PyTorch 模型训练实用教程(六):监控模型——可视化
本章将介绍如何在 PyTorch 中使用 TensorBoardX 对神经网络进行统计可视化,如Loss 曲线、Accuracy 曲线、卷积核可视化、权值直方图及多分位数折线图、特征图可视化、梯度直方图及多分位数折线图及混淆矩阵图等。
TensorBoardX
PyTorch 自身的可视化功能没有 TensorFlow 的 tensorboard 那么优秀,所以 PyTorch通常是借助 tensorboard(是借助,非直接使用)进行可视化,目前流行的有如下两种方法,本文仅介绍第二种——TensorBoardX。
1. 构建 Logger 类
Logger 类中“包”了 tf.summary.FileWriter ,截至目前(2018.10.17),只有三种操作,分别是 scalar_summary(), image_summary(), histo_summary()。
优点: 轻便,可满足大部分需求
Logger 类参考 github: https://github.com/yunjey/PyTorch-tutorial/tree/master/tutorials/04-utils/tensorboard
2. 借助 TensorBoardX 包
TensorBoardX 包的功能就比较全,截至目前(2018.10.17),支持除 tensorboard beholder 之外的所有 tensorboard 的记录类型。
github: https://github.com/lanpa/tensorboardX
API 文档: https://tensorboard-PyTorch.readthedocs.io/en/latest/tutorial_zh.html#
安装时小插曲:
一开始按照 github 上的方法安装:pip install
git+ https://github.com/lanpa/tensorboardX
会报错:from .proto importevent_pb2 ImportError: cannot import name event_pb2 查看本地 在文件夹 proto/下确实没有 event_pb2,但是在 github 上是存在的
最后通过 pip uninstall tensorboardX,使用 pip install tensorboard 安装成功 。
tensorboardX 最早叫 tensorboard,但此名易引起混淆,之后改为 tensorboardX,which stands for tensorboard for X。
代码实现:
tensorboardX 提供 13 个函数,可以记录标量、图像、语音、文字等等,功能十分丰富。
本节将对这些函数进行介绍,所用代码为 tensorboardX 的官方 demo.py,放在/Code/4_viewer/1_tensorboardX_demo.py ,请先运行该文件,并且打开 terminal,进入相应的虚拟环境(如果有),进入到/Result/文件夹,执行:tensorboard --logdir=runs然后到浏览器中打开:localhost:6006可以看到显示界面如下:
完成以上步骤,就可以一一来学习 tensorbaordX 各功能函数啦。
tesnorboardX 的函数:
1. add_scalar()
add_scalar ( tag , scalar_value , global_step=None , walltime=None )
功能:
在一个图表中记录一个标量的变化,常用于 Loss 和 Accuracy 曲线的记录。
参数:
tag(string)- 该图的标签,类似于 polt.title
scalar_value(float or string/blobname)- 用于存储的值,曲线图的 y 坐标
global_step(int)- 曲线图的 x 坐标
walltime(float)- 为 event 文件的文件名设置时间,默认为 time.time()
运行 demo 中的:
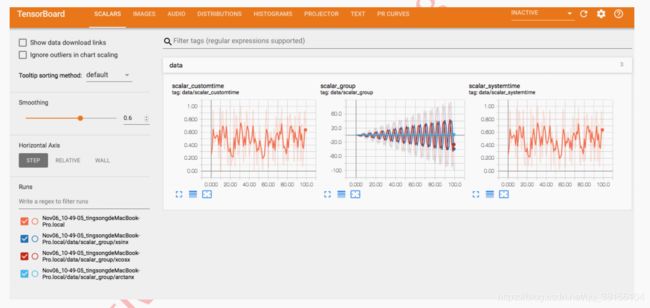
用 github 首页 demo 运行这一行:writer.add_scalar('data/scalar1',dummy_s1[0], n_iter) 得到下图:

