一点就分享系列(理解篇_4+实践篇_2)”干货-全网最简且全”的理解!2020年了!您只知道GAN?ECCV超分论文“IRN” 全家桶大放送!!
一点就分享系列(理解篇_4+实践篇_2)”最新干货”——2020 ECCV 超分论文之一“IRN”(更新中。。)
最近开始了csdn坚持原创之旅,目前到了理解篇3 ,本意是想讲CNN网络目前的sota级算法设计,因时间原因我还需要理解学习,故先来点不一样的东西,偶然看到相关资料,实在是非常兴奋!理解篇的初衷就是通俗易懂!这也是本系列的特点,因为目前的sota模型都建立于之前的研究成果上,所以直接看狠容易存在知识断层,现在很多人使用DL作为工具因其可解释性差,难道理论上您还想有”黑盒“存在吗?所以想呈现一些理解,共同研究,共同进步!看到很多Paper实在没忍住,连夜爆肝更新!!!所以。。都2020了,您不会只知道“GAN”“VAE”把? 没关系,最短时间让您看明白这个论文!!(后面会补充代码使用)
如果您完整阅读该篇,您会收获以下体验:
1.了解流模型的来源以及本质;推导过程,以及IRN的诞生始末;
2.流模型与GAN不同的原因;以及经典的计算解读和trick!
3.通俗易懂的流模型缩放过程解说;
4.IRN代码的使用版本说明,以及修改过好的测试脚本(更新中);
5.最重要的!即使有知识断层也可轻松阅读;
文章目录
- 一点就分享系列(理解篇_4+实践篇_2)”最新干货”——2020 ECCV 超分论文之一“IRN”(更新中。。)
- IRN“背景调查”
- 一、流模型本质解密!
- 二、坚定信念-生成模型的特点和难处!
- 三、传承不息——”分块耦合“
- 四、主角”IRN“闪亮登场——“流程解说”1
- 五 网络正向和反向输出 ——”流程解说”2
- 六 IRN的代码工程使用说明
-
- 1.使用简述
- 2.推理部分
- 3.反向操作上采样
- 4.上采样调用代码
- 六 个人心得和结语
IRN“背景调查”
代码链接,没必要贴论文了,为什么????????因为看论文你会有很多知识断层,所以听我白话叙述不好嘛?
该网络源于2020ECCV的一篇超分辨方向的论文,一种可逆的缩放网络(Invertible Rescaling Net, IRN),从新的角度(可逆双射变换)建模降尺度和升尺度过程来大大缓解图像升尺度的不适应问题!!!!
说白了!!!!!!这就是一种对图像压缩还原保真的算法!比如,压缩图像、节省带宽、适配不同分辨率的屏幕媒体传输视频,因需要压缩去适应各个显示器,但是恢复原始的分辨率或放大图像中的细节,会丢失掉细节(高频信息)!这个算法就是帮你更好的还原!接下来呢,为了让大家伙更深刻明白,我们需要介绍下相关的论文模型等背景知识,又可以免费学知识了!因为很有必要普及,不然我直接码点论文解释,关键点读者们不明白有什么意义呢?
每个人都有知识盲区,不必在意!!!!
废话不多说, 先盗个图再说!!!图是基于OpenAI的“FLOW流模型”生成的,对它和GAN“生成 对抗“的思路不同,flow 就是想办法得到一个 encoder 将输入 x 编码为隐变量 z,并且使得 z 服从标准正态分啊。
得益于 flow 模型的精巧设计,这个 encoder 是可逆的,从而可以立马从 encoder(编码器)写出相应的decoder(生成器)出来,因此,只要 encoder 训练完成,我们就能同时得到 decoder,完成生成模型的构建。

一、流模型本质解密!
接着说,基于流生成模型,就是通过回归思想,确定了”潜在变量“去生成预测一个新目标!这就是似然估计的魅力!已经在视频图像编码上得到了很好的应用,对这就是FLOW 模型!!对该系列全部都是自回归的概率模型!
当然,今天的主角IRN"起源"也是这个流模型,而后Flow模型相继出了 NICE: Non-linear Independent Components Estimation和RealNVP等优秀的回归模型,始终如一,自成一派
NICE:论文链接,代码
二、坚定信念-生成模型的特点和难处!
它的核心就是拟合概率分布本身!为什么强调这个,有的朋友不明白,我们的CNN是拟合神器可以理解把?它可以说能去”拟合任意函数达到局部最优的结果“,而生成模型呢,它的目标是概率分布!为什么呢因为概率这个东西不能是负数把?且在0到1之间!条件性太强了!目的并不完全等同!
在分布研究中,图像是离散的,在并行大规模计算中太过笨重了!所以生成模型的研究者们用随机分布来描述图像,那么怎么做呢?
积分和高斯分布永远滴神!!!

