论文阅读笔记(二)【ACL2021】知识抽取NER
学习内容
- 由于刚刚进入知识图谱领域,对该领域的研究热点不是很了解,所以本文直接翻译ACL2021中关于知识抽取NER中各个论文的摘要和共享;
- 并且适时在最后写出自己的理解;
- 同时自己也会在了解完全部后给出各个论文的研究分类。
1. 题目: Improving Named Entity Recognition by External Context Retrieving and Cooperative Learning(利用外部上下文检索和合作学习改进命名实体识别)
Abstract
命名实体识别(NER)的最新进展表明,文档级上下文可以显著提高模型性能。但是,在许多应用程序场景中,这样的上下文不可用。在本文中,我们建议通过搜索引擎检索和选择一组语义相关的文本,以原始句子作为查询,来查找句子的外部上下文。我们从经验上发现,基于检索的输入视图(通过连接句子及其外部上下文构建)计算的上下文表示,与仅基于句子的原始输入视图相比,可以显著提高性能。此外,我们可以通过合作学习来提高两个输入视图的模型性能,合作学习是一种鼓励两个输入视图产生相似上下文表示或输出标签分布的训练方法。实验表明,我们的方法可以在5个域的8个NER数据集上实现最新的性能。
Introduction

Contribution
本文的贡献如下:
- 1.我们提出了一种简单而直接的方法,通过使用搜索引擎检索相关文本来改进输入句子的上下文表示。我们将检索到的文本与输入的句子一起作为一个新的基于检索的视图。
- 2.我们提出合作学习,在统一模型中共同提高两个输入视图的准确性。我们提出了两种分别基于 L 2 L_{2} L2范式和KL散度的CL方法。CL可以利用未标记的数据进行进一步的改进。
- 3.我们在5个领域的多个NER数据集中展示了我们方法的有效性,我们的方法达到了最先进的精度。通过利用大量未标记的数据,可以进一步提高性能。
关键词:文档上下文; 外部上下文;搜索引擎; transformer; CRF; 合作学习
Method
一个输入句子x被输入到搜索引擎中,以获得与k相关的文本。然后将相关文本输入重新排序模块。该框架选择从重新排序模块输出的 l l l个级别最高的相关文本,并将文本与输入句子一起提供给基于转换器的模型。最后,我们计算负似然损失 L C L − L 2 L_{CL-L_{2}} LCL−L2以及CL损失 L C L − K L L_{CL-KL} LCL−KL。其中CL表示的是协作学习的首字母缩写, v v v代表的是vector。使得两个视图之间不仅特征标记距离小; 而且使得预测的结果距离也小。 后面的 L N L L L_{NLL} LNLL则是负似然损失函数!
其中
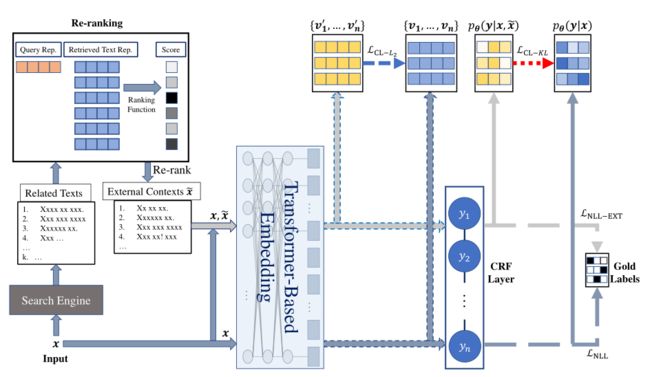
牵扯到的基本方法: Re-ranking; CRF(条件随机场); 一个CL损失,一个是负似然损失函数!
2. 题目:Locate and Label: A Two-stage Identifier for Nested Named Entity(定位和标记:用于嵌套命名实体识别的两阶段标识符)
作者: 沈永良(浙江大学计算机科学与技术学院)、马新音(中国科技大学)
Abstract
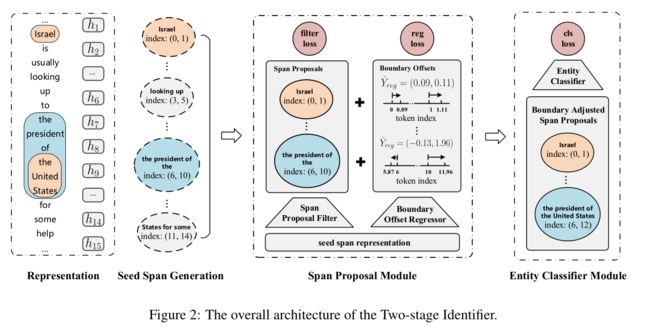
命名实体识别(NER)是自然语言处理中的一项研究热点。传统的NER研究只涉及平面实体,忽略了嵌套实体。基于跨度的方法将实体识别视为跨度分类任务。这些方法虽然具有处理嵌套NER的能力,但计算量大,对边界信息的忽略,对部分匹配实体的跨度利用不足,长实体识别困难。为了解决这些问题,我们提出了一种两阶段实体标识符。首先,我们通过对种子跨度进行过滤和边界回归来生成跨度建议,以定位实体,然后用相应的类别标记边界调整后的跨度建议。该方法在训练过程中有效地利用了实体和部分匹配跨距的边界信息。通过边界回归,理论上可以覆盖任意长度的实体,提高了识别长实体的能力。此外,在第一阶段中过滤掉许多低质量的种子跨度,降低了推理的时间复杂度。在嵌套的NER数据集上的实验表明,本文提出的方法优于现有的模型。
Introduction
下图解释什么叫平面实体和嵌套实体;

Contribution
我们将NER视为边界回归和跨度分类的联合任务
- 我们有效地利用边界信息。通过进一步识别实体边界,我们的模型可以调整边界以准确定位实体。在训练边界回归器时,除了边界级平滑L1损失外,我们还使用跨度级损失,用于测量两个跨度之间的重叠。
- 在训练过程中,我们不是简单地将部分匹配的跨度视为负面示例,而是基于IoU(交并比)构造软示例。这不仅缓解了正面和负面例子之间的不平衡,而且有效地利用了与基本真理实体部分匹配的跨度
- 实验结果表明,该模型在KBP17、ACE04和ACE05数据集上取得了一致的最新性能,在F1成绩上,该模型在KBP17、ACE04和ACE05数据集上的表现分别比同类基准模型好3.08%、0.71%和1.27%。