2. add_scalars()
add_scalars ( main_tag , tag_scalar_dict , global_step=None , walltime=None )
功能:
在一个图表中记录多个标量的变化,常用于对比,如 trainLoss 和 validLoss 的比较
等。
参数:
main_tag(string)- 该图的标签。
tag_scalar_dict(dict)- key 是变量的 tag,value 是变量的值。
global_step(int)- 曲线图的 x 坐标
walltime(float)- 为 event 文件的文件名设置时间,默认为 time.time()
运行 demo 中的:
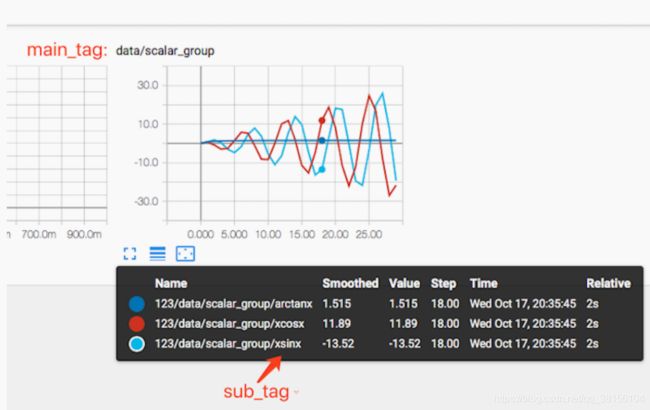
writer.add_scalars('data/scalar_group', {'xsinx': n_iter * np.sin(n_iter),
'xcosx': n_iter * np.cos(n_iter),
'arctanx': np.arctan(n_iter)}, n_iter)
可以得到下图:
3. add_histogram()
add_histogram ( tag , values , global_step=None , bins='tensorflow' , walltime=None )
功能:
绘制直方图和多分位数折线图,常用于监测权值及梯度的分布变化情况,便于诊断网络更新方向是否正确。
参数:
tag(string)- 该图的标签,类似于 polt.title。
values(torch.Tensor, numpy.array or string/blobname)- 用于绘制直方图的值
global_step(int)- 曲线图的 y 坐标
bins(string)- 决定如何取 bins,默认为‘tensorflow’,可选:’auto’, ‘fd’等
walltime(float)- 为 event 文件的文件名设置时间,默认为 time.time()
运行 demo 中的:
for name, param in resnet18.named_parameters():
writer.add_histogram(name, param.clone().cpu().data.numpy(), n_iter)
可以得到以下两种图分别在 HISTOGRAMS 和 DISTRIBUTIONS 里面:

x 轴即变量大小,y 轴为 gloabl_step。377 表示卷积层 conv1 的权值中有 377 个weight 的大小是在 0.036 这个区间。

x 轴为 gloabl_step,由于这里没有训练,所以随着 x 轴的增加,曲线是平直的。看 y轴,从上到下,共计 9 条曲线(若有训练,会是曲线,现在是直线),分别对应[maximum,93%, 84%, 69%, 50%, 31%, 16%, 7%, minimum]分位数。
4. add_image()
add_image ( tag , img_tensor , global_step=None , walltime=None )
功能:
绘制图片,可用于检查模型的输入,监测 feature map 的变化,或是观察 weight。
参数:
tag(string)- 该图的标签,类似于 polt.title。
img_tensor(torch.Tensor,numpy.array, or string/blobname)- 需要可视化的图片数据, shape = [C,H,W]。
global_step(int)- x 坐标。
walltime(float)- 为 event 文件的文件名设置时间,默认为 time.time()。
通常会借助 torchvision.utils.make_grid() 将一组图片绘制到一个窗口
补充 torchvision.utils.make_grid()
torchvision.utils.make_grid ( tensor , nrow=8 , padding=2 , normalize=False , range=None , scale_each=False , pad_value=0 )
功能:
将一组图片拼接成一张图片,便于可视化。
参数:
tensor(Tensor or list)- 需可视化的数据,shape: (B x C x H x W) ,B 表示 batch 数,即几张图片
nrow(int)- 一行显示几张图,默认值为 8。
padding(int)- 每张图片之间的间隔,默认值为 2。
normalize(bool)- 是否进行归一化至(0,1)。
range(tuple)- 设置归一化的 min 和 max,若不设置,默认从 tensor 中找 min 和 max。
scale_each(bool)- 每张图片是否单独进行归一化,还是 min 和 max 的一个选择。
pad_value(float)- 填充部分的像素值,默认为 0,即黑色。
运行 demo 代码:
import torchvision.utils as vutils
dummy_img = torch.rand(32, 3, 64, 64) # (B x C x H x W)
if n_iter % 10 == 0:
x = vutils.make_grid(dummy_img, normalize=True, scale_each=True)
writer.add_image('Image', x, n_iter) # x.size= (3, 266, 530) (C*H*W)

