【抗疫不出门】李宏毅教授机器学习课程笔记三——攻击和防御
这一讲是:Attack and Defense
视频地址
Attack讲的是如何攻击机器学习
Defense讲的是如何来抵御这个攻击
攻击是比较容易的(现有的很多机器学习模型都容易被攻击)。防御却比较困难(如何有效防御,还有很远的路要走)。
文章目录
- 1 动机
- 2 Attack
-
- 2.1 什么是机器学习攻击
- 2.2 Attack的损失函数和约束条件
-
- 2.2.1 损失函数
- 2.2.2 约束条件
- 2.3 如何解Attack这个优化问题
-
- 举个例子
- 试图解释原因
- 2.4 Attack的方法
-
- FGSM
- 2.5 白盒攻击 v.s. 黑盒攻击
-
- 怎样进行黑盒攻击
- 2.6 一些好玩的Attack研究
-
- universal adversarial attack
- adversarial reprogramming
- Attack in the Real World
- 除了图像攻击 也有语音和文字的攻击
- 3 Defense
-
- 3.1 被动防御
-
- 预处理:平滑
- 预处理:Feature Squeeze
- 预处理:加入随机的缩放和填充
- 被动防御小结
- 3.2 主动防御
-
- 主动防御小结
1 动机
为什么要研究攻击和防御?
比如垃圾邮件侦测的模型:制造垃圾邮件的人,希望能够攻击这个模型,骗过垃圾邮件侦测;而垃圾邮件侦测模型,也要具备防御这种攻击的能力。
机器学习模型只能够应对噪声是不够的,需要能够应对恶意的攻击。

2 Attack
大部分机器学习模型都很容易受到攻击。
2.1 什么是机器学习攻击
其实就是对抗样本(Adversarial Examples)的研究。
可以参考我之前的一篇博客:用GAN的方法来生成对抗样本
一个机器学习网络,可以识别猫咪 x 0 x^0 x0的类别;把猫咪图片加上特殊设计的扰动 Δ x \Delta x Δx,输入变成 x ′ = x 0 + Δ x x' = x^0 + \Delta x x′=x0+Δx,看似图片没有太大的变化,但是却使得机器学习网络把猫咪识别为其他东西。

2.2 Attack的损失函数和约束条件
2.2.1 损失函数
分为两种
- 有目标的攻击
- 无目标的攻击
网络训练的损失函数:使得输出 y 0 y^0 y0和真实标签 y t r u e y^{true} ytrue越接近越好。假设是one-hot的输出,训练时候的loss function可以是cross-entropy之类的函数。
L t r a i n ( θ ) = C ( y 0 , y t r u e ) L_{train}(\theta) = C(y^0,y^{true}) Ltrain(θ)=C(y0,ytrue).
无目标的攻击:使得输出的 y ′ y' y′和真实标签 y t r u e y^{true} ytrue越远离越好。因此无目标攻击的loss function就是负的网络训练时候loss function。
L ( x ′ ) = − C ( y ′ , y t r u e ) L(x') = -C(y',y^{true}) L(x′)=−C(y′,ytrue).
注意:
训练时候:输入 x x x是固定的,调整网络参数 θ \theta θ
攻击时候:网络参数 θ \theta θ固定,调整输入 x x x
有目标的攻击:使得输出的 y ′ y' y′是某个错误的标签 y f a l s e y^{false} yfalse,并且和真实标签 y t r u e y^{true} ytrue越远离越好。
L ( x ′ ) = − C ( y ′ , y t r u e ) + C ( y ′ , y f a l s e ) L(x') = -C(y',y^{true})+C(y',y^{false}) L(x′)=−C(y′,ytrue)+C(y′,yfalse).