关键字:定位和标记;嵌套实体;跨度分类任务;长实体;两个阶段的实体标识符;边界;边界回归;
Method
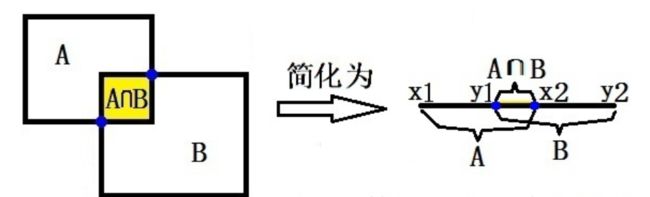
IoU: 交并比
交并比(Intersection-over-Union,IoU),目标检测中使用的一个概念,是产生的候选框(candidate bound)与原标记框(ground truth bound)的交叠率,即它们的交集与并集的比值。
最理想情况是完全重叠,即比值为1最理想情况是完全重叠,即比值为1
3. 题目:FEW-NERD: A Few-shot Named Entity Recognition Dataset(few-nerd:一个小样本的命名实体数据集)
作者: 宁定 ,徐光伟,陈玉林
作者单位:清华大学计算机科学与技术系,阿里巴巴集团,清华大学深圳国际研究生院
Abstract
最近,大量文献围绕着少样本命名实体识别(NER)这一主题展开,但很少有公开的基准数据专门关注这一实际且具有挑战性的任务。目前的方法是收集现有的有监督的NER数据集,并将其重新组织为少数镜头设置进行实证研究。这些策略通常旨在识别粗粒度的实体类型,示例很少,而在实践中,大多数看不见的实体类型都是细粒度的。在本文中,我们介绍了一个大规模的人类注释的小样本NERD数据集,它具有8种粗粒度和66种细粒度实体类型的层次结构。Few-NERD由来自维基百科的188238个句子组成,包含4601160个单词,每个单词都被标注为上下文或两级实体类型的一部分。据我们所知,这是前几次拍摄的NER数据集和最大的人类手工完成的数据集。我们构建了不同侧重点的基准任务来综合评估模型的泛化能力。大量的实证结果和分析表明,few-nerd具有挑战性,这个问题需要进一步研究。few-nerd公开在了github上
Few-NERD粗细粒度在下图中展示,其中内圈表示的是粗粒度,外圈是细粒度:

关键字: few-shot nerd; 粗细粒度; 最大的手工NERD数据集;
Contribution
- 提出了一个benchmark
4. 题目:MLBiNet: A Cross-Sentence Collective Event Detection Network(MLBiNet:一种跨句集合事件检测网络)
作者: 楼东方,廖志林
作者机构:浙江大学26 AZFT联合知识引擎实验室;浙江大学杭州创新中心
Abstract
我们考虑共同检测多个事件的问题,特别是在交叉语句设置中。处理这个问题的关键是对语义信息进行编码,并在文档级别对事件的相互依赖性进行建模。本文将其转化为Seq2Seq任务,提出了一种多层双向网络(MLBiNet)来同时捕获文档级的事件关联和语义信息。具体地说,在解码事件标记向量序列时,首先设计了一个双向解码器来模拟句子中的事件相互依赖关系。其次,使用信息聚合模块聚合句子级语义和事件标记信息。最后,我们堆叠多个双向解码器并提供跨句子信息,形成一个多层双向标记架构,以迭代地跨句子传播信息。我们表明,与当前最先进的结果相比,我们的方法在性能上有了显著的改进。
下表是ACE2005语料库跨句语义增强和事件相互依赖,具体来说,s2的语义信息提供了增强s3的潜在信息,s4中的攻击事件也有助于增强s3。

Contribution
我们在ACE 2005语料库上进行了实验研究,以证明其在跨句联合事件检测中的优势。我们的贡献总结如下:
- 我们提出了一种新的双向解码器模型,用于显式捕获句子中的双向事件相互依赖,缓解了传统标记结构的长距离遗忘问题;
- 我们提出了一个称为MLBiNet的模型,用于跨句子传播语义和事件相互依赖信息,并集体检测多个事件;
- 我们在ACE 2005语料库上取得了最好的性能(F1value),超过了最新水平1.9分。
关键字: 事件监测;交叉语句;语义信息;事件的相互依赖;双向解码器;信息聚合模块;
这里的事件是交叉语句中的事件,因为它们之间是有相互增强作用的;
总体就是用双向解码器来处理语义和交叉语句的事件关系,之后用信息聚合模块来聚合两方面的信息。
5. 题目:OntoED: Low-resource Event Detection with Ontology Embedding(OntoED:嵌入本体的低资源事件检测)
作者:邓淑敏( 浙江大学); 张宁豫(浙江大学);陈辉(阿里巴巴)
数据集及代码:https://github.com/231sm/Reasoning_In_EE
Abstract
事件检测(ED)旨在从给定文本中识别事件触发词,并将其分类为事件类型。目前大多数的事件关联方法严重依赖于训练实例,几乎忽略了事件类型之间的相关性。因此,他们往往遭受数据匮乏的困扰,无法处理新的看不见的事件类型。为了解决这些问题,我们将ED描述为一个事件本体填充过程:将事件实例链接到事件本体中预定义的事件类型,并提出了一个新的ED框架,名为OntoED 本体嵌入。我们通过事件类型之间的联系来丰富事件本体,并进一步归纳出更多的事件关联。基于事件本体,OntoED可以利用和传播相关知识,特别是从数据丰富到数据贫乏的事件类型。此外,通过建立与现有事件的链接,OntoED可以应用于新的不可见事件类型。实验表明,ONTED比以前的ED方法更具优势和鲁棒性,尤其是在数据稀缺的情况下。