5. add_graph()
add_graph ( model , input_to_model=None , verbose=False , **kwargs )
功能:
绘制网络结构拓扑图。
参数:
model(torch.nn.Module)- 模型实例
input_to_model(torch.autograd.Variable)- 模型的输入数据,可以生成一个随机数,只要 shape 符合要求即可
运行以下代码:
import torchvision.models as models
resnet18 = models.resnet18(False)
dummy_input = torch.rand(6, 3, 224, 224)
writer.add_graph(resnet18, dummy_input)
可在 GRAPHS 中看到 Resnet18 的网络拓扑 :

6. add_embedding()
add_embedding ( mat , metadata=None , label_img=None , global_step=None , tag='default' , metadata_header=None )
功能:
在三维空间或二维空间展示数据分布,可选 T-SNE、PCA 和 CUSTOM 方法。
参数:
mat(torch.Tensor or numpy.array)- 需要绘制的数据,一个样本必须是一个向量形式。shape = (N,D),N 是样本数,D 是特征维数。
metadata(list)- 数据的标签,是一个 list,长度为 N。
label_img(torch.Tensor)- 空间中展示的图片,shape = (N,C,H,W)。
global_step(int)- Global step value to record ,不理解这里有何用处呢?知道的朋友补
充一下吧。
tag(string)- 标签
以下代码,展示 Mnist 中的 100 张图片
dataset = datasets.MNIST('mnist', train=False, download=True)
images = dataset.test_data[:100].float()
label = dataset.test_labels[:100]
features = images.view(100, 784)
writer.add_embedding(features, metadata=label, label_img=images.unsqueeze(1))

7. add_text()
add_text ( tag , text_string , global_step=None , walltime=None )
功能: 记录文字
8. add_video()
add_video ( tag , vid_tensor , global_step=None , fps=4 , walltime=None )
功能: 记录 video
9. add_figure()
add_figure ( tag , figure , global_step=None , close=True , walltime=None )
功能: 添加 matplotlib 图片到图像中
10. add_image_with_boxes()
add_image_with_boxes ( tag , img_tensor , box_tensor , global_step=None , walltime=None , **kwargs )
功能: 图像中绘制 Box ,目标检测中会用到
11. add_pr_curve()
add_pr_curve ( tag , labels , predictions , global_step=None , num_thresholds=127 , weights=None , walltime=None )
功能: 绘制 PR 曲线
12. add_pr_curve_raw()
add_pr_curve_raw ( tag , true_positive_counts , false_positive_counts , true_negative_counts , false_negative_counts , precision , recall , global_step=None , num_thresholds=127 , weights=None , walltime=None )
功能: 从原始数据上绘制 PR 曲线
13. export_scalars_to_json()
export_scalars_to_json ( path )
功能: 将 scalars 信息保存到 json 文件,便于后期使用
卷积核可视化
神经网络中最重要的就是权值,而人们对神经网络理解有限,所以我们需要通过尽可能了解权值来帮助诊断网络的训练情况。除了查看权值分布图和多折线分位图,还可以对卷积核权值进行可视化,来辅助我们分析网络。本小节就介绍卷积核权值可视化原理和方
法。
在 2012 年 AlexNet 的论文中,展示了一副卷积核权值可视化的图片,如下图所示。

文中将第一个卷积层的卷积核权值进行可视化,发现有趣的现象。第一个 GPU 中的卷积核呈现初边缘的特性,第二个 GPU 中的卷积核呈现色彩的特性。对卷积核权值进行可视化,在一定程度上帮助我们诊断网络的训练好坏,因此对卷积核权值的可视化十分有必要。
可视化原理很简单,对单个卷积核进行“归一化”至 0~255,然后将其展现出来即可,这一系列操作可以借助 TensorboardX 的 add_image 来实现。
先看两张可视化效果图,接着简单介绍卷积核卷积过程,最后讲解代码。
下图以卷积层 conv1 为例,conv1.weight.shape() = [6,3,5,5],输入通道数为 3,卷积核个数为 6,则 feature map 数为 6,卷积核大小为 5*5。
图 1,绘制全部卷积核。