2.2.2 约束条件
希望输入端的扰动越小越好,尽可能不要被发现。
d ( x 0 , x ′ ) ≤ ϵ d(x^0,x')\le\epsilon d(x0,x′)≤ϵ.
这个distance d d d如何定义?
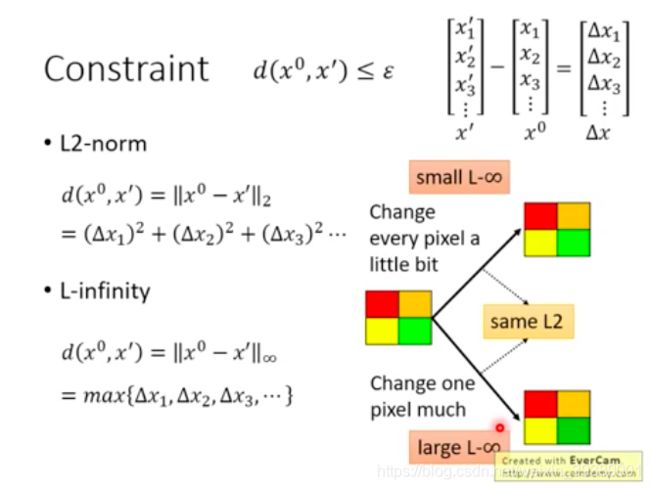
两个常见的例子是L2-norm和L-infinity 。定义在下图。
根据不同的任务,设计的distance应该不同。怎样设计能够达到对人来说感觉两者是很像的。
对于图像攻击来说,教授个人认为L-infinity比较合适,因为他做了一个实验。
对于下图中只有4个像素的图像,每个像素都是RGB三个值,一共12个元素来描述这个图。对这个图像进行一定的改变:上图是每一个像素都改变一点点;下图是指对其中右下角的元素进行了较大的改变。这两个改变后的图像和原图像的L2-norm距离是一样的。上图的L-infinity距离小,下图的L-infinity距离大。从肉眼观察看,好像下面那幅图确实是有明显的改变哦。所以用L2-norm来表征人眼观察下两个图像比较相似,好像不太合适。教授觉得L-infinity更能描述图像攻击任务中人眼对于相似度的判断。
2.3 如何解Attack这个优化问题
从上面的分析看出,attack其实就是解一个带约束的优化问题。
其实和训练一个神经网络的过程很像 只是一般训练NN时候是训练的网络参数 θ \theta θ,而现在则是训练输入数据 x ′ x' x′

可以先把约束条件去掉。用梯度下降法来进行求解。
首先初始化一个输入数据 x 0 x^0 x0;
然后迭代,每次更新的时候按照loss function梯度下降的方向前进一个 η \eta η。这时的梯度就是损失函数对于输入 x ′ x' x′的梯度咯。

然后再看把约束条件加上怎么处理。
用一个改版的梯度下降就行啦~~~
下面图示的这个改版的梯度下降法就是在每次更新 x x x的时候,加入一个判断,如果 x t x^t xt满足约束条件,就在下一时刻采用更新的 x t x^t xt,如果不满足约束条件,就加入一个函数来fix这个 x t x^t xt。
fix是一个函数,从满足约束条件的 x x x里面找到距离 x t x^t xt最近的那一个,作为下一时刻的更新。

对于L2-norm和L-infinity,对于超出约束条件的 x t x^t xt,如何在约束范围内找到满足条件的修正的 x t x^t xt,就是下图所示很好理解~

举个例子
用上面的简单方法试一试,看看能不能产生对抗样本
有目标的攻击 希望网络输出的错误类别是:键盘
攻击的网络是ResNet-50
下图可以看出,本来图像经过ResNet-50,判别是tiger cat,信心分数0.64;用上述攻击算法生成的图片人眼观察并没有什么差别,然而网络判断为keyboard,信心分数为0.98.

是不是这个网络比较挫呢?并不是
是因为我们加入的扰动是特殊设计的呢。如果随机加入一些扰动会怎样??
下图就是对这幅图随机加入了扰动噪声,噪声越来越大,ResNet-50识别结果从 tabby cat变成了Persian cat,最后噪声已经加的很大了,网络识别成了fire screen。

试图解释原因
输入数据 x 0 x^0 x0是很高维空间中的一个点。如果按照随机方向移动它,就可能是下图中top子图的样子,需要扰动很大,才可能让网络误判。
如果按照特殊方式进行攻击,就好像是找到了下图中bottom子图所示的一个维度。只要加入一点点扰动就使得网络判断错误。
真正的原因,还有待进一步研究解释!
另外并不是DNN才存在这样的易被攻击的特点,其他机器学习模型,如SVM,也有类似的情况。

2.4 Attack的方法
有下面很多文献

不同方法有什么差别呢?
其实所有的方法都是针对上述优化问题,采用了不同的优化算法,或者定义了不同的相似性约束而已。
课件只介绍了最简单最经典的一种Attack方法:FGSM
FGSM
首先:初始化一个 x 0 x^0 x0
然后:计算梯度,只保留符号(只关心梯度的方向,不关心梯度的大小)
最后:一次更新,就得到了攻击样本 x ∗ x^* x∗。
如下图所示,假设约束条件选择的是L-infinity。如果蓝色实线是梯度,那么按照梯度的相反方向,以 ϵ \epsilon ϵ大小一次更新到了 x ∗ x^* x∗就完成了。
(进阶版:可以多次迭代更新)

原理怎么理解?可以理解成:算法设置了一个很大的学习率,然后计算之后跑出了约束条件限制的区域(跑到了 x 1 x^1 x1),然后被拉回来就可以了。

2.5 白盒攻击 v.s. 黑盒攻击
上面的攻击是已知网络参数 θ \theta θ,来设计攻击样本 x ′ x' x′。属于白盒攻击。
是不是保护好网络参数不要被知道,就可以防御攻击了呢?
不是的,黑盒攻击(对方不知道我们的网路参数)也是可能的!

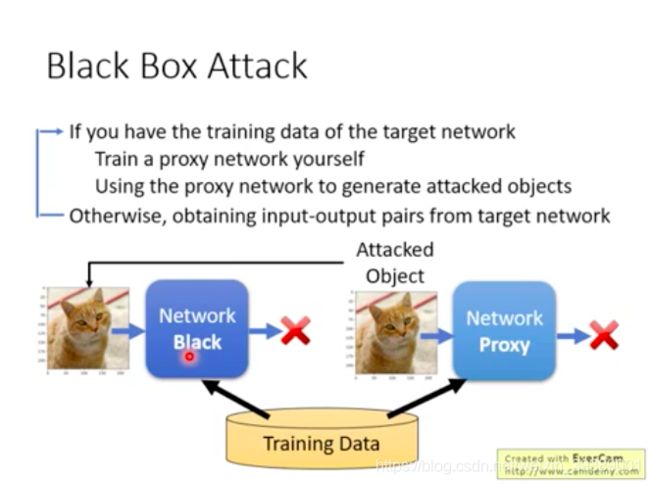
怎样进行黑盒攻击
-
如果你知道对方训练网络时采用的数据集,就可以自己用那些数据集来训练一个Proxy Network。针对自己训练的Proxy Network设计对抗样本,通常也能攻击成功对方的黑盒网络哦~~
-
保护好训练数据呢??仍然可以的。通过不断给黑盒网络输入数据,搜集输出数据。就得到了这个网络的很多输入-输出对。仍然可以训练一个Proxy Network。
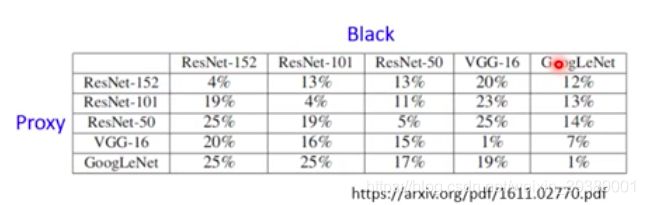
黑箱攻击有很大可能成功。看下面的例子,是采用Proxy网络来设计对抗样本,然后攻击黑盒后,黑盒的辨识的正确率。可以看出,如果两个网络一样那么攻击成功率就很高(黑盒辨识的正确率非常低)。如果两个网络不同,攻击成功率也还可以的。
2.6 一些好玩的Attack研究
universal adversarial attack
生成对抗样本时候,需要每个图片训练一下,得到最佳扰动量。每个输入的攻击图片都要单独计算。其实,还是有universal的对抗攻击方法的。比如下面这篇文献就设计了一种扰动量,对于数据集中的大部分图片,都能够产生攻击样本。而且还能做黑盒攻击。
这个好厉害!~~
universal adversarial attack文献地址