好类 ,没必要继续讲下去, 你只要知道这个需要求q(x),真的不好求,没关系!您只需了解下面几点:
1)GAN是巧妙的躲避了这个问题,只优化上界去达到近似结果!
2)而FLOW比较耿直!它硬算!有兴趣的可以看下,没兴趣的跳过 知道即可!!FLOW求解推导过程
三、传承不息——”分块耦合“
为了更好地理解 IRN 网络,在上述的推导中,我们已经见证了完成了FLOW模型的诞生!那么问题又来了,这求逆是很难算的,数学上叫我们“转化!” 具体怎么转化的呢,这里必须要说下,为什么要推导这个?因为!算这个的过程需要”雅可比矩阵“,来将其转化成矩阵行列式计算,为什么?
雅克比矩阵有个重要的性质就是一个可逆函数(存在反函数的函数)的雅可比矩阵的逆矩阵即为该函数的反函数的雅可比矩阵,则Z在某邻域一点是可逆的,必可解!!!!!!!!!
三角形的行列式=对角线之和!!!!然后就解出了逆变换!就为了求解而已,就是一个现实版高数题!
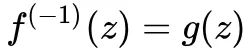
妙哉!妙哉!分而治之,请看FLOW二阶段进化的NICE网络的推导过程!NICE求解详细计算这个过程即”分块耦合“!!!
NICE模型仍旧是为了:对复杂的高维数据进行非线性变换,将高维数据映射到潜在空间,产生独立的潜在变量。这个过程是可逆的,即可以从高维数据映射到潜在空间,也可以从潜在空间反过来映射到高维数据!仍然是回归模型!
总之,后面的RealNVP也是继续延申了”分块耦合的操作“!进化了成了”仿射耦合“!!

通过以上叙述,您应该知道生成模型的推导!以及请回顾并记住一下,因为 这个也是我不推荐0基础的朋友看直接看IRN论文的原因!
1.生成模型的本质,模拟”潜在变量“去拟合概率分布的回归模型!
2.”分块耦合“的操作思想: 分而治之 !!!且在这个计算过程中,需要计算雅可比矩阵来辅助求得最终解!!
四、主角”IRN“闪亮登场——“流程解说”1
开头提过,我们讨论的IRN网络,实质就是为了解决图像还原的损失最小化(优化)的问题。具体流程,我会辅以解释,这里后面给出网络结构图!
先来简单说明下,论文中的Nyquist-Shannon采样定理,在缩小HR图像的过程中丢失的信息等于高频内容!哈哈,什么鬼?有兴趣的自己查查去,这里通俗简单的形式 ,给出一个结论理解即可!
首先我们采样图像等信号时候是连续的,而在计算机获取时候是离散的!所以,很明显信号状态由连续变为离散,这就会有损失了,那么损失误差是不是在容许的范围内,根据采样得到离散的点能不能还原出连续的信号?这就是该理论产生的原因,它就来帮助你解决这个问题!
该采样定理的结论是:找到信号最大的频率分量,再用2倍于最大频率分量的采样频率对信号进行采样,从理论上解决了,离散信号能够重建出连续信号的问题。
任何信号可以由若干个正弦信号加权叠加,实际上频率最高的正弦信号分量是我们所关注的,因为如果能把他采样出来,低频的正弦波分量就就更能了,而采样一个正弦波其实每个周期最少取两个点就够了,这样就能把正弦波还原回去(记住),这个“2”就是这样来的,所以极限状态就是那个最高频的正弦信号刚好采了两次,比他稍低的分量就两次多了,就有理论富余了。
采样定理1928年由美国电信工程师H.奈奎斯特首先提出来的,因此称为奈奎斯特采样定理。1933年由苏联工程师科捷利尼科夫首次用公式严格地表述这一定理,因此在苏联文献中称为科捷利尼科夫采样定理。1948年信息论的创始人C.E.香农对这一定理加以明确地说明并正式作为定理引用,因此在许多文献中又称为香农采样定理。
根据上述的采样定理,网络需要在缩小图像X前进行一次巧妙的分解,那么通过小波变换分解成高频和低频部分。。。。小波变换有不懂的?好吧,我也没系统学过,但是我可以简单解释下!先容我画个图!给你一个小波变换的操作,数学功底和美术底蕴有限!!!只为让你通俗理解!对小波变换具体原理想理解的 ,自行网上补课。
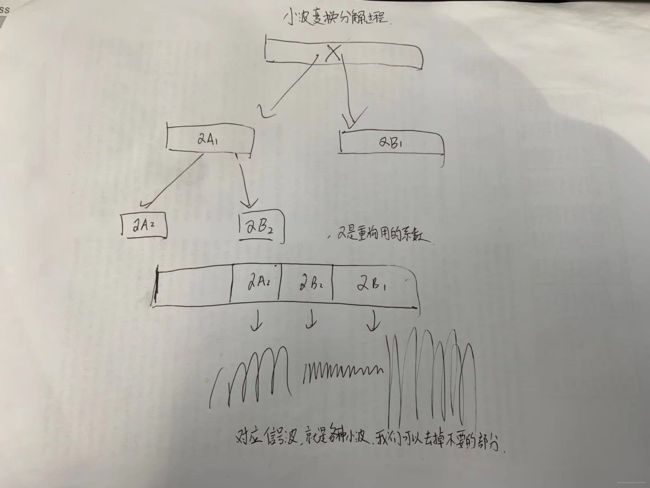
接着说,如下网络结构图,利用小波变换把原图X分解成如图4个分量,这4个分量分别对应高频分量XH,对应三个不同方向的高频分量H(水平)、V(垂直)、D(对角),低分部分XL,对应A。这里的低频分量与双线性插值降采样得到的低分辨率结果是一样的,而高频分量则是在降采样过程中被丢失的信息。然后关键点来了,分量进入了网络中,由堆叠的缩减模块组成,每个模块都包含一小波变换模块和几个可逆神经网络模块(InvBlocks),每个缩减模块将空间分辨率降低2倍。而这些INVBlocks就是来表示”潜在变量“的,熟悉不,嘿嘿,流模型的本质呢!
