种,通过计算不同类别数据点间的相似度来创建一棵有层次的嵌套聚类树,距离越小,相似度越高。在聚类树中,不同类别的原始数据点是树的最低层,树的顶层是一个聚类的根节点。创建聚类树有自下而上合并和自上而下分裂两种方法,这两种方法分别称为聚类与分裂。
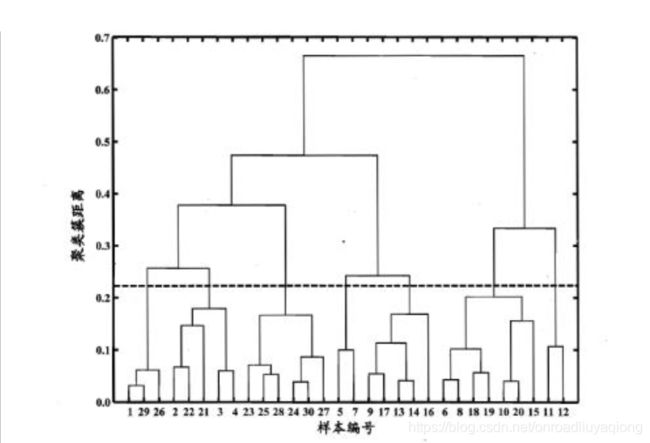
1)、自下向上的聚类方法(凝聚分层聚类)
算法思想:
将每个点都看成一个簇;
将两个最近的簇合并为一个簇;
不断重复上述过程,直到达到预期簇或簇之间的距离满足要求为止(指定簇数或样本距离阈值)。
2)、自上向下的聚类方法
算法思想:
将样本的每个点都看成一个簇;
然后找出簇中距离最远的两个簇进行分裂;
不断重复到预期簇或者满足终止条件为止(指定簇数或样本距离阈值)。
具体计算方式参考链接:
https://blog.csdn.net/u012500237/article/details/65437525
二、相似度/距离计算
单连接(single linkage):计算每一对簇中最相似两个样本的距离,并合并距离最近的两个样本所属簇;
全连接(complete linkage):通过比较找到分布于两个簇中最不相似的样本(距离最远),从而来完成簇的合并;
平均连接(average linkage):合并两个簇所有成员间平均距离最小的两个簇;
ward连接:合并的是使得SSE增量最小的两个簇;
三、优缺点
1、优点
1)它一次性地得到了整个聚类的过程,只要得到了上面那样的聚类树,想要分多少个cluster都可以直接根据树结构来得到结果,改变 cluster数目不需要再次计算数据点的归属;
2) 在聚类形状方面,层次聚类适用于任意形状的聚类,并且对样本的输入顺序是不敏感的。
2、缺点
1)计算时间复杂度大,因为要每次都要计算多个cluster内所有数据点的两两距离;
2)由 于层次聚类使用的是贪心算法,得到的显然只是局域最优,不一定就是全局最优,这可以通过加入随机效应解决(有另外的问题);
3) 层次聚类过程最明显的特点就是不可逆性,一旦聚类结果形成,想要再重新合并来优化聚类的性能是不可能的了;
4) 聚类终止的条件的不精确性,层次聚类要求指定一个合并或分解的终止条件,比如指定聚类的个数或是两个距离最近的聚类之间最小距离阈值。
四、代码实现以及高维数据可视化
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import scipy.cluster.hierarchy as sch
import scipy.spatial.distance as ssd
from scipy.cluster.vq import vq,kmeans,whiten
import numpy as np
import scipy
from sklearn.metrics import silhouette_score
from sklearn.preprocessing import StandardScaler
df=pd.read_excel(r'D:\机器学习\数据\data.xlsx')
data=StandardScaler().fit_transform(df)
dismat=sch.distance.pdist(data,'euclidean') #用欧式距离生成点与点之间的距离矩阵
