机器学习常用特征筛选方法
文章目录
- 背景题目
- 特征筛选
-
- Filter过滤法
-
- 方差过滤
- 相关性过滤
-
- 卡方过滤
- F检验
- 互信息
- 灰色关联度分析(GRA)
- Wrapper包装法
- Embedded嵌入法
-
- 使用SelectFromModel 选取特征(Feature selection using SelectFromModel)
- 基于树模型特征筛选
- 题目应用
- 回归模型的评价指标
-
- RMSE(均方根误差)
- MAE(平均绝对误差)
- R2(决定系数)
- EV(解释方差)
背景题目
抗胰腺癌候选药物分子优化建模
 Mole—文件提供了候选药物分子的784个属性值,包含training和test两个表,分别有1974个分子和50个分子。
Mole—文件提供了候选药物分子的784个属性值,包含training和test两个表,分别有1974个分子和50个分子。
ER-----文件提供了这些候选分子的IC50和pIC50值的大小,用于衡量分子活性,其中pIC50是IC50的负对数,取负对数的原因是为了使pIC50大小与分子活性呈正相关。同样包含training表和test表,training表中分子活性标志值pIC50已经给出,test表中的值未给,是问二需要自己预测的值
问一:从分子的784个属性特征中筛选出20个与分子活性最相关的属性
问二:根据筛选出的20个特征属性,训练回归模型,预测test表中pIC50值。
特征筛选
记录两篇写的比较详细的博客地址
特征选择- Sklearn.feature_selection的理解
机器学习之特征选择(Feature Selection)
这部分主要是上述两篇文章的汇总,以及skilearn官方api中feature-select相关接口的说明
sklearn库feature selection特征选择算法及API使用

Filter过滤法
方差过滤
Variance Threshold是通过特征本身方差来筛选特征的类。比如一个特征本身的方差很小,就表示样本在这个特征上基本没有差异,可能特征中的大多数值都一样,甚至整个特征的取值都相同,那这个特征对于样本区分没有什么作用。所以无论接下来的特征工程要做什么,都要优先消除方差为0的特征。VarianceThreshold有重要参数threshold,表示方差的阈值,表示舍弃所有方差小于threshold的特征,不填默认为0,即删除所有的记录都相同的特征。
#设置方差阈值筛选
from sklearn.feature_selection import VarianceThreshold
selector = VarianceThreshold(threshold = 1)#设置方差过滤阈值为1
aa = selector.fit_transform(feature_frame)
aa_name = selector.get_support()#get_support函数返回方差>阈值的布尔值序列
aa_select = feature_frame.iloc[:,aa_name]#根据布尔值序列取出各个特征
这个过程其实也可以不用api函数自行实现:
var = feature_frame.var()#求每列方差
var_thresh = 1 #设置阈值
var_select = var[var>var_thresh]#根据条件返回序列值,取大于阈值
X = feature_frame[var_select.index]#取出特征
方差过滤的阈值threshold是一个超参,根据情况自行设置,设置为0可以剔除常量特征。
相关性过滤
一般情况下特征如果和标签的相关性比较大的话,这样的特征能够为我们提供大量的信息。如果特征与标签无关,只会白白浪费我们的算力,还可能给模型带来噪声。在 sklearn 中有三种常用的方法来评判特征和标签之间的相关性:卡方、F检验和互信息。
此外还可以从特征间的相关性考虑相关性过滤,假设两个特征之间的相关性特别高,那么这两个特征构成了冗余信息,只需保留其中之一即可。
-
回归问题:f_regression(F检验回归) , mutual_info_regression(互信息回归)
-
分类问题:chi2(卡方检验) , f_classif(F检验分类) , mutual_info_classif(互信息回归)
卡方过滤
卡方检验是一种用途很广的计数资料的假设检验方法。它属于非参数检验的范畴,主要是比较两个及两个以上样本率( 构成比)以及两个分类变量的关联性分析。(仅适用于分类问题)
卡方验证的思路(详情可以参考)是先假设两个变量是独立无关的,由此计算出两变量独立无关时的分布情况,将这个情况与真实情况对比,根据卡方公式计算出卡方:
 然后通过查阅卡方表判断假设是否可靠。卡方表会提供计算的卡方值对应的p值, p 值我们一般使用 0.01 或 0.05 作为显著性水平,即p值判断的边界,p值小于0.01或0.05为相关特征。
然后通过查阅卡方表判断假设是否可靠。卡方表会提供计算的卡方值对应的p值, p 值我们一般使用 0.01 或 0.05 作为显著性水平,即p值判断的边界,p值小于0.01或0.05为相关特征。
from sklearn.feature_selection import chi2
#使用选择器的SelectKBest函数,使用chi2模型(卡方验证)保留关联最大的300个特征
X_fschi = SelectKBest(chi2, k=300).fit_transform(X_fsvar, y)
#除了选择前K个特征,也可以设置选择百分比例SelectPercentile()
#X_new = SelectPercentile(chi2, percentile=10).fit_transform(X, y)
chi2函数也可直接返回特征与目标之间的卡方值和对应的p值
chi, p = chi2(X_fsvar,y)
根据各个特征计算出的p值,以0.05或者0.1为阈值过滤相应的特征
F检验
F检验,又称ANOVA,方差齐性检验,是用来捕捉每个特征与标签之间的线性关系的过滤方法。F值计算公式:

F检验的具体原理
和卡方过滤一样,F值计算出同样要查询F分布表获取p值,我们希望选取p值小于 0.05 或 0.01 的特征,这些特征与标签时显著线性相关的,而p值大于0.05或0.01的特征则被我们认为是和标签没有显著线性关系的特征,应该被删除。
from sklearn.feature_selection import f_classif
F, pvalues_f = f_classif(X_fsvar,y)
互信息
互信息法是用来捕捉每个特征与标签之间的任意关系(包括线性和非线性关系)的过滤方法。互信息法比F检验更加强大,F检验只能够找出线性关系,而互信息法可以找出任意关系。互信息法不返回 p 值或 F 值类似的统计量,它返回“每个特征与目标之间的互信息量的估计”,这个估计量在[0,1]之间取值,为0则表示两个变量独立,为1则表示两个变量完全相关。

from sklearn.feature_selection import mutual_info_classif
mutual_info = mutual_info_classif(X, y, discrete_features= False)
返回值为X中每个特征与目标y的互信息估计值。
使用互信息计算特征与目标间的关联性与使用相关系数(皮尔逊、斯伯尔曼、肯德尔)得出的结论具有很高的一致性。
pandas中的dataframe可以直接计算各列之间的相关系数矩阵:
下边的代码的思路是将目标序列与特征矩阵中每一列组成新的datafarme计算相关系数矩阵。
#计算特征与分子活性间的皮尔逊相关系数,取绝对值
pesrson_list = []
spearman_list = []
kendall_list = []
for feature in list(X.columns):
temp_frame = pd.DataFrame(pic50)
temp_series = X[feature]
temp_frame.insert(0,temp_series.name,temp_series.values)
pesrson_martrix = temp_frame.corr()
spearman_martrix = temp_frame.corr('spearman')
kendall_martrix = temp_frame.corr('kendall')
pesrson_list.append(pesrson_martrix.iloc[0,1])
spearman_list.append(spearman_martrix.iloc[0,1])
kendall_list.append(kendall_martrix.iloc[0,1])
pesrson = pd.Series(pesrson_list, index = X.columns)
spearman = pd.Series(spearman_list, index = X.columns)
kendall = pd.Series(kendall_list, index = X.columns)
实际中也可以之间将目录序列插入特征矩阵最后一列,计算相关系数矩阵,由于相关系数矩阵反映矩阵各个列之间的相关系数,则相关系数矩阵最后一列第一行至倒数第二行即对应第一个特征到最后一个特征与目标变量间相关系数。
灰色关联度分析(GRA)
灰色关联度计算方法
 代码示例:
代码示例:
#计算特征与分子活性间的灰色关联度
数据归一化
normal_pic50 = (pic50 - min(pic50)) / (max(pic50) - min(pic50)) #pIC50结果归一化
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
scaler.fit(X)
normal_X = pd.DataFrame(scaler.transform(X))
normal_X.index = X.index
normal_X.columns = X.columns
refer_seq = normal_pic50 #设置分子活性为参考序列,特征矩阵每列为比较序列
diff_matrix = pd.DataFrame()
for feature in list(normal_X.columns):
#比较序列与参考序列相减
diff_col = pd.Series(X[feature] - refer_seq)
diff_col.name = feature
diff_matrix = diff_matrix.append(diff_col) #这里append是按行添加的,因此后边需要转置一下
diff_matrix = diff_matrix.T
#求最大差和最小差
mmax = diff_matrix.abs().max().max()
mmin = diff_matrix.abs().min().min()
rho=0.5 #设置分辨系数为0.5
#求关联度
r=(mmin+rho*mmax)/((abs(diff_matrix)+rho*mmax))
grey_corr=r.sum(axis=0)/len(diff_matrix.index)
grey_sort=grey_corr.sort_values(ascending=False)
##可视化灰色关联度排名
grey_select = grey_sort.iloc[:len(pesrson_select)]
##两种关联度的交叉
common_test = [index for index in grey_select.index if index in pesrson_select.index]
print("公共变量为:" , len(common_test))
plt.figure(figsize=(16,6))
sns.barplot(grey_select.values, grey_select.index, orient='h')
plt.title("特征与分子活性之间的灰色关联度排序")
Wrapper包装法
包装法将特征包装进模型通过评估模型效果,判断特征的去留。在初始特征集上训练评估器,并且通过coef_属性或通过feature_importances_属性获得每个特征的重要性。然后,从当前的一组特征中修剪最不重要的特征。在修剪的集合上递归地重复该过程,直到最终到达所需数量的要选择的特征。
 包装法最典型的方法为递归特征消除法Recursive feature elimination (RFE)
包装法最典型的方法为递归特征消除法Recursive feature elimination (RFE)
主要思想是反复的构建模型(如SVM或者回归模型)然后选出最差的(或者最好的)的特征(可以根据系数来选),把选出来的特征放到一边,然后在剩余的特征上重复这个过程,直到所有特征都遍历了。这个过程中特征被消除的次序就是特征的排序。因此,这是一种寻找最优特征子集的贪心算法。
RFE的稳定性很大程度上取决于在迭代的时候底层用哪种模型。例如,假如RFE采用的普通的回归,没有经过正则化的回归是不稳定的,那么RFE就是不稳定的;假如采用的是Ridge,而用Ridge正则化的回归是稳定的,那么RFE就是稳定的。
sklearn.feature_selection.RFE
 RFE类中有两个比较重要的属性,.support_:返回所有的特征的是否最后被选中的布尔矩阵,以及.ranking_返回特征的按数次迭代中综合重要性的排名。
RFE类中有两个比较重要的属性,.support_:返回所有的特征的是否最后被选中的布尔矩阵,以及.ranking_返回特征的按数次迭代中综合重要性的排名。

skileanr还有一个类feature_selection.RFECV会在交叉验证循环中执行RFE以找到最佳数量的特征,增加参数cv,其他用法都和RFE一模一样。
Embedded嵌入法
包装法将特征打包不断创建新模型测试特征的有效性,而嵌入法则是将特征都嵌入到算法流程中,类似随机森林和决策树模型在模型训练过程中根据信息增益对特征重要性赋予权重,特征选择与模型生成同步进行,而不必重复创建模型测试特征的重要性。

使用SelectFromModel 选取特征(Feature selection using SelectFromModel)