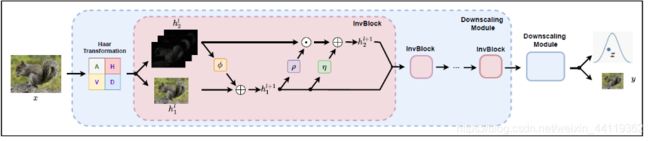
而该可逆神经网络模块中,核心操作就是我们之前提到耦合层,”分块耦合“!!哈哈,明朗了不?只是它这里采用了进化版本, Density estimation using Real NVP的仿射变换的耦合!下图就是NVP模型论文的正向缩小和反向放大的耦合原理!
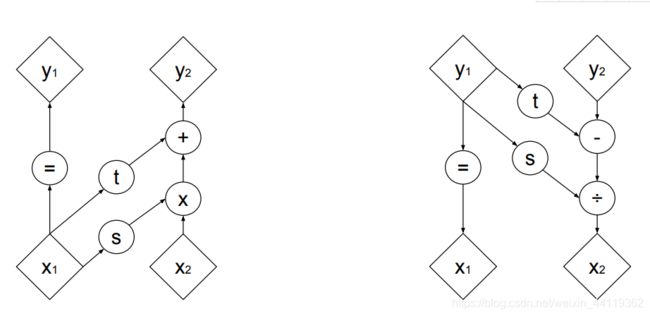
转换成公式就是很简单的一个仿射变换操作,其中里s,t 都是 x1 的向量函数,形式上第二个式子对应于 x2
的一个仿射变换,因此称为“仿射耦合层“!!!!!!!!

还记得不。需要求解雅可比矩阵转行列式计算哈,这里不再赘述了,这里稍微提一下,该耦合层的特点还有:通过随机的方式将向量打乱,可以使信息混合得更加充分,最终的 loss 可以更低!那么在图像中呢?在网络中图像是3个维度,宽和高属于空间维度,不可分割,而通道维度是唯一可以打乱的了!先盗个图!!!!!!说明!(这块不关心的 不会妨碍理解 可以跳到下一小节!往下拉,到第五节-流程解说2)
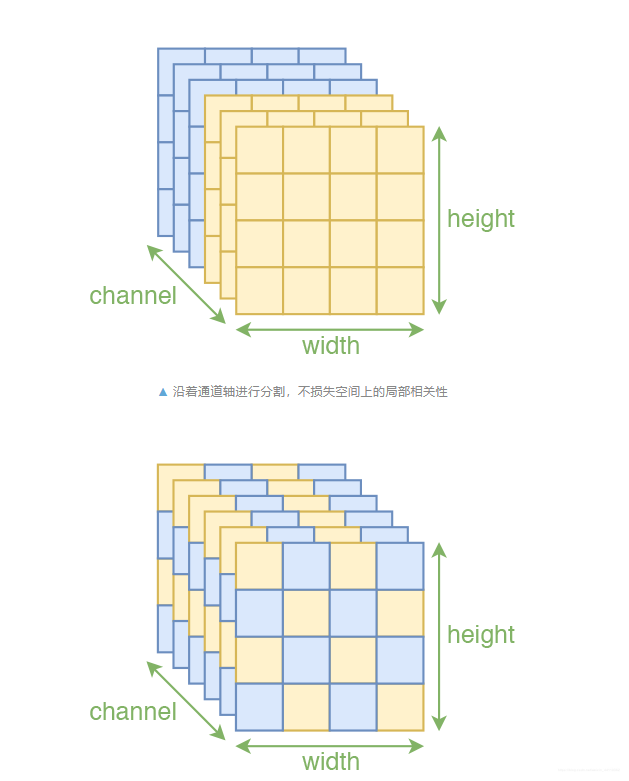
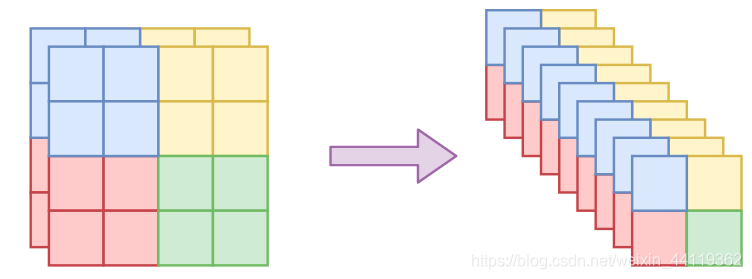
只对“通道”轴执行。也就是说,沿着通道将输入分割为 x1,x2 后,x1还是具有局部相关性的,还有沿着通道按着同一方式打乱整体后,空间部分的相关性依然得到保留,因此在模型 s,t 中就可以使用卷积了。这种特殊的分割也保留了空间局部相关性,论文中是两种 mask 方式交替使用的,但这种棋盘式 mask 相对复杂,也没有什么特别明显的提升,所以在 Glow 中已经被抛弃。不过想想就会发现有问题。一般的图像通道轴就只有三维,像 MNIST 这种灰度图还只有一维,怎么分割成两半?又怎么随机打乱?为了解决这个问题,RealNVP 引入了称为 squeeze 的操作,来让通道轴具有更高的维度。