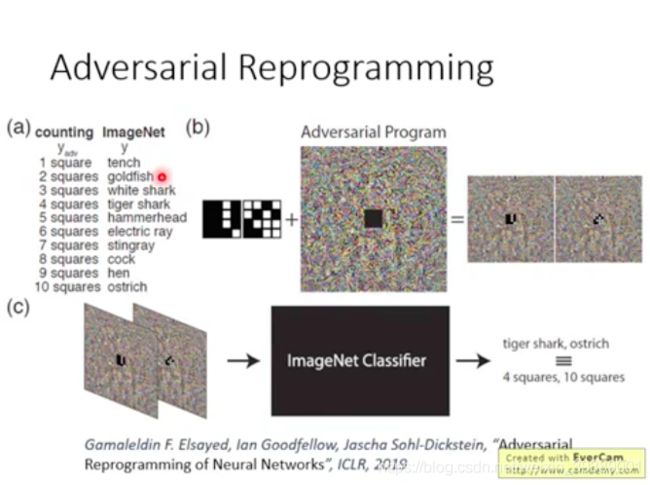
adversarial reprogramming
这个就很好玩,把原来的图像分类网络,加上Adversarial Program(就是一些噪声扰动),就可以让这个网络做别的事情。比如现在这个网络变成了可以数方块网络。几个方块就对应某个图像类别的输出。输入是有几个方块的图片,加上设计的扰动(Adversarial Program),再输入这个网络,类别值就对应了方块个数。
Attack in the Real World
物理世界中的攻击
1)研究时候加入的噪声比较小,物理世界中用照相机拍摄时候,这些噪声会不会太小而没办法起到作用?Ian Goodfellow这篇文章中研究用照相机去识别真实图片和对抗攻击的图片,依然可以成功。

2)对于人脸识别的门禁系统,想要入侵这个系统而把人脸上都加入噪声。。显然不合理。因此下面的研究是把扰动集中在了某个区域,比如戴上这一个特殊的眼镜,就可以使人脸识别系统判断错误。更牛x的是他们还真的设计出了这种眼镜!并且:多个角度都可以~~;确保扰动能够被对方的相机捕捉到;设计的扰动噪声的色彩是打印机能够打印出来的。

3)对于自动驾驶系统的攻击,把交通指示牌进行改变,使得自动驾驶系统会把它识别成错误的交通标志。这时需要保证改动不要太奇怪,比如就是贴几个小的patch就可以改变机器识别的结果。

除了图像攻击 也有语音和文字的攻击

3 Defense
人们可能认为,之所以有对抗样本是因为模型过拟合了。实际上并不是的。即使采用了一些防止过拟合的手段,如采用weight regularization,dropout,model ensemble都没有办法防御攻击。
model ensemble没有用是因为:attack并不是只对一个model有效,上面有一个黑盒的例子就看出来,attack可以成功攻击多个不同的model。
防御手段可分为:
- 被动防御:不对网络进行改变,另外加一个防御的东西。(可以看作是异常检测的特例。要找出异常的图片。 )
- 主动防御: 在训练模型时候就把攻击考虑进去。

