第三章 初识MFCC以及Wavenet神经网络
音频预处理以及Wavenet网络
- 音频预处理
-
- MFCC特征提取
- 初识Wavenet网络
- CTC损失函数
- 整体结构(Wavenet+CTC)
- 整体模型过程
- 模型代码
音频预处理
整个音频数据都是从网易云上面下载的,有的歌曲网易为了保护版权是NCM格式,并非常规的MP3格式,所以这里用NVM_Unlock工具:

链接:https://pan.baidu.com/s/1vQOtKDq6jiJI52-qdyWOJA
提取码:xbki
剪辑工具是QVE,朋友给的号,还有VIP,专业的咱使不惯!

不过不专业的剪辑工具也给后面带来了问题,毕竟没有对齐声轨、声道等功能,注意剪辑出来的格式用回.wav格式,名字中文改为拼音。
音频资料连接:
链接:https://pan.baidu.com/s/1ZoqPgxFMrclt1v5jOtz2hg
提取码:56uc
一共有1152条音频,前面剪得是10s左右,后面懒了就变成30s左右。
MFCC特征提取
本设计最基础亦是最核心的部分——嗓音特征的提取。换而言之,就是把其他用不上的信息去掉,例如背景噪音,底部噪音等。根据科学研究发现,人的耳朵对于200Hz到500Hz的语音信号感知度或者说敏感性是最高的。当一高一低两个不同响度的声音同时作用于人耳时,人类的耳朵总是会“倾向于接收”到高音频部分,从而低音频会被影响到,变成次要部分,一般这种称为掩蔽效应。这是生物物理学所决定的,因为在内耳蜗基底膜上,低频声音的行波传递距离长于高频的,所以高音难于隐藏于低音。在掩蔽临界带宽方面,低频比高频的要小。根据上述生物学原理,在音频声波上设置带通滤波器,按照临界带宽大小布置,由密到疏布置好,对输入的音频信号过滤,每个滤波器输出信号能量,以此作为信号的特征,将信号特征进行处理即可生成语音输入特征。
MFCC的提取过程:(1)将音频文件输入,解析成时域信号。(2)先分帧,后加窗再进行快速傅里叶变换把信号变为频域信号。分帧,是指对信号分割成多片段,而加窗的作用是把信号变得连续起来,分帧越多,误差越大。(3)通过梅尔频谱变换,将频率转换成人耳能感知的线性关系。(4)通过梅尔倒谱分析,利用离散余弦变换分开信号平均值和正弦信号分量。(5)提取声音频谱特征向量,将向量转换成图像。
当然,在做实验的时候不用进行如此繁复过程,这只是原理过程,可以直接在程序工程开始前导入MFCC库即可(import mfcc)。下图为实验过程中的MFCC图片。
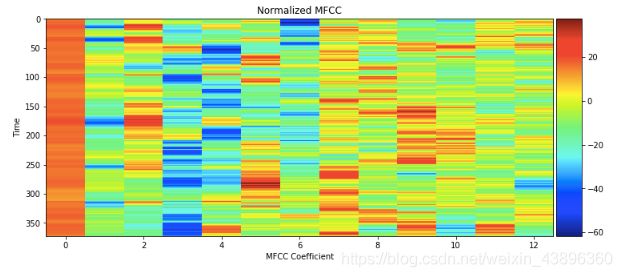
当然提取完MFCC特征之后,还要进行归一化处理,所谓的归一化就是将训练集中的数据缩放映射到0—1之间,许多算法中目标函数都是假设所有的特征都是零平均值而且都是具有同一阶数上的方差,如果某个数据特征比其他特征数量级上差距过大,那它占据的比例就越大,所造成的严重后果是该模型并不能从别的特征学习,因此会导致模型泛化性下降。
初识Wavenet网络
Wavenet是谷歌deepmind在2018年推出的基于深度学习的语音生成模型,其主要优势在于能够抓取不同不同歌手的的嗓音特征,保真度极高。该模型与判别模型结合使用,在语音识别方面成效非常好,而语音分类相比于语音识别较简单,只需要输出一个分类结果即可,不需要后续文本处理,所以在设计初期优先使用该模型。
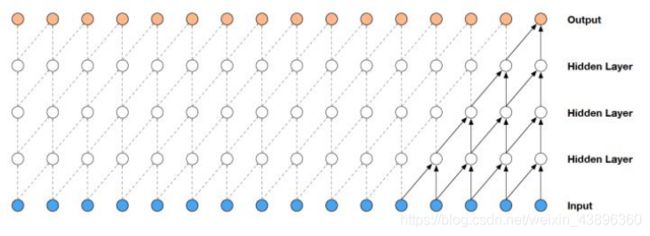
探讨Wavenet网络前,先要注意以下概念:
(1)卷积层堆叠(串联)
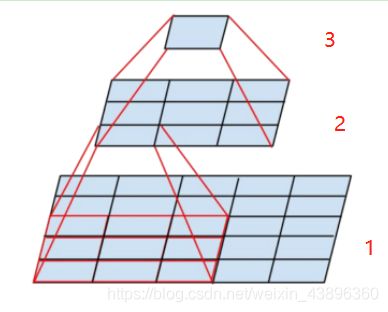
卷积堆叠概念:由图可知两个3×3的卷积串联相当于一个5×5的卷积,三个3×3卷积串联,就相当于一个7×7的卷积,如图下图所示。
(2)感受野
在神经网络中,全连接层每一个输出值都依赖于全连接网络所有输入;卷积层的仅仅依赖于卷积层输入的一块区域。用上图举个例子:2号层左下角的值是1号层红框33卷积求和得到的,所以2号层左下角的感受野是1号层红框部分;3层的是2号层所有33卷积求和得到的,所以3号层感受野是2号层全部区域。
(3)Wavenet解析
Wavenet模型主要使用了多层因果空洞卷积。因果空洞卷积是指卷积当前输出的值只与当前位置之前的输入的值有关,不接受未来的特征,根据Wavenet结构图可理解为当前位置向前偏移。以前卷积的时候,每一层范围的值是连接在一起的,而现在空洞是指每两个值之间有“洞”,“洞”越大,两值之间间距越大,即可理解为卷积是以跳跃形式进行,卷积层多次堆叠后有效增加感受野。
CTC损失函数
该损失函数在OCR或者语音识别领域中运用得比较多,因为在这两个场景中,输入的数据和标签都是序列化数据,它们之间是没有办法对齐的。例如,图4-2的一段音频内容是“你好”,对应的标签也是“你好”,但“你”字在这段音频中,究竟对应声波的第几帧到第几帧,是没办法进行人为标记的,CTC损失函数主要作用就是自动对齐,而且它还有一个好处是可以直接输出预测概率,不需要后续处理。

整体结构(Wavenet+CTC)
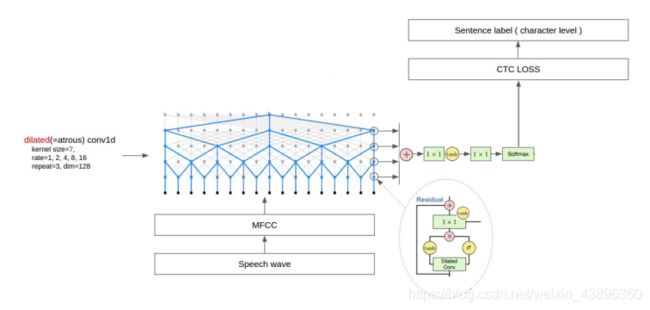
(1)1×1卷积层作用是线性变化,让输入与输出通道数没有变化,没有降维。1×1卷积是一个非常优秀的结构,可以跨通道组织信息,提高网络的表达能力。1×1卷积的性价比很高,用很小的计算量就可以增加一层特征变换和非线性化。
(2)skip_connection(残差学习),与普通多了恒等映射,即在构建网络的时候加入shortcut连接,相当于电路一样,把输入直接短路,恒等映射部分不需要训练,因为它没有任何参数,就如同单位矩阵一样,X乘上单位矩阵还是它本身。每一层输出并不像传统神经网络那样,输出只是输入的映射,而是变成了映射与输入的叠加。上图右下角模块就是运用了残差学习(后面简称模块)。
(3)tanh函数:tanh函数输出区间是-1到1,所以当一个正的矩阵经过tanh函数后,会增加特征矩阵范围。
整体模型过程
卷积层大小7×7,一共用了五层,空洞率从下层到上层,分别为1,2,4,8,16,越来越疏。wav文件转换成MFCC特征之后,把特征输入到这个多层因果空洞卷积层(dilated)中, 首先经过两个激活函数一个是sigmoid,另外一个是tanh,经过激活函数激活后,两个数值相乘,随后是一个1*1的卷积层(附带激活函数tanh),进行输出,该输出与MFCC原始输入相加,也就是上节内容提到的残差连接,得到一个Wavenet层总输出。Wavenet的每一层都是这种输出,通过侧边引出这种方式,都一起相加。这其实相当于这个语音特征把不同的卷积深度里面的特征提取出来,把他们加一起之后经过一个1×1的卷积层(tanh激活函数),再经过一个1×1的卷积层,最后经过一个soft_max激活函数之后,就可以得到某个特征它所对应的概率分布,概率最大者就是所属分类。
模型代码
这个模型的准确率非常的低,经过四五次调参之后,还是一样低,所以当时一怒之下就把它删了,只留下部分代码

(1)整理每条语音所对应的分类标签
首先把train训练集的路径拿出来以‘\’符号为分割界限split一下,实验时的训练数据文件路径是yinpin\train\nan_gao…,从0开始数,第2个文件名就是分类标签。把label列表加到字典中。
1.labels = {'train': [], 'dev': []}
2.for i in tqdm(range(len(train_files))):
3. path = train_files[i]
4. label = path.split('\\')[2]
5. labels['train'].append(label)
6.for i in tqdm(range(len(dev_files))):
7. path = dev_files[i]
8. label = path.split('\\')[2]
9. labels['dev'].append(label)
10.print(len(labels['train']), len(labels['dev']))
(2)切割音频
模型训练的音频以3s为标准,进行切割后,音频片段长短不一,因此,需删除超短的片段,保留长片段。sr = 16000;min_length = 1 * sr;slice_length = 3 * sr(前面设置好的超参数,分别是采样率;音频最小长度;要切成多长)
1.slices = []
2. for i in range(0, audio.shape[0], slice_length):
3. s = audio[i: i + slice_length]
4. if s.shape[0] >= min_length:
5. slices.append(s)
6. return audio, slices
(3)MFCC归一化处理
1.mfcc_mean = np.mean(samples, axis=0)
2.mfcc_std = np.std(samples, axis=0)
3.print(mfcc_mean)
4.print(mfcc_std)
5.X_train = [(x - mfcc_mean) / (mfcc_std + 1e-14) for x in X_train]
6.X_dev = [(x - mfcc_mean) / (mfcc_std + 1e-14) for x in X_dev]
(4)对分类标签进行处理
6个分类标签都是文本,所以要对此使用LabelEncoder编码成整数,Y_train这时候就不是nao_gao、nan_di、nan_zhong等等,而是变成0—5的数字,每个数字代表一个标签。
class2id;id2class这两个是建立映射关系。to_categorical的作用是把每个类别变成向量,例如[1,0,0,0,0,0]。