以上只为理解思想,而最后在RealNVP中,使用了最终形态的打乱信息:squeeze 的操作,来让通道轴具有更高的维度。有了 squeeze 这个操作,我们就可以增加通道轴的维数,但依然保留局部相关性,从而我们前面说的所有事情都可以进行下去了,所以 squeeze 成为 flow 模型在图像应用中的必备操作,如下图!
五 网络正向和反向输出 ——”流程解说”2
哈哈,水了这么多!言归正传!!!!!!!!
1)回到网络正向传输缩小过程中,在通过可逆缩放网络Blocks后,生成了FLOW模型的必备可逆函数f,该函数由两部分表示,如图,我们所熟悉的”潜在变量“,它服从正态分布的变量Z,而产物图像y是一个新的图像。
2)而反过来逆放大过程中,通过可逆函数f,将y和Z拟合成新图X”!!
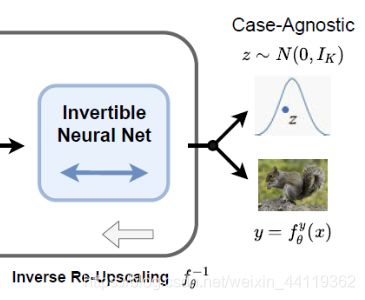
再来一个论文图加深理解!意思一样!其损失自然就是模拟分布重建图(sR)和原始(HR)X的损失了!
损失函数:采用重建损失,就是正向输出的缩小图y指导损失和分布匹配损失(逆转放大后的方法图X’’)的加权和。
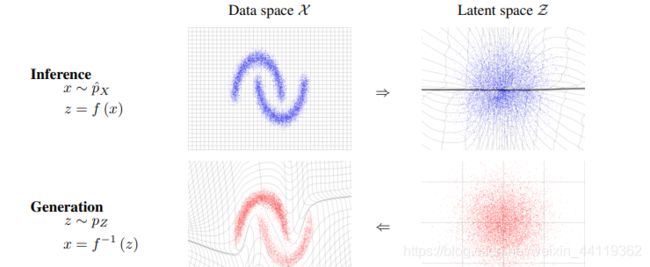
IRN论文实验图,结果很好,改善明显!IRN+:在IRN基础上加入感知损失!
六 IRN的代码工程使用说明
1.使用简述
首先您可以选择官方的代码链接,拉下来后,先确定环境保证运行.
以下是作者的环境要求,环境简单不多赘述!
