如何从tensorboardX中的参数histogram看网络训练问题?
最近遇到一个问题,同样的一个网络,稍微改了一丢丢地方,居然会导致结果差异天差地别,看loss函数可以大概知道model1有问题。但是其实也可以从另一个角度,比如参数的分布来看,这里就介绍一下我的做法。(pytorch 用tensorboardX, tensorflow用tensorboard)
一共四个小实验
实验1,对比model 1和model 2的参数histogram
示例代码:
服务器上训练好的模型保存在“models_2_1”和“model_2_2”下面
服务器上代码:
#debug.py
import torch, os
from MyNet
from tensorboardX import SummaryWriter
import numpy as np
epochs = 10
train_parts = '1_3'
test_part = '2'
save_dir1 = './models_'+test_part+'_1'
save_dir2 = './models_'+test_part+'_2'
epochs = 10
cuda_num = 0
if not os.path.exists(save_dir1):
os.mkdir(save_dir1)
if not os.path.exists(save_dir2):
os.mkdir(save_dir2)
net = MyNet()
if torch.cuda.is_available():
net.cuda(0)
writer = SummaryWriter()
for epoch in range(9,epochs):
model_path = save_dir1 + '/combine_' + train_parts + '_params_epoch_' + str(epoch) + '.pkl'
net.load_state_dict(torch.load(model_path))
net.eval()
for name, param in net.named_parameters():
writer.add_histogram(name + "_model1", param.clone().cpu().data.numpy(), epoch)
model_path = save_dir2 + '/combine_' + train_parts + '_params_epoch_' + str(epoch) + '.pkl'
net.load_state_dict(torch.load(model_path))
net.eval()
for name, param in net.named_parameters():
writer.add_histogram(name + "_model2", param.clone().cpu().data.numpy(), epoch)
writer.close()
服务器上:
python3 debug.py
tensorboard --logdir=./runs
我的台式机上:
ssh -L 6192:127.0.0.1:6006 [email protected]
(ssh -L 本地端口:本地IP:远程端口 远程服务器用户名@远程服务器Ip)
配置好之后本地浏览器打开网址:http://127.0.0.1:6192/#histograms
现在我们对比一下模型1和模型2的参数状态:histogram图,横轴代表取值,即参数的具体数值。
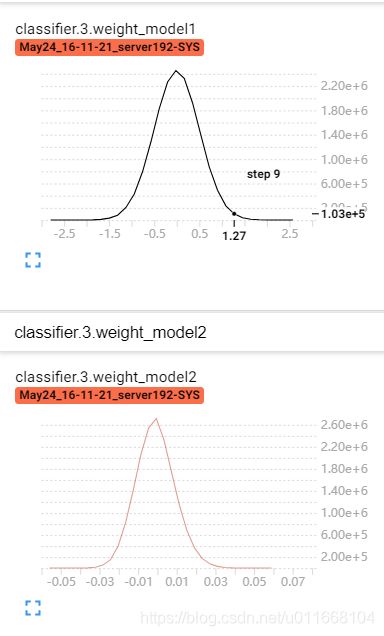



由于我用的histogram,所以我们看到的实际上是参数的分布范围情况。
对比两个模型我们发现,model1和model2的参数都分布在0左右,而model2的范围更加集中,也就是参数值更小。那么,是更集中的代表训练好了还是更分散的是训练好的呢?
实验2,训练好的模型参数histogram长什么样子?
我们再看一下已经训练好的模型参数范围。
服务器代码
#demo.py
import torchvision
from tensorboardX import SummaryWriter
model = torchvision.models.vgg19(pretrained=True)
writer = SummaryWriter()
for name, param in model.named_parameters():
writer.add_histogram(name + "_vgg16", param.clone().cpu().data.numpy(), 0)
model = torchvision.models.alexnet(pretrained=True)
for name, param in model.named_parameters():
writer.add_histogram(name + "_alexnet", param.clone().cpu().data.numpy(), 0)
model = torchvision.models.resnet18(pretrained=True)
for name, param in model.named_parameters():
writer.add_histogram(name + "_resnet18", param.clone().cpu().data.numpy(), 0)
writer.close()
同样的,
服务器上:
python3 demo.py
tensorboard --logdir=./runs
我的台式机上:
ssh -L 6192:127.0.0.1:6006 [email protected]
(ssh -L 本地端口:本地IP:远程端口 远程服务器用户名@远程服务器Ip)
配置好之后本地浏览器打开网址:http://127.0.0.1:6192/#histograms
现在我们来看下结果:






大多数时候,波的x轴范围都应该在0.0x中,唯一一个例外是resnet18的fc层参数,范围主要在0.1内波动。
现在我们回过头看model1的范围在1以内,model2的范围在0.0x内,可以看出来,model2是正常的,而model1就像是随机初始化根本没有训练一下。
实验3,直接随机初始化,不训练的模型参数histogram长什么样子?
如果数据直接初始化之后不训练,参数的histogram又是怎样的呢?
(这部分其实可以通过具体初始化函数的实现代码看出来,不过我比较笨不是很懂,所以还是做个实验看一下吧。)
为了确认我的model 1是不是初始化之后就没学习过,我采用我model 1中的初始化方式。如demo_2.py所示
#demo_2.py
import torch, os
import numpy as np
import myNet
from tensorboardX import SummaryWriter
def weights_init(m):
classname=m.__class__.__name__
if classname.find('Conv') != -1:
torch.nn.init.normal(m.weight.data)
torch.nn.init.normal(m.bias.data)
if classname.find('BatchNorm') != -1:
torch.nn.init.normal(m.weight.data)
torch.nn.init.normal(m.bias.data)
if classname.find('Linear') != -1:
param_shape = m.weight.shape
m.weight.data = torch.from_numpy(np.random.normal(0, 0.5, size=param_shape)).float()
net = myNet()
if torch.cuda.is_available():
net.cuda(0)
net.apply(weights_init)
writer = SummaryWriter()
net.eval()
for name, param in net.named_parameters():
writer.add_histogram(name + "_ramdom", param.clone().cpu().data.numpy(), 0)
writer.close()
同样地,
服务器上:
python3 demo_2.py
tensorboard --logdir=./runs
我的台式机上:
ssh -L 6192:127.0.0.1:6006 [email protected]
(ssh -L 本地端口:本地IP:远程端口 远程服务器用户名@远程服务器Ip)
配置好之后本地浏览器打开网址:http://127.0.0.1:6192/#histograms
现在我们来看下结果:


我这个model 1就是这样初始化的,所以说初始化出来的参数分布就长这个样子。。。我的model 1貌似可能也许真的压根就没有进行训练啊。。。T_T
This is a sad story.
实验4,参数采用pytorch默认初始化不进行初始化的情况?
那如果我不用这种方式初始化,直接pytorch默认的初始化,不自己进行初始化呢?
#demo_3.py
import torch, os
import numpy as np
import myNet
from tensorboardX import SummaryWriter
net = myNet()
if torch.cuda.is_available():
net.cuda(0)
writer = SummaryWriter()
net.eval()
for name, param in net.named_parameters():
writer.add_histogram(name + "_AutoRamdom", param.clone().cpu().data.numpy(), 0)
writer.close()
同样地,
服务器上:
python3 demo_3.py
tensorboard --logdir=./runs
我的台式机上:
ssh -L 6192:127.0.0.1:6006 [email protected]
(ssh -L 本地端口:本地IP:远程端口 远程服务器用户名@远程服务器Ip)
配置好之后本地浏览器打开网址:http://127.0.0.1:6192/#histograms
现在我们来看下结果:


为什么长这样呢?
我们去看一下pytorch默认的随机函数是啥?
https://pytorch.org/docs/stable/_modules/torch/nn/modules/linear.html#Identity

linear层默认是这个init.kaiming_uniform的初始化方式,均匀分布。
https://pytorch.org/docs/stable/_modules/torch/nn/modules/conv.html#Conv2d

卷积层也是这个初始化参数。
结论:以后在训练过程中应该0把参数也存一下,看参数的分布变化应该也能看出来模型训练的一些情况。