下图是一个暴力和攻击被宣判的示例图,同时展示了事件监测中出现的问题:比如图中暴乱事件的规模在两种类型中相差甚远,在低资源情景中,监督ED模型容易过度拟合,因为他们需要所有事件类型的足够训练实例。另一方面,现实世界的应用程序往往是开放的,并且发展迅速,因此可能会有许多新的看不见的事件类型。处理新的事件类型甚至可能需要重新开始,而不能重复使用以前的注释。

Contribution
我们的贡献可以概括如下:
- 我们研究低资源事件检测问题,提出了一种基于本体的新模型,OntoED,它编码事件的内部和内部结构;
- 本文提出了一种基于本体嵌入事件关联的ED框架,该框架将符号规则与流行的深部神经网络进行相互操作;
- 本文针对ED建立了一个新的数据集OntoEvent,实验结果表明,该模型在整体、少镜头和零镜头设置方面都能取得较好的性能。
关键词:事件监测(ED);资源不足;事件触发词; 事件类型之间的相关性; 事件本体填充;
本文重点解决的就是低资源场景下事件类别之间的隐含关联;事件本体填充的意思就是初始的事件本体包含孤立的事件类型和事件实例,这一步就是为了建立起事件类型和事件实例的初始关联,并建立起事件实例之间的联系。
6. 题目:BERTifying the Hidden Markov Model for Multi-Source Weakly Supervised Named Entity Recognition(多源弱监督命名实体识别的隐马尔可夫模型的改进)
作者:李英豪(乔治亚理工学院,美国亚特兰大);
代码: github.com/Yinghao-Li/CHMM-ALT
Abstract
我们研究的问题,使用来自多个弱监督源的噪声标签学习命名实体识别(NER)标记器。尽管获取成本低廉,但来自薄弱监管来源的标签往往不完整、不准确、相互矛盾,因此很难学习准确的NER模型。为了应对这一挑战,我们提出了一种条件隐马尔可夫模型(CHMM),该模型能够以无监督的方式从多源噪声标签中有效地推断出真实标签。CHMM利用原来训练好的具有语境表征能力的语言模型的力量增强了经典的隐马尔可夫模型。具体地说,CHMM从输入标记的BERT嵌入中学习标签转换和排放概率,从而从嘈杂的观察中推断出潜在的真实标签。我们通过另一种培训方法(CHMMAT)进一步完善了CHMM。它使用CHMM推断的标签微调BERT-NER模型,该BERTNER的输出被视为训练CHMM的附加弱源。在不同领域的四个NER基准测试上的实验表明,我们的方法比最新的弱监督NER模型有很大的优势。
Contribution
我们的贡献包括:
- 一个多源标签聚合器CHMM,具有令牌转换和发射概率,用于聚合来自不同弱标签源的多组NER标签
- 一种交替的训练方法CHMM-ALT,该方法依次训练CHMM和BERT-NER,利用彼此的多回路输出优化
- 多源弱监督NER性能对来自不同领域的四个NER基准的综合评估表明,CHMM-ALT与最强的基线模型相比,F1平均得分提高了4.83。
关键词: 弱监督源; 噪声标签; 条件隐藏式的马尔可夫模型; 真实标签;多元标签聚合器;交替训练;改进BERT-NER
弱监督学习: 链接
南京大学周志华教授在2018年1月发表了一篇论文,叫做《A Brief Introduction to Weakly Supervised Learning》,弱监督学习是相对于全部真值标签这样的强监督信息而言的,什么是弱监督学习呢?文章里说,弱监督学习可以分为三种典型的类型,不完全监督(Incomplete supervision),不确切监督(Inexact supervision),不精确监督(Inaccurate supervision)。
7. 题目: Document-level Event Extraction via Heterogeneous Graph-based Interaction Model with a Tracker(基于异构图交互模型和跟踪器的文档级事件提取)
作者: 徐润欣(北京大学计算语言学重点实验室,中国教育部);常宝宝(北京大学计算语言学重点实验室,中国教育部,中国深圳彭城实验室)
代码:https://github. com/RunxinXu/GIT
Abstract
文档级事件提取旨在识别整篇文章中的事件信息。由于该任务的两个挑战,现有的方法并不有效:a)目标事件参数分散在句子中;b) 文档中事件之间的关联对于模型来说是非常重要的。在本文中,我们提出了基于异构图的带有跟踪器的交互模型(GIT)来解决上述两个难题。对于第一个挑战,GIT构建了一个异构图交互网络来捕获不同句子和实体提及之间的全局交互。对于第二种情况,GIT引入了一个跟踪模块来跟踪提取的事件,从而捕获事件之间的相互依赖关系。在大规模数据集上的实验(Zheng et al.,2019)表明,GIT的性能比以前的方法好2.8倍。进一步的分析表明,GIT可以有效地提取分散在文档中的多个相关事件和事件参数。