需要注意的是:
python最好是3.6以上,torch的版本和cuda要对应,不然会报显卡驱动版本的错误!版本对应自行查阅torch官网
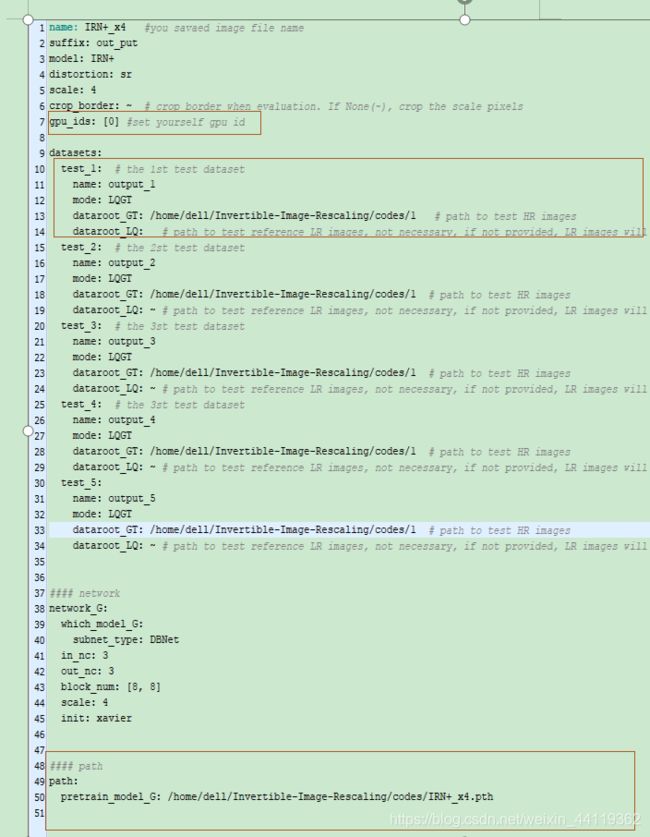
环境配置好后,接下来可以选择下载模型去测试也可以训练,在 工程目录下Invertible-Image-Rescaling/codes/options/test/ 中修改 “.yml” 后缀的配置文件,添加训练集和验证集的HR 图像与 LR 图像的存放路径,作者把训练和测试都分成了多份测试数据来生成。如下,我打开的是加了感知损失的IRN模型参数文件,这里的gpu_ids号要注意选择好。这些参数文件大致就是文件路径名称部分+网络参数初始化部分+模型路径。
框中标注的dataroot_GT是HR 图像的存放路径,dataroot_LQ可以提供,也可以不提供,执行test程序会自动生成对应的 LR 图像。
最后一行的path,为训练的模型路径。(在非官方的git代码里有训练好的模型)
在配置好的conda环境下,进入/codes文件下,配置好yml文件,运行测试命令:
python test.py -opt options/test/test_IRN+_x4.yml
同样,训练的参数文件和测试类似,不再赘述,在/Invertible-Image-Rescaling/codes/options/train/下 ,配置后数据和模型路径等,datarootGT还是必须有。(训练好的模型,训练好的模型网盘,提取码:spvp。)
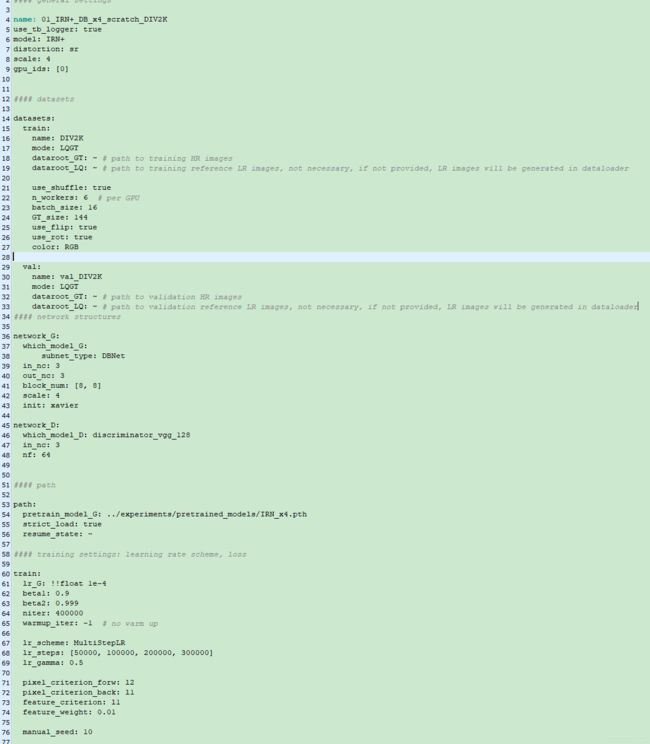
配置好后,在codes/下,运行训练命令,小伙伴可自行训练:
python train.py -opt options/train/train_IRN+_x4.yml
2.推理部分
我们先看下原版运行test.py的结果,按照代码解析yml的文件,推理会生成多个以"name"为名字的文件夹存放生成图像,在推理文件的参数填写时,结果存在results/下,连同log,并且程序运行中,还有统计PSNR和SSIM的生成图质量计算来量化评估模型推理效果。

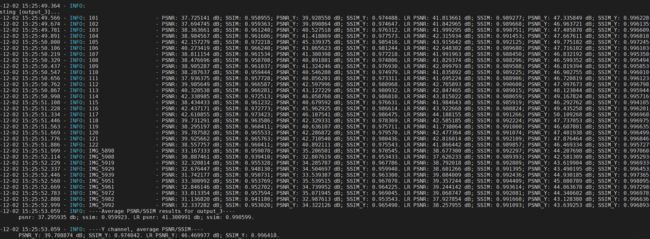
我的结果如下,这里解释下网络怎么做的,就和理论讲解网络结构时一样的,原图GT也是HR 缩放成了LR,再由LR,LR就是如下图:

然后LR 放大回SR,所以下面两个图谁是原图和生成图,分的清楚不?(第一个是GT ,第二个是SR)哈哈,简单来说实现完美的上采样还原图。

到这里就是网络推理的整个流程,可生成3类图片,有LR图,SR,以及LR的参考图,加上GT图 ,存在results下每帧4种图片。
3.反向操作上采样
如果当我们没有HR高清原始图如何操作呢???在该工程下因为脚本的编写原因直接改路径是不可行的,这里需要改一些源代码的推理部分,来实现,大致简单修改路径和图像张量的操作读取,以下代码和步骤参考:
首先,在Yml配置文件中确定2个数据路径,要上采样放大,LQ就是输入,GT有无均可,只是用来统计你SR超分图生成后和HR的PSNR等质量评测才能用到,这里具体操作可以,按照上步生成的LR图,来作为输入,生成SR图,而GT图在这里可以作为参考(非必要)。
拿到作为输入的LR压缩图

运行添加的Py代码(修改的脚本放在后面)
python demo.py -opt options/test/test_IRN+_x4.yml
scale设定4,生成SR超分图
4.上采样调用代码
demo.py 测试代码如下:(质量计算需要的可以自行修改,注意的点是2个图像尺寸相同才可以计算)
import os.path as osp
import logging
import time
import argparse
import torch
from collections import OrderedDict
import os
import numpy as np
import options.options as option
import utils.util as util
from data.util import bgr2ycbcr
import data.util as datautil
from data import create_dataset, create_dataloader
from models import create_model
import cv2 as cv
#environ["CUDA_VISIBLE_DEVICES"]="0"
#### options
def test_demo(opt):
util.mkdirs((path for key, path in opt['path'].items() if not key == 'experiments_root' and 'pretrain_model' not in key and 'resume' not in key))
util.setup_logger('base', opt['path']['log'], 'test_' + opt['name'], level=logging.INFO,screen=True, tofile=True)