1.from sklearn.preprocessing import LabelEncoder
2.from keras.utils import to_categorical
3.le = LabelEncoder()
4.Y_train = le.fit_transform(Y_train)
5.Y_dev = le.transform(Y_dev)
6.print(le.classes_)
7.class2id = {c: i for i, c in enumerate(le.classes_)}
8.id2class = {i: c for i, c in enumerate(le.classes_)}
9.num_class = len(le.classes_)
10.Y_train = to_categorical(Y_train, num_class)
11.Y_dev = to_categorical(Y_dev, num_class)
(5)定义模型并训练
1.epochs = 50
2.num_blocks = 6
3.filters = 128
4.X = Input(shape=(None, mfcc_dim,), dtype='float32')
5.def conv1d(inputs, filters, kernel_size, dilation_rate):
6. return Conv1D(filters=filters, kernel_size=kernel_size, strides=1, padding='causal', activation=None, dilation_rate=dilation_rate)(inputs)
7.
8.def batchnorm(inputs):
9. return BatchNormalization()(inputs)
10.
11.def activation(inputs, activation):
12. return Activation(activation)(inputs)
13.
14.def res_block(inputs, filters, kernel_size, dilation_rate):
15. hf = activation(batchnorm(conv1d(inputs, filters, kernel_size, dilation_rate)), 'tanh')
16. hg = activation(batchnorm(conv1d(inputs, filters, kernel_size, dilation_rate)), 'sigmoid')
17. h0 = Multiply()([hf, hg])
18.
19. ha = activation(batchnorm(conv1d(h0, filters, 1, 1)), 'tanh')
20. hs = activation(batchnorm(conv1d(h0, filters, 1, 1)), 'tanh')
21.
22. return Add()([ha, inputs]), hs
23.
24.h0 = activation(batchnorm(conv1d(X, filters, 1, 1)), 'tanh')
25.shortcut = []
26.for i in range(num_blocks):
27. for r in [1, 2, 4, 8, 16]:
28. h0, s = res_block(h0, filters, 7, r)
29. shortcut.append(s)
30.
31.h1 = activation(Add()(shortcut), 'relu')
32.h1 = activation(batchnorm(conv1d(h1, filters, 1, 1)), 'relu')
33.h1 = batchnorm(conv1d(h1, num_class, 1, 1))
34.h1 = GlobalMaxPooling1D()(h1)
35.Y = activation(h1, 'softmax')
36.
37.optimizer = Adam(lr=0.01, clipnorm=5)
38.model = Model(inputs=X, outputs=Y)
39.model.compile(loss='categorical_crossentropy', optimizer=optimizer, metrics=['accuracy'])
40.checkpointer = ModelCheckpoint(filepath='fangyan.h5', verbose=0)
41.lr_decay = ReduceLROnPlateau(monitor='loss', factor=0.2, patience=1, min_lr=0.000)