示例1 随机森林模型绘制学习曲线确定特征重要性阈值
from sklearn.feature_selection import SelectFromModel
from sklearn.ensemble import RandomForestClassifier as RFC<br>import numpy as np<br>import matplotlib.pyplot as plt<br>
RFC_ = RFC(n_estimators =10,random_state=0)
print(X_embedded.shape)
#模型的维度明显被降低了
#画学习曲线来找最佳阈值
RFC_.fit(X,y).feature_importances_
threshold = np.linspace(0,(RFC_.fit(X,y).feature_importances_).max(),20)
score = []
for i in threshold:
X_embedded = SelectFromModel(RFC_,threshold=i).fit_transform(X,y)
once = cross_val_score(RFC_,X_embedded,y,cv=5).mean()
score.append(once)
plt.plot(threshold,score)
plt.show()
X_embedded = SelectFromModel(RFC_,threshold=0.00067).fit_transform(X,y)
X_embedded.shape
print(cross_val_score(RFC_,X_embedded,y,cv=5).mean())
示例2:基于L1的特征选取
from sklearn.svm import LinearSVC
from sklearn.datasets import load_iris
from sklearn.feature_selection import SelectFromModel
iris = load_iris()
X, y = iris.data, iris.target
lsvc = LinearSVC(C=0.01, penalty="l1", dual=False).fit(X, y)
model = SelectFromModel(lsvc, prefit=True)
X_new = model.transform(X)
X_new.shape
基于树模型特征筛选
xgboost和lightgbm等集成学习树模型可以在训练中记录特征的重要性,这些重要性的计算方法主要有三种:
‘weight’ - 特征在所有树上被使用的次数
‘gain’ - 所有使用该特征的树的平均信息增益
‘cover’ - 在树上使用该特征时的平均覆盖率
以lightgbm为例:
import lightgbm as lgbm
from lightgbm import plot_importance
lgbm_reg = lgbm.LGBMRegressor(objective='regression',max_depth=6,num_leaves=25,learning_rate=0.005,n_estimators=1000,min_child_samples=80, subsample=0.8,colsample_bytree=1,reg_alpha=0,reg_lambda=0)
lgbm_reg.fit(X_train, y_train)
#选择最重要的20个特征,绘制他们的重要性排序图
lgbm.plot_importance(lgbm_reg, max_num_features=20)
##也可以不使用自带的plot_importance函数,手动获取特征重要性和特征名,然后绘图
feature_weight = lgbm_reg.feature_importances_
feature_name = lgbm_reg.feature_name_
feature_sort = pd.Series(data = feature_weight ,index = feature_name)
feature_sort = feature_sort.sort_values(ascending = False)
plt.figure(figsize=(16,6))
sns.barplot(feature_sort.values,feature_sort.index, orient='h')