logger = logging.getLogger('base')
logger.info(option.dict2str(opt))
device=torch.device('cuda')
model = create_model(opt)
#### Create test dataset and dataloader
#if(tag_inverse=="inverse")
#test_loaders = []
for phase, dataset_opt in sorted(opt['datasets'].items()):
test_set = dataset_opt['name']
# test_loader = create_dataloader(test_set, dataset_opt)
logger.info('Number of test images in [{:s}]: {:d}'.format(dataset_opt['name'], len(test_set)))
# test_loaders.append(test_loader)
#for test_loader in test_loaders:
#test_set_name = test_loader.dataset.opt['name']
logger.info('\nTesting [{:s}]...'.format(test_set))
test_start_time = time.time()
dataset_dir = osp.join(opt['path']['results_root'], test_set)
util.mkdir(dataset_dir)
#save image path
# print("dataset_dir:",dataset_dir)
test_results = OrderedDict()
test_results['psnr'] = []
test_results['ssim'] = []
test_results['psnr_y'] = []
test_results['ssim_y'] = []
# test_results['psnr_lr'] = []
# test_results['ssim_lr'] = []
# test_results['psnr_y_lr'] = []
# test_results['ssim_y_lr'] = []
#print("dataset list:",dataset_opt) #input path
#get image list
Path_input,s1izes=datautil.get_image_paths('img', dataset_opt['dataroot_LQ'])
Gt, s2 = datautil.get_image_paths('img', dataset_opt['dataroot_GT'])
# all_dict = {}
# all_dict.update(paths_LQ)
#print("image list:",Path_input)
len_List=len(Gt)
for i in range(len(Path_input)):
# print("input model tensor image :",Path_input[i])
input_im = cv.imread(Path_input[i],cv.IMREAD_COLOR)
input_im = input_im.astype(np.float32) / 255
gt_img=cv.imread(Gt[i])
#input_im = datautil.read_img(None, Path_input[i], None)
if opt['color']:
input_im = datautil.channel_convert(input_im.shape[2], opt['color'], [input_im])[0]
img_GT = datautil.channel_convert(gt_img.shape[2], opt['color'], [gt_img])[0]
if input_im.shape[2] == 3:
input_im = input_im[:, :, [2, 1, 0]]
gt_img=gt_img[:, :, [2, 1, 0]]
gt_img = torch.from_numpy(np.ascontiguousarray(np.transpose(gt_img, (2, 0, 1)))).float().unsqueeze(0)
input_im = torch.from_numpy(np.ascontiguousarray(np.transpose(input_im, (2, 0, 1)))).float().unsqueeze(0)
# model.feed_data() #LR 0r GT
# self.ref_L = data['LQ'].to(self.device) # LQ
#self.real_H = data['GT'].to(self.device) # GT
# img_path = data['GT_path'][0]
img_name = osp.splitext(osp.basename(Path_input[i]))[0]