图 2,以 feature map 为单位,借助 step 参数区分 feature map,将卷积核分开绘制。
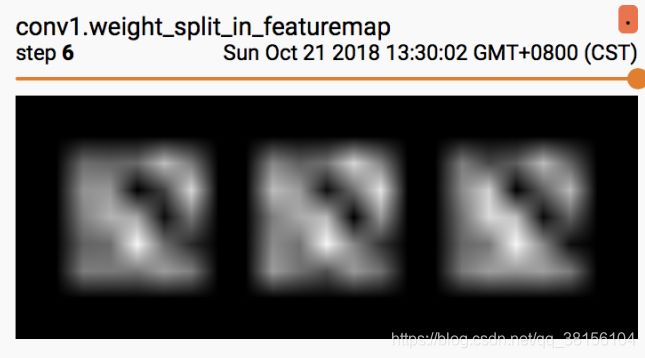
好奇的朋友就会问了,为什么要将每一行显示 3 个卷积核呢?
因为每 3 个卷积核共同作用去决定了一张 feature map,因此将其放在一起观察。具体卷积核过程可以观察下图,输入通道数为 4,输出通道数为 2。
第一个输出特征图的值,是由 4 个卷积核分别对 4 个输入通道进行卷积并求和,加上bias 项,再通过激活函数,才得到最终 feature map 上的值。

特征图可视化
有时候我们会好奇,原始图像经过网络的操作之后,会是什么样。本小节就介绍如何可视化经网络操作后的图像(feature maps)。
基本思路:
1. 获取图片,将其转换成模型输入前的数据格式,即一系列 transform,
2. 获取模型各层操作,手动的执行每一层操作,拿到所需的 feature maps,
3. 借助 tensorboardX 进行绘制。
Tips:
1. 此处获取模型各层操作是__init__()中定义的操作,然而模型真实运行采用的是forward(), 所以需要人工比对两者差异。本例的差异是,__init__()中缺少激活函数relu。
先看看图,下图为 conv1 层输出的 feature maps, 左图为未经过 relu 激活函数,右图为经过 relu 之后的 feature maps

文末探讨
1. 经过 relu 激活函数之后,明显很多像素点变黑,即像素值变为 0 了? 这样是否会影响网络性能?
2. 除了 net._modules.items()这种方法之外,是否还有更简便的方法来获取 feature maps 吗? 因此上述方法感觉不太“智能”,需要人工比对 forward()中的操作和__init__()中的操作,比较容易出差错,如果有更好的方法,欢迎分享。
梯度及权值分布可视化
在网络训练过程中,我们常常会遇到梯度消失、梯度爆炸等问题,我们可以通过记录每个 epoch 的梯度的值来监测梯度的情况,还可以记录权值,分析权值更新的方向是否符合规律。
本小节就介绍如何记录梯度及权值,并进行可视化。
记录梯度和权值主要是以下三行代码:
# 每个 epoch,记录梯度,权值
for name, layer in net.named_parameters():
writer.add_histogram(name + '_grad', layer.grad.cpu().data.numpy(), epoch)
writer.add_histogram(name + '_data', layer.cpu().data.numpy(), epoch)
可视化分析
1. 权值 weights 的监控
经过 100 个 epoch 的训练,来看看第一个卷积层的权值分布的变化。
x 轴即变量大小,y 轴为 gloabl_step。图 1 x=0.306, y=0, 数值显示为 0.00,表示第 0个 epoch 时,权值为 0.306 的个数为 0.00。

图 2, x=0.306, y=85, 数值显示为 5.71,表示第 85 个 epoch 时,权值在 0.306 区间的有 5.71 个。这里暂时还不明白为什么会是小数,知道的朋友可以补充一下。
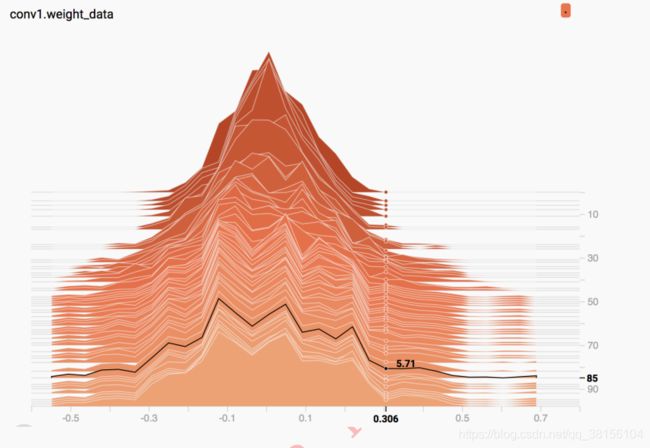
通过 HISTOGRAMS 可以看到第一个卷积层的权值随着训练的不断的“扩散”,扩大,一开始是个比较标准的高斯分布,并且最大值不会超过 0.3。
而到了后期,权值会发散到 0.6+,这个问题也是需要关注的,若权值太大容易导致过拟合。因为模型的输出值会被该特征所主导,从而引起过拟合现象,这个可以通过权值衰减(weight_decay)来缓解。
2. 偏置 bias 的监控
通常会监控输出层的 bias 的大小,若有特别大,或者特别小的 bias,那么某一类别的召回率可能会很低,可以通过观察输出层的 bias 来诊断是否在这一环节出问题。