下图展示了提出文档级事件的两个难点:
第一,图1显示了一个示例,即实体降低权重(EU)和实体增加权重(EO)事件记录是从财务文档中提取的。提取EU事件的难度较小,因为所有相关论点都出现在同一句话中(第2句),然而,对于EO记录的论点,2014年11月6日出现在第1句和第2句中,而吴晓婷出现在第3句和第4句中。在不考虑句子和实体提及之间的全球互动的情况下,识别此类事件将是一个相当大的挑战。第二,一个文档可以同时表示多个相关事件,并且识别它们之间的相互依赖性是2021年5月31日成功开采的基础。如图1所示,这两个事件是相互依赖的,因为它们对应于完全相同的事务,因此共享相同的起始日期。对相关事件之间的这种相互依赖性进行有效建模仍然是这项任务的关键挑战。

Contribution
我们的贡献总结如下:
- 我们为文档级EE构建了一个异构图交互网络。通过不同的异构边缘,该模型可以捕获不同句子中分散事件参数的全局上下文
- 我们引入了一种新的跟踪模块来跟踪提取的事件记录。跟踪器简化了提取相关事件的难度,因为将考虑事件之间的相互依赖性
- 实验表明,在包含32040个文档的大规模公共数据集(Zheng等人,2019年)上,GIT的性能比之前的最新模型高出2.8 F1,特别是在跨句事件和多事件场景上(F1的绝对增长率分别为3.7和4.9)。
关键词: 文档级事件; 目标事件;事件之间的关联;异构图交互网络;句子和事件;全局交互; 跟踪模块;事件与事件;相互依赖;
8. 题目:LearnDA: Learnable Knowledge-Guided Data Augmentation for Event Causality Identification(LearnDA:用于事件因果关系识别的可学习知识引导数据扩充)
Abstract
事件因果关系识别的现代模型(ECI)主要基于监督学习,容易出现数据缺失问题。不幸的是,现有的NLP相关的增强方法无法直接生成此任务所需的可用数据。为了解决数据缺乏的问题,我们引入了一种新的方法,通过在双重学习框架中迭代生成新的示例并对事件因果关系进行分类,来增加事件因果关系识别的训练数据。一方面,我们的方法是知识引导的,它可以利用现有的知识库生成格式良好的新句子。另一方面,我们的方法采用了双重机制,这是一个可学习的扩充框架,可以交互地调整生成过程以生成任务相关句子。在两个基准EventStoryLine和 Causal-TimeBank上的实验结果表明:1)我们的方法可以为ECI增加合适的任务相关训练数据;2) 我们的方法在两个基准EventStoryLine和 Causal-TimeBank(F1值分别为2.5点和2.1点)方面优于以前的方法。
Introduction
下图解释了什么叫做ECI:
事件因果关系识别(ECI)旨在识别文本中事件之间的因果关系,这可以为NLP任务提供重要线索,如逻辑推理和问答。这个任务通常被建模为一个分类问题,比如确定句子中两个事件之间是否存在因果关系。例如,在图1中,ECI系统应该在两句话中识别两种因果关系:(1)attack ------》(cause)killed 在S1中;(2)statement--------》(cause)protests在S2中;但是现有的ECI都是基于带有注释的数据集的,数据集相对较小,这阻碍了高性能事件因果推理模型的训练;Easy data augmentation(EDA)数据增强方法是最具代表性的方法,它依赖词汇替换、删除、交换和插入来生成新数据。然而,仅仅依靠这些单词操作通常会产生新的数据,这些数据不符合任务相关的质量,如图1所示,S3由EDA生成,它缺少一个语言表达式来表达killed和attack之间的因果语义。因此,如何使用交互建模数据扩充和目标任务以生成具有任务相关特征的新数据是ECI面临的一个挑战性问题。

Contribution
综上所述,本文的贡献如下:
- 我们提出了一个新的可学习的数据扩充框架来解决ECI的数据缺失问题。我们的框架可以通过双重学习来利用识别和生成之间的双重性,这种双重学习可以学习为ECI生成任务相关句子;
- 我们的知识是可引导和学习的。具体来说,我们从KBs中引入因果事件对来初始化对偶生成,从而保证生成的因果句的因果关系。我们还采用约束生成结构,通过双重交互中的迭代学习,逐步生成形式良好的因果句;
- 在两个基准上的实验结果表明,我们的模型在ECI上取得了最好的性能。此外,它也显示出一定的优势,比以往的数据扩充方法。
关键词:事件因果关系识别(ECI);数据缺失;dual学习框架;迭代生成新的示例;知识引导;双重学习;因果事件对; 约束生成结构;
9. 题目:Named Entity Recognition with Small Strongly Labeled and Large Weakly Labeled Data(具有小的强地标记和大的弱地标记的数据的命名实体识别)