两个图是一致的。
题目应用
背景题目是预测回归类问题,结合上述特征筛选的基本方法,选择方差过滤结合相关性过滤然后使用包装法中的递归特征消除法RFE筛选出20个特征,使用lightGBM绘制特征重要性
# -*- coding: utf-8 -*-
"""
Created on Sat Oct 23 14:40:01 2021
@author: Flower unbeaten
"""
import numpy as np #数据处理
import matplotlib.pyplot as plt
import pandas as pd #dataFrame,Series等数据结构
plt.rcParams['font.family'] = 'SimHei' #设置绘图的中文显
plt.rcParams['axes.unicode_minus'] = False#matplotlib绘图准备,中文显示等
import seaborn as sns #导入seaborn绘图库
sns.set_style('darkgrid') #设置seaborn绘图风格为暗色网络
sns.set(font="simhei")#sns遇到标签需要汉字的可以在绘图前加上这句,与plt类似
##import data
feature_path = "../data/Molecular_Descriptor.xlsx"
c50_path = "../data/ERα_activity.xlsx"
admet_path = "../data/ADMET.xlsx"
feature_frame = pd.read_excel(feature_path,sheet_name = 'training', index_col = 'SMILES') #使用pd读取excel,index_col设置为SMILES
feature_test_frame = pd.read_excel(feature_path,sheet_name = 'test', index_col = 'SMILES')
c50_frame = pd.read_excel(c50_path,sheet_name = 'training', index_col = 'SMILES')
c50_frame.drop(columns='IC50_nM',axis=1,inplace=True) #删掉IC50_nM所在列,inplace为true代表在原来dataframe集成上删除,如果为false则会创建新的dataframe对象并删掉所在列
pic50 = c50_frame['pIC50'] #选中某列,将dataframe转series
##方差筛选
from sklearn.feature_selection import VarianceThreshold
var_selector = VarianceThreshold(threshold = 1)#设置方差过滤阈值为1
var_selector.fit_transform(feature_frame)
is_select = var_selector.get_support()#get_support函数返回方差>阈值的布尔值序列
var_feature = feature_frame.iloc[:,is_select]#根据布尔值序列取出各个特征所在列
##相关性筛选
from sklearn.feature_selection import mutual_info_regression
mutualInfo = mutual_info_regression(var_feature, pic50, discrete_features= False)
mutualInfo_select = pd.Series(data = mutualInfo , index = var_feature.columns).sort_values(ascending = False)
append_frame = var_feature#先复制dataFrame
append_frame.insert(len(var_feature.columns),pic50.name,pic50.values)#再添加一列
corr = append_frame.corr()
corr_series = pd.Series(data = corr.iloc[-1,:-1])
corr_sort = corr_series.abs().sort_values(ascending = False)
var_feature.drop('pIC50',axis = 1 , inplace = True)
plt.figure(figsize=(16,6))
sns.barplot(mutualInfo_select.values[:40], mutualInfo_select.index[:40], orient='h')
plt.title("基于互信息的相关性筛选")
plt.figure(figsize=(16,6))
sns.barplot(corr_sort.values[:40], corr_sort.index[:40], orient='h')
plt.title("基于相关系数的相关性筛选")
##递归特征消除法
from sklearn.feature_selection import RFE
#ightGBM模型获取特征重要性
import lightgbm as lgbm
from lightgbm import plot_importance
lgbm_reg = lgbm.LGBMRegressor(objective='regression',max_depth=6,num_leaves=25,learning_rate=0.005,n_estimators=1000,min_child_samples=80, subsample=0.8,colsample_bytree=1,reg_alpha=0,reg_lambda=0)
wapper = RFE(estimator=lgbm_reg, n_features_to_select=20)
wapper.fit(var_feature.iloc[:,:-1], var_feature.iloc[:,-1])
is_select = wapper.support_
wapper_feature = var_feature.iloc[:,is_select]#根据布尔值序列取出各个特征所在列
##训练集划分,三七分,随机数状态107
from sklearn.model_selection import train_test_split
X_train,X_test, y_train, y_test = train_test_split(wapper_feature, pic50,test_size=0.3, random_state=107)
##回归模型评价
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score, explained_variance_score
model_index_function = [explained_variance_score, mean_absolute_error, mean_squared_error, r2_score]
def reg_score(regressor,X_test , y_test):
y_pre = regressor.predict(X_test)
tmp_list = []
for func in model_index_function:
tmp_score = func(y_test, y_pre)
tmp_list.append(tmp_score)
model_score = pd.Series(tmp_list)
# 画出原始值的曲线
plt.plot(np.arange(100), y_test.iloc[:100], color='k', label='real')
# 画出各个模型的预测线
plt.plot(np.arange(100), y_pre[:100], color='cyan', label='lightgbm')
return model_score
lgbm_reg.fit(X_train, y_train)
plt.figure(figsize=(16,6))
model_score = reg_score(lgbm_reg, X_test, y_test)
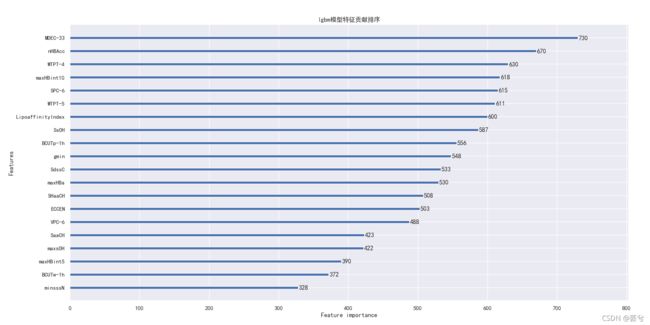
lgbm.plot_importance(lgbm_reg)
plt.title("lgbm模型特征贡献排序")
##也可以不使用自带的plot_importance函数
feature_weight = lgbm_reg.feature_importances_
feature_name = lgbm_reg.feature_name_
feature_sort = pd.Series(data = feature_weight ,index = feature_name)
feature_sort = feature_sort.sort_values(ascending = False)
plt.figure(figsize=(16,6))
sns.barplot(feature_sort.values,feature_sort.index, orient='h')
plt.title("lgbm模型特征贡献排序")
回归模型的评价指标
回归模型评价指标
RMSE(均方根误差)
MAE(平均绝对误差)
R2(决定系数)

越接近1,表明方程的变量对y的解释能力越强,这个模型对数据拟合的也较好
越接近0,表明模型拟合的越差
经验值:>0.4, 拟合效果好

EV(解释方差)
 可解释方差指标衡量的是所有预测值和样本之间的差的分散程度与样本本身的分散程度的相近程度。本身是分散程度的对比。最后用1-这个值,最终值越大表示预测和样本值的分散分布程度越相近。
可解释方差指标衡量的是所有预测值和样本之间的差的分散程度与样本本身的分散程度的相近程度。本身是分散程度的对比。最后用1-这个值,最终值越大表示预测和样本值的分散分布程度越相近。