img_name = img_name.split('_')[0]
#这里是用Model源码替换了
SR_img = model.upscale(input_im.to(device), opt['scale'])
sr_img = util.tensor2img(SR_img.detach()[0].float())
lrgt_img = util.tensor2img(input_im.detach()[0].float())
gt_img = util.tensor2img(gt_img.detach()[0].float())
# model.test()
# visuals = model.get_current_visuals()
# sr_img = util.tensor2img(visuals['SR']) # uint8
# #srgt_img = util.tensor2img(visuals['GT']) # uint8
# lr_img = util.tensor2img(visuals['LR']) # uint8
# lrgt_img = util.tensor2img(visuals['LR_ref']) # uint8
# if opt['color']:
# img_LQ = dutil.channel_convert(img_LQ.shape[2], opt['color'], [img_LQ])[0]
# # img_GT = dutil.channel_convert(img_GT.shape[2], opt['color'], [img_GT])[0]
# if img_LQ.shape[2] == 3:
# img_LQ = img_LQ[:, :, [2, 1, 0]]
# # img_GT = img_GT[:, :, [2, 1, 0]]
# img_LQ = torch.from_numpy(np.ascontiguousarray(np.transpose(img_LQ, (2, 0, 1)))).float().unsqueeze(0)
# # img_GT = torch.from_numpy(np.ascontiguousarray(np.transpose(img_GT, (2, 0, 1)))).float().unsqueeze(0)
# test_start_time = time.time()
# SR_img = model.upscale(img_LQ, opt['scale'])
# sr_img = util.tensor2img(SR_img.detach()[0].float().cpu())
# lrgt_img = util.tensor2img(img_LQ.detach()[0].float().cpu())
# save images
suffix = opt['suffix']
if suffix:
save_img_path = osp.join(dataset_dir, img_name + suffix + '_SR.png')
print(save_img_path)
#cv.imwrite("/home/dell/Invertible-Image-Rescaling/codes/image_out/"+img_name+".png",lrgt_img)
else:
save_img_path = osp.join(dataset_dir, img_name + '_SR.png')
util.save_img(sr_img, save_img_path)
# if suffix:
# save_img_path = osp.join(dataset_dir, img_name + suffix + '_GT.png')
# else:
# save_img_path = osp.join(dataset_dir, img_name + '_GT.png')
# util.save_img(srgt_img, save_img_path)
# if suffix:
# save_img_path = osp.join(dataset_dir, img_name + suffix + '_LR.png')
# else:
# save_img_path = osp.join(dataset_dir, img_name + '_LR.png')
# util.save_img(lr_img, save_img_path)
if suffix:
save_img_path = osp.join(dataset_dir, img_name + suffix + '_LR_ref.png')
else:
save_img_path = osp.join(dataset_dir, img_name + '_LR_ref.png')
util.save_img(lrgt_img, save_img_path)
# calculate PSNR and SSIM
# gt_img = util.tensor2img(visuals['GT'])
gt_img = gt_img / 255.
sr_img = sr_img / 255.
# lr_img = lr_img / 255.
# lrgt_img = lrgt_img / 255.
# crop_border = opt['crop_border'] if opt['crop_border'] else opt['scale']
# if crop_border == 0:
# cropped_sr_img = sr_img
# cropped_gt_img = gt_img
# else:
# cropped_sr_img = sr_img[crop_border:-crop_border, crop_border:-crop_border, :]
# cropped_gt_img = gt_img[crop_border:-crop_border, crop_border:-crop_border, :]
# psnr = util.calculate_psnr(cropped_sr_img * 255, cropped_gt_img * 255)
# ssim = util.calculate_ssim(cropped_sr_img * 255, cropped_gt_img * 255)
# test_results['psnr'].append(psnr)
# test_results['ssim'].append(ssim)
# # PSNR and SSIM for LR
# # psnr_lr = util.calculate_psnr(lr_img * 255, lrgt_img * 255)
# #ssim_lr = util.calculate_ssim(lr_img * 255, lrgt_img * 255)
# #test_results['psnr_lr'].append(psnr_lr)
# # test_results['ssim_lr'].append(ssim_lr)
# if gt_img.shape[2] == 3: # RGB image
# sr_img_y = bgr2ycbcr(sr_img, only_y=True)
# gt_img_y = bgr2ycbcr(gt_img, only_y=True)
# if crop_border == 0:
# cropped_sr_img_y = sr_img_y
# cropped_gt_img_y = gt_img_y
# else:
# cropped_sr_img_y = sr_img_y[crop_border:-crop_border, crop_border:-crop_border]
# cropped_gt_img_y = gt_img_y[crop_border:-crop_border, crop_border:-crop_border]
# psnr_y = util.calculate_psnr(cropped_sr_img_y * 255, cropped_gt_img_y * 255)
# ssim_y = util.calculate_ssim(cropped_sr_img_y * 255, cropped_gt_img_y * 255)
# test_results['psnr_y'].append(psnr_y)
# test_results['ssim_y'].append(ssim_y)
# #lr_img_y = bgr2ycbcr(lr_img, only_y=True)
# #lrgt_img_y = bgr2ycbcr(lrgt_img, only_y=True)
# # psnr_y_lr = util.calculate_psnr(lr_img_y * 255, lrgt_img_y * 255)
# #ssim_y_lr = util.calculate_ssim(lr_img_y * 255, lrgt_img_y * 255)
# #test_results['psnr_y_lr'].append(psnr_y_lr)
# #test_results['ssim_y_lr'].append(ssim_y_lr)
# logger.info(
# '{:20s} - PSNR: {:.6f} dB; SSIM: {:.6f}; PSNR_Y: {:.6f} dB; SSIM_Y: {:.6f}. '.
# format(img_name, psnr, ssim, psnr_y, ssim_y))
# else:
# logger.info('{:20s} - PSNR: {:.6f} dB; SSIM: {:.6f}'.format(img_name, psnr, ssim))
# Average PSNR/SSIM results
# ave_psnr = sum(test_results['psnr']) / len(test_results['psnr'])
# ave_ssim = sum(test_results['ssim']) / len(test_results['ssim'])
# ave_psnr_lr = sum(test_results['psnr_lr']) / len(test_results['psnr_lr'])
# ave_ssim_lr = sum(test_results['ssim_lr']) / len(test_results['ssim_lr'])
# logger.info(
# '----Average PSNR/SSIM results for {}----\n\tpsnr: {:.6f} db; ssim: {:.6f}. LR psnr: {:.6f} db; ssim: {:.6f}.\n'.format(
# test_set_name, ave_psnr, ave_ssim, ave_psnr_lr, ave_ssim_lr))
# if test_results['psnr_y'] and test_results['ssim_y']:
# ave_psnr_y = sum(test_results['psnr_y']) / len(test_results['psnr_y'])
# ave_ssim_y = sum(test_results['ssim_y']) / len(test_results['ssim_y'])
# ave_psnr_y_lr = sum(test_results['psnr_y_lr']) / len(test_results['psnr_y_lr'])
# ave_ssim_y_lr = sum(test_results['ssim_y_lr']) / len(test_results['ssim_y_lr'])
# logger.info(
# '----Y channel, average PSNR/SSIM----\n\tPSNR_Y: {:.6f} dB; SSIM_Y: {:.6f}. LR PSNR_Y: {:.6f} dB; SSIM_Y: {:.6f}.\n'.
# format(ave_psnr_y, ave_ssim_y, ave_psnr_y_lr, ave_ssim_y_lr))
if __name__ == '__main__':
print("Starting infer model....")
parser = argparse.ArgumentParser()
parser.add_argument('-opt', type=str, required=True, help='Path to options YMAL file.')
arg_opt = option.parse(parser.parse_args().opt, is_train=False)
# print(arg_opt);
opt = option.dict_to_nonedict(arg_opt)
test_demo(opt)
六 个人心得和结语
图像质量在目前的视频媒体应用领域,是迫切落地的需求,而该文章确实提供了一个优秀的理论模型和实用价值,但正如很多资深专家提到的,在专业处理中,图像质量这种效果一切服务于客户观感评价,我们需要系统性去解决问题!!比如,该模型还未融入编解码的图像质量评估;以及工业上要处理的落地硬需求,算法软硬件的配适,试想一个在采集设备成像的时候,我们可以有及时的预处理,比如去噪等,那么算法的处理相对是否不需要如此复杂?全面系统性解决问题,个人认为,是当前视频处理的重要思路。
如果耐心看完相信您一定明白了这个流模型的前世今生,而不是只知道IRN是个什么东西。。从始至终,这种最大似然估计的本质思想我举得非常简单易懂,不想多说了,通俗理解,是理解篇的初衷!!!!!仓促更新,如有错误,欢迎批评指正!您的关注是我更新分享的动力!