从图上可以看到,一开始 10 个类别的 bias 都比较小,随着训练的进行,每个类别都有了自己的固定的 bias 大小。
3. 梯度的监控
下图为第一个卷积层权值的梯度变化情况,可以看到,几乎都是服从高斯分布的。倘若前面几层的梯度非常小,那么就是梯度流通不畅导致的,可以考虑残差结构或者辅助损失层等 trick 来解决梯度消失。

文末思考:
1. 通过观察各层的梯度,权值分布,我们可以针对性的设置学习率,为那些梯度小的层设置更大的学习率,让那些层可以有效的更新,不知道这样是否有用,大家可以尝试。
2. 对权值特别大的那些层,可以考虑为那一层设置更大的 weight_decay,是否能有效降低该层权值大小呢。
3. 通过对梯度的观察,可以合理的设置梯度 clip 的值喔。
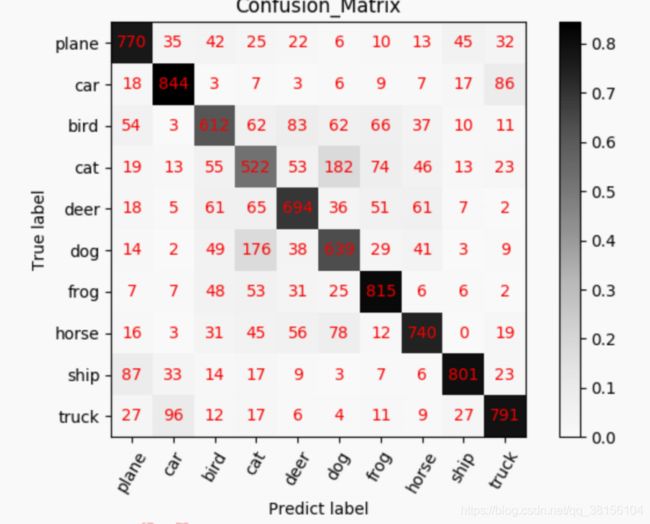
混淆矩阵及其可视化
在分类任务中,个人十分喜欢混淆矩阵,通过混淆矩阵可以看出模型的偏好,而且对每一个类别的分类情况都了如指掌,为模型的优化提供很大帮助。本小节就介绍混淆矩阵概念及其可视化。
1. 混淆矩阵概念
混淆矩阵(Confusion Matrix)常用来观察分类结果,其是一个 N*N 的方阵,N 表示类别数。混淆矩阵的行表示真实类别,列表示预测类别。例如,猫狗的二分类问题,有猫的图像 10 张,狗的图像 30 张,模型对这 40 张图片进行预测,得到的混淆矩阵为:

从第一行中可知道,10 张猫的图像中,7 张预测为猫,3 张预测为狗,猫的召回率(Recall)为 7/10 = 70%,
从第二行中可知道,30 张狗的图像中,8 张预测为猫,22 张预测为狗,狗的召回率为20/30 = 66.7%,
从第一列中可知道,预测为猫的 17 张图像中,有 7 张是真正的猫,猫的精确度(Precision)为 7 / 17 = 41.17%
从第二列中可知道,预测为狗的 23 张图像中,有 20 张是真正的狗,狗的精确度(Precision)为 20 / 23 = 86.96%
模型的准确率(Accuracy)为 7+20 / 40 = 67.5%
可以发现通过混淆矩阵可以清晰的看出网络模型的分类情况,若再结合上颜色可视化,可方便的看出模型的分类偏好。
2. 混淆矩阵的统计
第一步:创建混淆矩阵
获取类别数,创建 N*N 的零矩阵
conf_mat = np.zeros([cls_num, cls_num])
第二步:获取真实标签和预测标签
labels 为真实标签,通常为一个 batch 的标签
predicted 为预测类别,与 labels 同长度
第三步:依据标签为混淆矩阵计数
for i in range(len(labels)):
true_i = np.array(labels[i])
pre_i = np.array(predicted[i])
conf_mat[true_i, pre_i] += 1.0
3. 混淆矩阵可视化
可视化还需要各类标签名,存储为一个 list,以 cifar10 为例:
classes = ['plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse','ship', 'truck']
可视化效果如下图: