【动手学习pytorch笔记】24.门控循环单元GRU
GRU
序列中并不是所有信息都同等重要,为了记住重要的信息和遗忘不重要的信息,最早的方法是”长短期记忆”(long-short-term memory,LSTM),这节门控循环单元(gated recurrent unit,GRU)是一个稍微简化的变体,通常能够提供同等的效果, 并且计算的速度明显更快。
理论
两个门(和隐藏状态类似)
重置门(虫豸们~)
R t = σ ( X t W x r + H t − 1 W h r + b r ) R_t = \sigma(X_tW_{xr}+H_{t-1}W_{hr}+b_r) Rt=σ(XtWxr+Ht−1Whr+br)
更新门
Z t = σ ( X t W x z + H t − 1 W h z + b z ) Z_t = \sigma(X_tW_{xz}+H_{t-1}W_{hz}+b_z) Zt=σ(XtWxz+Ht−1Whz+bz)
候选隐状态
H t ~ = t a n h ( X t W x h + ( R t ⋅ H t − 1 ) W h h + b h ) \tilde{H_t} =tanh(X_tW_{xh}+(R_t\cdot H_{t-1})W_{hh}+b_h) Ht~=tanh(XtWxh+(Rt⋅Ht−1)Whh+bh) ⋅ \cdot ⋅ Hadamard积:对应数值做乘法
隐藏状态
H t = Z t ⋅ H t − 1 + ( 1 − Z t ) ⋅ H t ~ H_t = Z_t\cdot H_{t-1}+(1-Z_t)\cdot\tilde{H_t} Ht=Zt⋅Ht−1+(1−Zt)⋅Ht~
重置门和更新们是和隐藏状态 H t H_t Ht大小相同的向量(这里说的向量是忽略批量大小说的)
极端情况下,重置门=1,更新门=0,就是RNN

总结:简单来说,如果理解RNN的话,GRU其实非常好懂,RNN用了一个隐藏状态,GRU用了差不多的两个门来控制隐藏状态(因为两个门是sigmoid算出来的 [0, 1] 之间,和 H t H_t Ht做数值乘法能够有削弱作用,以此达到控制效果),学习哪些信息是有用的,哪些是没用的,也因此GRU的参数数量是RNN的三倍(这里不考虑输出层前的那个线性层)
代码
读数据集
import torch
from torch import nn
from d2l import torch as d2l
batch_size, num_steps = 32, 35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
初始化参数
def get_params(vocab_size, num_hiddens, device):
num_inputs = num_outputs = vocab_size
def normal(shape):
return torch.randn(size=shape, device=device)*0.01
def three():
return (normal((num_inputs, num_hiddens)),
normal((num_hiddens, num_hiddens)),
torch.zeros(num_hiddens, device=device))
W_xz, W_hz, b_z = three() # 更新门参数
W_xr, W_hr, b_r = three() # 重置门参数
W_xh, W_hh, b_h = three() # 候选隐状态参数
# 输出层参数
W_hq = normal((num_hiddens, num_outputs))
b_q = torch.zeros(num_outputs, device=device)
# 附加梯度
params = [W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q]
for param in params:
param.requires_grad_(True)
return params
和RNN差不多,但是因为多了两个门,所以我们封装一个函数three(),一共11个参数,都需要求梯度
初始化隐藏状态
def init_gru_state(batch_size, num_hiddens, device):
return (torch.zeros((batch_size, num_hiddens), device=device), )
和RNN一样,一个turple
正向传播过程
def gru(inputs, state, params):
W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q = params
H, = state
outputs = []
for X in inputs:
Z = torch.sigmoid((X @ W_xz) + (H @ W_hz) + b_z)
R = torch.sigmoid((X @ W_xr) + (H @ W_hr) + b_r)
H_tilda = torch.tanh((X @ W_xh) + ((R * H) @ W_hh) + b_h)
H = Z * H + (1 - Z) * H_tilda
Y = H @ W_hq + b_q
outputs.append(Y)
return torch.cat(outputs, dim=0), (H,)
套公式
训练
vocab_size, num_hiddens, device = len(vocab), 256, d2l.try_gpu()
num_epochs, lr = 500, 1
model = d2l.RNNModelScratch(len(vocab), num_hiddens, device, get_params,
init_gru_state, gru)
d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)
因为之前RNN的训练函数我们封装的很好,很通用
RNNModelScratch(len(vocab), num_hiddens, device,
get_params,init_gru_state,gru)传入这三个参数就行
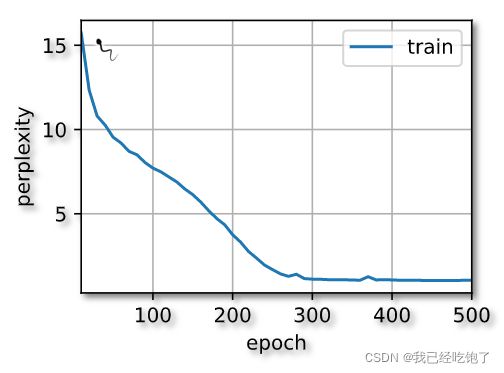
训练效果
perplexity 1.1, 21648.1 tokens/sec on cuda:0
time traveller for so it will be convenient to speak of himwas e
travelleryou can show black is white by argument said filby
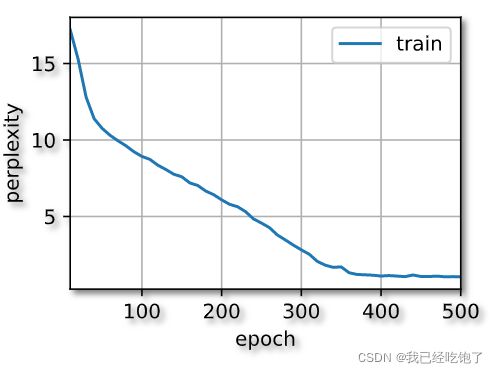
简易实现
num_inputs = vocab_size
gru_layer = nn.GRU(num_inputs, num_hiddens)
net = d2l.RNNModel(gru_layer, len(vocab))
net = net.to(device)
d2l.train_ch8(net, train_iter, vocab, lr, num_epochs, device)
perplexity 1.1, 154909.2 tokens/sec on cuda:0
time travelleryou can show black is white by argument said filby
travelleryou can show black is white by argument said filby