【pytorch学习笔记03】pytorch完整模型训练套路
B站我是土堆视频学习笔记,链接:https://www.bilibili.com/video/BV1hE411t7RN/?spm_id_from=333.999.0.0
1. 准备数据集
train_data = torchvision.datasets.CIFAR10(root='./dataset',
train=True,
transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10(root='./dataset',
train=False,
transform=torchvision.transforms.ToTensor(),
download=True)
# length
train_data_size = len(train_data)
test_data_size = len(test_data)
print(f'训练数据集的长度为:{train_data_size}')
print(f'测试数据集的长度为:{test_data_size}')
2. 加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
3. 构建模型
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64 * 4 * 4, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
# 测试
if __name__ == '__main__':
model = MyModel()
input = torch.ones(64, 3, 32, 32)
output = model(input)
print(output.shape)
实例化
model = MyModel()
4. 定义损失函数、优化器等
# 创建损失函数
loss_func = nn.CrossEntropyLoss() # 这里是一个多分类问题
# 定义优化器
learning_rate = 1e-2
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
# 设置训练网络的参数
total_train_step = 0 # 训练次数
total_test_step = 0 # 测试次数
epoch = 10 # 训练轮数
5. 训练+测试+保存模型
# 添加 tensorboard
writer = SummaryWriter('./logs_train')
# 训练
for i in range(epoch):
print(f'--------第{i+1}轮训练开始---------')
# 训练
model.train()
for data in train_dataloader:
imgs, labels = data
outputs = model(imgs)
loss = loss_func(outputs, labels)
# 优化器优化模型参数
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step += 1
if total_train_step % 100 ==0:
print(f'step:{total_train_step}, loss:{loss.item()}')
writer.add_scalar('train_loss', loss.item(), total_train_step)
# 测试
model.test()
total_test_loss = 0
total_accuracy = 0
with torch.no_grad(): # 测试的时候不需要再调参
for data in test_dataloader:
imgs, labels = data
outputs = model(imgs)
loss = loss_func(outputs, labels)
total_test_loss += loss.item()
accuracy = (outputs.argmax(1) == labels).sum()
total_accuracy += accuracy
print(f'整体测试集上的loss:{total_test_loss}, 准确率:{total_accuracy/test_data_size}')
writer.add_scalar('test_loss', total_test_loss, total_test_step)
writer.add_scalar('test_accuracy', total_accuracy/test_data_size, total_test_step)
total_test_step += 1
# 保存模型参数
torch.save(model, f'model_{i}.pth')
print('模型已保存')
writer.close()
6. 注意
model.train()和eval()
在训练前和测试前不是必要添加这两个函数的
官方文档解释
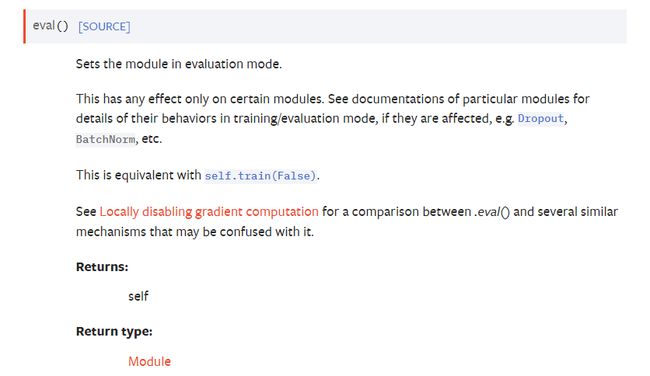

只对某些模块有影响,例如Dropout, BatchNorm等。所以保险起见两个都加?