作者:江浩明(佐治亚理工学院,美国佐治亚州亚特兰大)
Abstract
弱监督在许多自然语言处理任务中显示出良好的效果,如命名实体识别(NER)。现有的工作主要集中在学习监督力度较弱的deep-NER模型,也就是没有任何人工注释,并且表明仅通过使用弱标记数据,可以获得良好的性能,尽管对于手动/强标记数据,性能仍然低于完全监督的NER。在本文中,我们考虑一个更实际的情况下,我们既有少量的强标记数据和大量的弱标记数据。不幸的是,我们观察到,当我们在强标记和弱标记数据的简单或加权组合上训练deep-NER模型时,弱标记数据不一定会改善甚至恶化模型性能(由于弱标记中存在大量噪声)。为了解决这个问题,我们提出了一个新的多阶段计算框架——NEEDLE ,它包含三个基本要素:(1)弱标记完成,(2)噪声感知损失函数,(3)强标记数据的最终微调。通过在电子商务查询引擎和生物医学引擎上的实验,证明了NEEDLE算法能够有效地抑制弱标签的噪声,并优于现有的方法。特别是,我们在3个生物医学NER数据集上获得了新的SOTA F1分数:BC5CDRchem 93.74,BC5CDR疾病90.69,NCBIdisease 92.28。
Contribution
我们将我们的主要贡献总结如下:
- 我们确定了一个关于弱监督的重要研究问题:在使用强标记和弱标记数据的简单或加权组合训练deep-NER模型时,弱标记数据的超大规模加剧了弱标记数据中的广泛噪声,并可能显著恶化模型性能。
- 我们提出了一个三阶段的计算框架,名为NEEDLE,以更好地利用超大弱标记数据的能力。实验结果表明,在电子商务查询NER任务和生物医学NER任务中,针头显著提高了模型的性能。特别是,我们在3个生物医学NER数据集上获得了新的SOTA F1分数:BC5CDR化学93.74,BC5CDR疾病90.69,NCBI疾病92.28。
关键字: 弱监督;强标记和弱标记组合;多阶段计算框架NEEDLE;噪声感知损失函数;
我们还将建议的框架扩展到多语言设置。
本文是弱监督中数据集是强标记和弱标记组合的。
10. 题目: PRGC: Potential Relation and Global Correspondence Based Joint Relational Triple Extraction(基于潜在关系和全局对应的联合关系的三重提取)
作者:郑恒义(深圳大学电子信息工程学院,深圳大学信息技术中心,腾讯贾维斯实验室,中国深圳)
Abstract
从非结构化文本中联合提取实体和关系是信息提取中的一项重要任务。最近的方法虽然取得了相当好的性能,但仍存在一些固有的局限性,如关系预测冗余、基于广度的提取泛化能力差以及效率低下。在本文中,我们从一个新的角度将该任务分解为三个子任务:关系判断、实体提取和主客体对齐,然后提出了一个基于潜在关系和全局对应的联合关系三重提取框架(PRGC)。具体来说,我们设计了一个预测潜在关系的组件,该组件将以下实体提取约束到预测的关系子集,而不是所有关系;然后,使用特定于关系的序列标记组件来处理主语和宾语之间的重叠问题;最后,设计了一个全局对应组件,将主体和对象对齐成一个低复杂度的三元组。大量实验表明,PRGC以更高的效率在公共基准上实现了最先进的性能,并在重叠三元组的复杂场景中提供了一致的性能增益。
Introduction
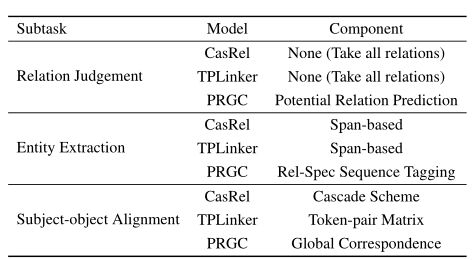
缺点:我们回顾了表中的两种端到端方法。对于名为CasRel的多任务方法,关系三重提取分两个阶段执行,将对象提取应用于所有关系。显然,识别关系的方法是冗余的,其中包含大量无效操作,基于跨度的提取方案只关注实体的开始/结束位置,导致泛化能力差。同时,由于其主客体对齐机制,它一次只能处理一个主题,效率低下且难以部署。对于单级命名为TPLinker的框架,为了避免主客体对齐中的曝光偏差,它利用了一个相当复杂的解码器,导致稀疏标签和低收敛速度,而基于跨度的提取的关系冗余和泛化能力差的问题仍然没有解决
Contribution
本文的主要贡献如下:
- 1.我们从一个新的角度处理关系三重提取任务,将任务分解为三个子任务:关系判断、实体提取和主客体对齐;在表1所示的建议范例的基础上,对以前的工作进行了比较;i)关系判断,旨在识别句子中的关系,ii)实体提取,旨在提取句子中的所有主语和宾语;iii)主语-宾语对齐,旨在将主语-宾语对对齐为三元组。
- 2.根据我们的观点,我们提出了一个新的端到端框架,并针对子任务设计了三个组件,大大缓解了冗余关系判断的问题,基于SPAN的提取泛化能力差,主客体对齐效率低。
- 3.我们在几个公共基准上进行了广泛的实验,这表明我们的方法达到了最先进的性能,特别是对于重叠三元组的复杂场景。进一步的烧蚀研究和分析证实了我们模型中每个组件的有效性。
- 4.除了更高的精度外,实验表明,与以前的工作相比,我们的方法在复杂度、参数数量、浮点运算(FLOPs)和推理时间方面具有显著的优势。
关键字: 非结构化文本;三元组(主语、关系、宾语);多任务学习;联合关系三重提取框架;预测潜在关系的组件;序列标记组件;全局对应组件;
11. 题目:CIL: Contrastive Instance Learning Framework for Distantly Supervised Relation Extraction(CIL:用于远程监督关系抽取的对比实例学习框架)
作者: 陈涛(浙江大学、阿里巴巴浙江大学前沿技术联合研究所)
Abstract
自从远程监督(DS)首次被引入关系提取(RE)任务以来,从远程监控(DS)生成的训练数据中减少噪声的旅程已经开始。在过去的十年中,研究人员应用多实例学习(MIL)框架从许多的句子中找到最可靠的特征。虽然MIL包的模式可以大大降低DS噪声,但它不能表示数据集中许多其他有用的句子特征。在许多情况下,这些句子特征只能通过额外的句子级人工标注来获得,代价很高。因此,远程监督RE模型的性能是有界的。在本文中,我们超越了典型的MIL框架,提出了一种新的对比实例学习(CIL)框架。具体而言,我们将初始MIL视为关系型三重编码器,并对每个实例的正对和负对进行约束。实验证明了我们提出的框架的有效性,在NYT10、GDS和KBP上比以前的方法有了显著的改进。
Introduction
关系抽取(relationextraction,RE)旨在根据实体的上下文预测实体之间的关系。提取的关系事实可以使各种下游应用程序受益。由于训练数据的数量通常限制了传统的有监督的RE系统,因此当前的RE系统通常采用远程监督(DS)来通过对齐知识库(KBs)和文本来获取丰富的训练数据。然而,这种启发式方法不可避免地会给生成的数据带来一些噪声。成为远程监督关系抽取(DSRE)的最大挑战。
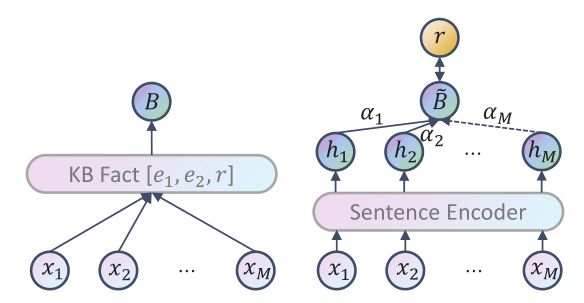
下图中展示了传统的MIL和改进后的MIL;
左侧是经典的MIL框架用在DSRE中, 通过将训练实例划分为多个包并使用包作为新的数据单元,句子都有相同的KB fact知识库[实体1, 实体2, 关系];
右侧则是在句子后面添加了注意力机制,从嘈杂的数据中形成精确表示的能力,MIL框架在bag level训练;
无论一个包包含多少实例,只有形成的包级别表示可以用于MIL中的进一步培训,这是非常低效的。
Contribution
因此,本文的主要贡献总结如下:
- 我们讨论了长期存在的MIL框架,并指出它不能有效地利用MIL包中的大量实例
- 我们提出了一种新的对比实例学习方法,以提高MIL框架下DSRE模型的性能
- 对保留集和人类注释集的评估表明,CIL比以前的SOTA模型有显著的改进。
关键词: 关系抽取(RE);远程监督(DS,被引入);DSRE;生成数据;MIL框架; 去除噪音;Beyond MIL的对比实例学习(CIL)框架; 关系三重编码器;约束正负对;有效利用;
补:1. bag-level = bag of words
词袋模型,我们将一个文档转化为多个词的结合;
同时一个bag就表示的是一种确切的关系类型; 比如两个实体之间就是出生地的关系;
链接地址
- 远程监督
该算法的核心思想是将文本与大规模知识图谱进行实体对齐,利用知识图谱已有的实体间关系对文本进行标注。远程监督基于的基本假设是:如果从知识图谱中可获取三元组R(E1,E2)(注:R代表关系,E1、E2代表两个实体),且E1和E2共现与句子S中,则S表达了E1和E2间的关系R,标注为训练正例;
12. 题目:SENT: Sentence-level Distant Relation Extraction via Negative Training(SENT:通过否定训练提取句子级距离关系)
作者: 马硕天(复旦大学计算机学院,中国上海),贵涛(复旦大学现代语言与语言学研究所,中国上海)
Abstract
关系提取的远程监控为包内的每个句子提供统一的包标签(bag labels ),而精确的句子标签对于需要精确关系类型的下游应用程序非常重要。直接使用袋子标签进行句子级训练将引入大量噪声,从而严重降低性能。在这项工作中,我们建议使用消极训练(NT),其中一个模型使用互补标签进行训练,即“实例不属于这些互补标签”。由于选择真实标签作为补充标签的概率较低,NT提供的噪声信息较少。此外,使用NT训练的模型能够将噪声数据从训练数据中分离出来。在NT的基础上,我们提出了一个句子级框架SENT,用于远距离关系提取。SENT不仅过滤噪声数据以构建更干净的数据集,还执行重新标记过程以将噪声数据转换为有用的训练数据,从而进一步提高模型的性能。实验结果表明,该方法在句子级评价和去噪效果上明显优于以往的方法。
Introduction
在MIL中,训练和测试过程在bag-level执行,其中包包含提及相同实体对但可能不描述相同关系的嘈杂语句。使用MIL的研究可大致分为两类:1)利用软权重区分每个句子影响的软去噪方法;2) 硬去噪方法,从袋子中去除嘈杂的句子。
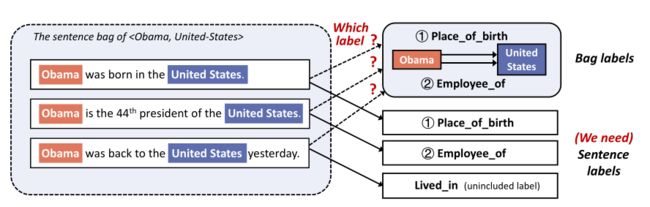
Bag-level labels存在的缺点:
bag-level labels中存在两种类型的噪音:1)Multi-label noise:每个句子的确切标签(“出生地”或“雇员”)不清楚;2) Wrong-label noise:包内的第三句话实际上表示“入住”,但不包括在包标签中。
Contribution
为了总结这项工作的贡献:
- 我们建议对句子级的DSRE使用消极训练,这大大保护了模型免受噪声信息的影响
- 我们提出了一个句子级框架SENT,其中包括一个噪音过滤和一个重新定义远距离数据的重新标记策略
- 与以往的方法相比,该方法在再利用性能和去噪效果方面都有了显著的改进。
关键词: 包标签;消极训练(NT);句子级框架SENT;噪声数据;重新标记;
13. 题目:A Span-Based Model for Joint Overlapped and Discontinuous Named Entity Recognition(基于Span的为了处理重叠和不连续命名实体识别的模型)
作者: 李飞(中国武汉大学网络科学与工程学院航天信息安全与可信计算教育部重点实验室)
季东红(中国天津大学新媒体与传播学院)
代码
Abstract
重叠和不连续命名实体识别的研究越来越受到人们的关注。以前的大多数工作都集中在重叠或不连续的实体上。在本文中,我们提出了一种新的基于跨度的模型,可以同时识别重叠实体和不连续实体。该模型包括两个主要步骤。首先,通过遍历所有可能的文本跨度来识别实体片段,因此,可以识别重叠的实体。其次,我们执行关系分类来判断给定的一对实体片段是重叠的还是连续的。这样,我们不仅可以识别不连续的实体,而且可以对重叠的实体进行双重检查。总体而言,我们的模型本质上可以看作是一种关系抽取范式。在多个基准数据集上的实验结果(CLEF、GENIA和ACE05)表明,我们的模型对于重叠和不连续的NER具有很强的竞争力。
Introduction
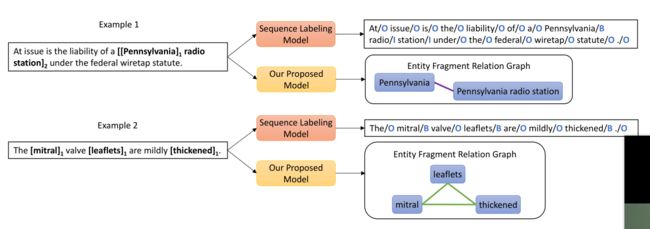
NER是NLP中的一项基本任务,因为它在信息提取和数据挖掘中有广泛的应用。传统上,NER是作为序列标记问题(sequence labeling)提出的,并由基于条件随机场(CRF)模型解决,但是不能处理重叠和不连续的实体。
例说明序列标记模型和基于跨度的模型之间的差异。在左边,标有相同编号的单词片段属于同一实体。在右侧,蓝色矩形表示已识别的实体片段,实线表示它们之间的连续或重叠关系(这两种关系相互排斥)。
关键字: 重叠和不连续的命名实体识别; 重叠的实体;不连续的实体;序列标记问题;CRF;基于跨度的模型;文本跨度;双重检查; 实体片段识别;片段关系预测;
14. 题目:Capturing Event Argument Interaction via A Bi-Directional Entity-Level Recurrent Decoder(通过双向实体级循环解码器捕获事件参数交互)
作者:于喜祥(北京大学软件工程国家工程研究中心)
代码:
Abstract
捕获事件参数之间的交互是实现健壮的事件参数提取(EAE)的关键步骤。然而,现有的这方面的研究有两个局限性:1)上下文实体的参数角色类型信息主要用作训练信号,忽略了直接将其作为语义丰富的输入特征的潜在优点;2) 参数级别的顺序语义意味着参数角色在事件提及上的总体分布模式,但没有很好地描述。为了解决上述两个瓶颈,我们首次将EAE形式化为类似Seq2Seq的学习问题,其中带有特定事件触发器的句子映射到一系列事件参数角色。提出了一种具有新的双方向的实体级别的重复解码器(BERD)的神经结构,通过结合上下文实体的参数角色预测(如逐字文本生成过程)来生成参数角色,从而更准确地区分事件中的隐式参数分布模式。
Introduction
EAE:事件参数提取(EAE)是事件提取(EE)的关键步骤,其目的是识别作为事件参数的实体,并对它们在事件中扮演的角色进行分类。
例如,鉴于“在巴格达,一名摄影师在美国坦克向巴勒斯坦酒店开火时死亡”一句中的“开火”一词触发了袭击事件,EAE需要确定“巴格达”、“摄影师”、“美国坦克”和“巴勒斯坦酒店”是与地点、目标、工具的争论,和目标分别作为角色。
关于EAE有两种范式,深度学习被广泛使用。本文中的第一个称为事件间参数交互,集中于在其他事件实例的上下文中挖掘目标实体(候选参数)的信息,比如在同一句话中,受害者对死亡事件的论点通常是攻击事件的目标论点的证据。
第二种是事件内参数交互,它利用目标实体与同一事件实例中其他实体的关系。本文重点讨论第二种范式。尽管已有的捕获事件内参数交互的方法取得了令人满意的结果,但它们存在两个瓶颈。
Contribution
本文的贡献在于:
- 1.首次将事件参数提取任务形式化为一个类似Seq2Seq的学习问题,其中具有特定事件触发器的句子映射到一系列事件参数角色。
- 2.我们提出了一种具有双向实体级循环解码器(BERD)的新型架构,该架构能够利用左侧和右侧上下文实体的参数角色预测,并区分参数角色的总体分布模式。
- 3.大量的实验结果表明,在广泛使用的ACE 2005数据集上,我们提出的方法优于几个有竞争力的基线。如果一句话中有更多的实体,BERD的优势就更为显著。
关键字: 事件参数提取; 参数角色;顺序语义;Seq2Seq;双方向的实体级别的重复解码器;深度学习;事件间参数交互; 事件内参数交互
Seq2Seq:Seq2Seq是encoder和decoder结构的; 主要用在机器翻译上;
15. 题目:Subsequence Based Deep Active Learningfor Named Entity Recognition(基于子序列的深度主动学习的命名实体识别)
作者: Puria Radmard(伦敦大学学院、剑桥大学、Vector AI)
代码: https://github.com/puria-radmard/RFL-SBDALNER
Abstract
主动学习(AL)已成功应用于深度学习,以大幅减少实现高性能所需的数据量。以前的工作表明,用于命名实体识别(NER)的轻量级体系结构仅需25%的原始训练数据就可以实现最佳性能。然而,这些方法没有利用语言的顺序性和每个实例中不确定性的异质性,需要对整个句子进行标记。此外,此标准方法要求注释者在标记时可以访问完整的句子。在这项工作中,我们通过允许AL算法查询句子中的子序列,并将它们的标签传播到其他句子来克服这些限制。我们在OnNotes5.0上实现了高效的结果,只需要原始训练数据的13%,而Conll2003只需要27%。与查询完整句子相比,这分别提高了39%和37%。
Introduction
在NLP中数据集是很重要的,但是标记的成本太高,一般人消受不起; 因此我们提出了主动学习,主动学习策略旨在通过自动识别大量未标记的数据中的最佳训练示例来有效地训练模型,这大大减少了人工注释的工作量,因为需要手动标记的实例要少得多。
Contribution
本文的主要贡献有:
- 1.通过允许查询完整句子的子序列,提高了AL-for-NER的效率;
- 2.基于实体的分析表明,子序列查询策略倾向于查询更多相关令牌(也就是属于实体的代币);
- 3.对完整句子和子序列查询方法进行的查询的不确定性分析,表明查询完整句子会导致选择更多模型已经确定的标记。
关键词: 主动学习(AL); 语言的顺序性; 访问完整的句子; 子序列; 传播;
16. 题目:Modularized Interaction Network for Named Entity Recognition(用于命名实体识别的模块化交互网络)
作者: 李飞(中国北京理工大学)、王铮(新加坡南洋理工大学)
代码:
Abstract
现有的命名实体识别(NER)模型虽然取得了良好的性能,但也存在一定的缺陷。基于序列标记的NER模型在识别长实体方面表现不佳,因为它们只关注单词级信息,而基于段的NER模型关注处理段而不是单个单词,无法捕获段内的单词级依赖关系。此外,由于边界检测和类型预测可能会在NER任务中相互协作,因此这两个子任务通过共享其信息来相互加强也很重要。在本文中,我们提出了一种新的模块化交互网络(MIN)模型,该模型利用了段级信息和词级依赖,并结合了一种交互机制来支持边界检测和类型预测之间的信息共享,以提高NER任务的性能。我们基于三个NER基准数据集进行了广泛的实验。性能结果表明,所提出的MIN模型优于目前最先进的模型。
Introduction
命名实体识别(NER)是自然语言处理(NLP)中的一项基本任务,它旨在发现和分类文本中命名实体的类型,如人员(PER)、位置(LOC)或组织(ORG)。它已广泛用于许多下游应用,如关系提取、实体链接、问题生成和共指消解。
目前,NER任务有两种类型的方法。第一种是基于序列标记的方法,其中一个句子中的每个单词都有一个特殊的标签(比如有GB-PER或IPER)。这种方法可以捕获相邻单词级标签之间的依赖关系,并在整个句子中最大化预测标签的概率。然而,NER是一项段级识别任务。因此,仅关注单词级信息的基于序列标签的模型在识别长实体方面表现不佳。最近,基于分段的方法因NER任务而广受欢迎。它们处理段(也就是多个单词的跨度)而不是单个词作为基本单位,并指定一个特殊的标签发送至各分部。由于这些方法采用段级处理,因此它们能够识别长实体。但是,段中的字级依赖关系通常被忽略。
Contribution
综上所述,本文的主要贡献包括:
- 我们提出了一种新的模块化交互网络(MIN)模型,该模型利用基于段的模型的段级信息和基于序列标记的模型的词级依赖性,以提高NER任务的性能所提出的MIN模型由NER模块、边界模块、类型模块和交互机制组成。
- 我们建议将边界检测和类型预测分为两个子任务,并结合交互机制以实现两个子任务之间的信息共享,从而实现最先进的性能我们在三个NER基准数据集(即CoNLL2003、WNUT2017和JNLPBA)上进行了大量实验,以评估所提出的MIN模型的性能。
- 实验结果表明,我们的MIN模型达到了最先进的性能,优于现有的基于神经网络的NER模型
关键字: 序列标记的NER;长实体;基于段的NER;单词间的依赖关系;边界检测和类型预测;相互协作;模块化交互网络;