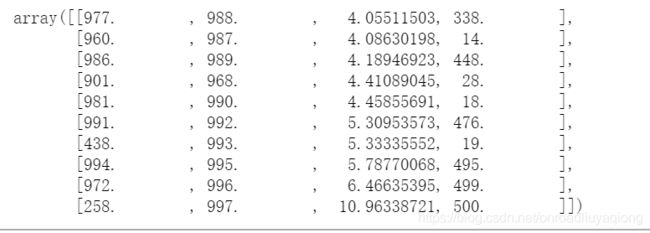
Z=sch.linkage(dismat,method='average') #进行层次聚类
Z[-10:] #每一行的格式是这样的[idx,idx2,dist,sample_count]
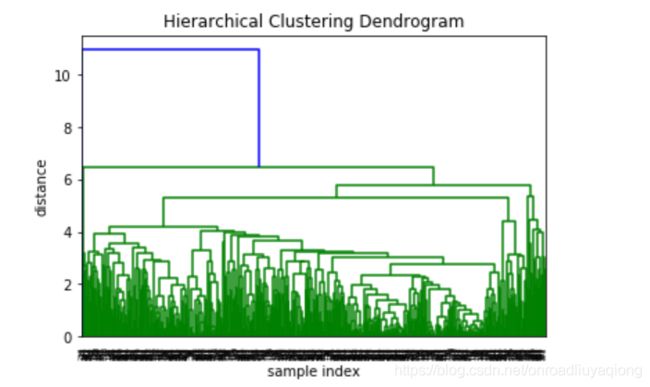
plt.title('Hierarchical Clustering Dendrogram')
plt.xlabel('sample index')
plt.ylabel('distance')
P=sch.dendrogram(Z) #将层次聚类结果以树状图表示并保存
plt.savefig('plot_dendrogram.png')
plt.show()
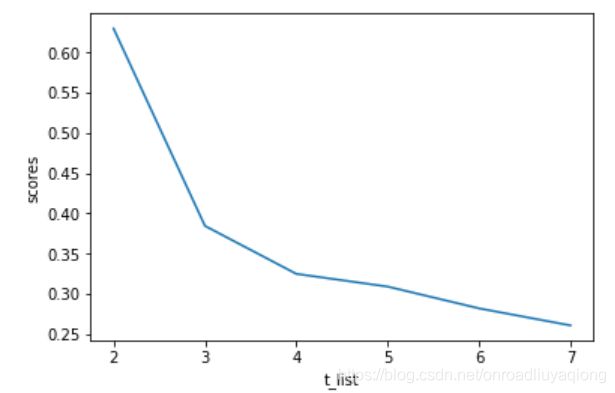
t_list=[2,3,4,5,6,7]
scores=[]
for i in range(len(t_list)):
cluster=sch.fcluster(Z,t=t_list[i],criterion='maxclust')
score=silhouette_score(data,cluster)
scores.append(score)
plt.plot(t_list,scores)
plt.xlabel('t_list')
plt.ylabel('scores')
plt.show()
cluster=sch.fcluster(Z,t=3,criterion='maxclust')
print('Original cluster by hierarchy clustering:/n',cluster)
score=silhouette_score(data,cluster)
print('轮廓系数是:',score)

df['cluster']=cluster #将聚类结果并入数据集
pd.set_option('display.max_rows',None)
import sklearn
from sklearn.manifold import TSNE
import seaborn as sns
#高维数据可视化------tsne实现
tsne=TSNE(random_state=50).fit_transform(df)
print(tsne.shape) #结果为(500, 2)
df_tsne=pd.DataFrame(tsne,index=df.index)
#数据可视化实现
plt.rcParams['font.sans-serif']=['SinHei']
plt.rcParams['axes.unicode_minus']=False
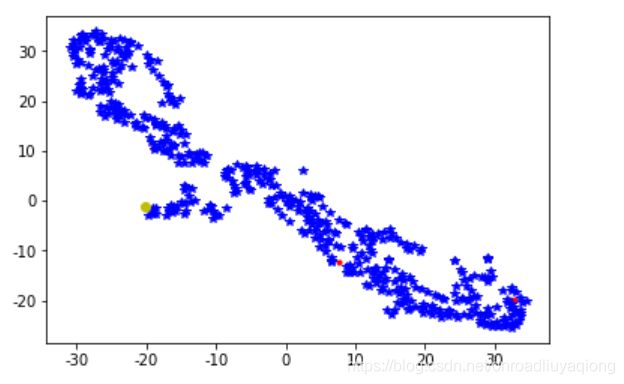
d1=df_tsne[df['cluster']==1]
d2=df_tsne[df['cluster']==2]
d3=df_tsne[df['cluster']==3]
plt.plot(d1[0],d1[1],'r.',d2[0],d2[1],'b*',d3[0],d3[1],'yo')
plt.show()