3.1 被动防御
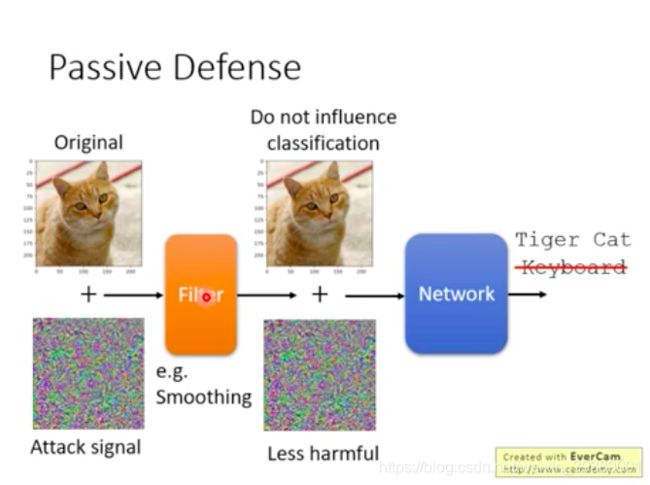
在Network前面加一个filter,使得加入的扰动对网络影响减小。
比如对图像进行平滑。
预处理:平滑
原因:上面有解释过为什么加入特定的扰动就使得机器误判,加入随机的扰动就需要加很多才能使得机器误判。可能是在某个特定的方向上才具有这种易被攻击的特征。对于对抗样本,加入平滑操作,可能改变了这个方向,因此机器就不会误判了。
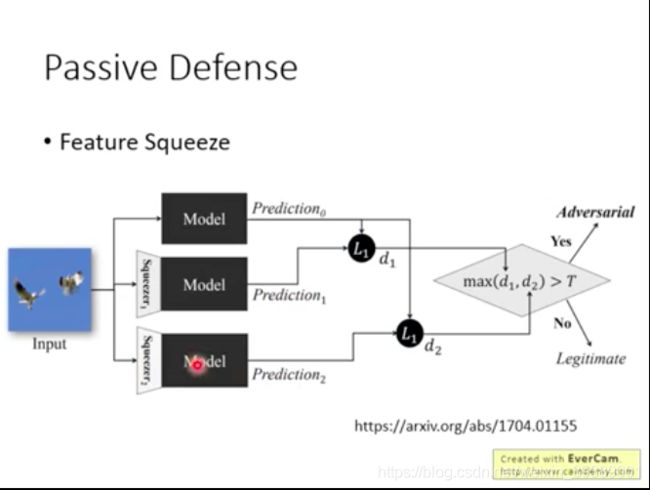
预处理:Feature Squeeze
图片直接输入模型来预测;
图片经过两种Squeeze之后,输入模型来预测;
比较直接输入模型和经过squeeze之后再输入模型,得到的预测结果的差距,如果差距过大,说明可能是对抗样本;如果差别小,可能就不是对抗样本。
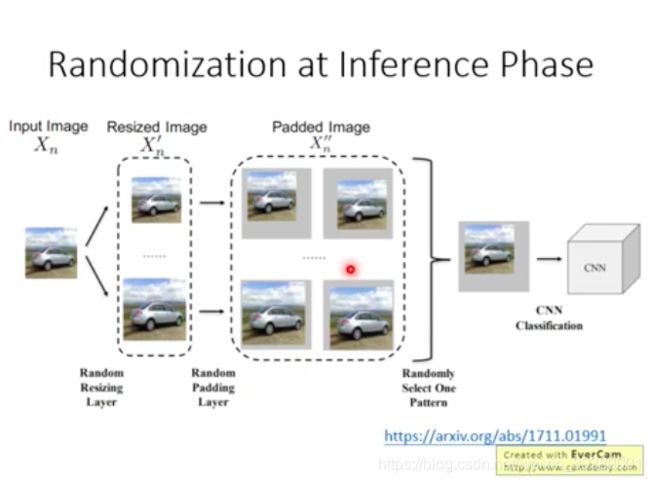
预处理:加入随机的缩放和填充
对图像进行缩放,再在周围加入一些类似噪声的padding。然后在输入模型来分类。可能能够防御攻击。
被动防御小结
- 不改变网络,而是在网络前面加入一些保护罩
- 设计的保护方法不能泄漏,否则被攻击者知道以后,仍然可以实施攻击。比如把前面的filter看作网络的第一层,就依然可以实施攻击。
3.2 主动防御
在网络模型设计时候就找出漏洞补起来。数据扩充,重新训练~~
对原始的数据集中的每一个图片都找出对抗样本(用某种对抗样本生成算法A),把这些对抗样本作为新的训练数据,标注上正确的label,来重新训练网络。类似于Data Augmentation。要训练很多轮哦。
如果攻击方用的是另一种攻击方法B,则仍然无法防御。

主动防御小结
- 不能让攻击方知道我们补充数据样本时是采用的那种攻击算法,否则攻击方更换攻击算法,就使得防御失效
- 防御仍然是难点