【强化学习】MuZero 训练CartPole-v1
【深度强化学习】tensorflow2.x复现 muzero 训练CartPole-v1
参考资料:
[1]ColinFred. 蒙特卡洛树搜索(MCTS)代码详解【python】. 2019-03-23 23:37:09.
[2]饼干Japson 深度强化学习实验室.【论文深度研读报告】MuZero算法过程详解.2021-01-19.
[3]Tangarf. Muzero算法研读报告. 2020-08-31 11:40:20 .
[4]带带弟弟好吗. AlphaGo版本三——MuZero. 2020-08-30.
[5]Google原论文:Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model.
[6]参考GitHub代码1.
[7]参考GitHub代码2.

关于代码
- 这里先道个歉,因为考研的缘故之前复现的那个 muzero 没有完成,并且代码也因为换电脑不小心搞丢了(GitHub里面的代码全是报错,写的太乱也懒得改了)。。。。。。这里重新写一遍,比之前的那个代码更加简单易读。
- 蒙特卡洛树的代码 (MCTS.py) 部分这次将用于 Atari 游戏的蒙特卡洛树搜索和用于 棋类游戏(chess)的蒙特卡洛树搜索分开写,下面的代码里完成了用于 Atari 游戏的蒙特卡洛树搜索,至于如果有需求要写用于棋类游戏的 muzero 可以自行完成(可以根据 Atari 的 MCTS 更改,这次的代码非常容易读,照着 Atari 的 MCTS 去写非常简单)
- 本次的代码是完整的muzero代码(至少是对gym里面的游戏),可以根据需求自行更改。
更新
- 补全了棋类的MCTS,加入了探索噪声。
- 更新了多线程训练方法(对训练函数trainer.py略有修改)
cartpole-v1_muzero.py
from cartpole_v1_model import linner_model
from trainer import ReplayBuffer, Trainer
from MCTS import MCTS_Atari
import matplotlib.pyplot as plt
import tensorflow as tf
import numpy as np
import copy
import gym
# 配置GPU内存
physical_devices = tf.config.experimental.list_physical_devices('GPU')
tf.config.experimental.set_memory_growth(physical_devices[0], True)
ENV_NAME = "CartPole-v1"
OBSERVATION_SIZE = 4
ACTION_SIZE = 2
DISCOUNT = 0.9
NUM_SIMULATIONS = 50
UNROLL_STEPS = 9
MEMORY_SIZE = int(1e6)
SIMPLE_SIZE = 1024
EPISODES = 1000
class muzero:
def __init__(self, observation_size, action_size):
self.model = linner_model(observation_size, action_size)
self.MCTS = MCTS_Atari
def choice_action(self, observation, T=1.0):
MCTS = self.MCTS(self.model, observation)
visit_count, MCTS_value = MCTS.simulations(NUM_SIMULATIONS, DISCOUNT)
visit_counts = list(visit_count.values())
prob = np.array(visit_counts) ** (1 / T) / np.sum(np.array(visit_counts) ** (1 / T))
return np.random.choice(len(prob), p=prob), prob, MCTS_value
def plot_score(self, scores):
plt.plot(scores)
plt.show()
if __name__ == '__main__':
env = gym.make(ENV_NAME)
agent = muzero(OBSERVATION_SIZE, ACTION_SIZE)
trainer = Trainer(discount=DISCOUNT)
replay_buffer = ReplayBuffer(MEMORY_SIZE, UNROLL_STEPS)
scores = []
for e in range(EPISODES):
state = env.reset()
action_next, policy_next, _ = agent.choice_action(state)
rewards = 0
while True:
env.render()
action, policy = action_next, policy_next
next_state, reward, done, _ = env.step(action)
action_next, policy_next, value_next = agent.choice_action(next_state)
reward = -100 if done else reward
done = 1 if done else 0
rewards += reward
action_onehot = np.array([1 if i == action else 0 for i in range(ACTION_SIZE)])
replay_buffer.save_memory(state, policy, action_onehot, reward, value_next, next_state, done)
state = copy.deepcopy(next_state)
if done: break
rewards += 100
scores.append(rewards)
policy_loss, value_loss, reward_loss = trainer.update_weight(agent.model, replay_buffer, SIMPLE_SIZE)
print("episode: {}/{}, policy_loss: {}, value_loss: {}, reward_loss: {}, score: {}".format(
e + 1, EPISODES, policy_loss, value_loss, reward_loss, rewards))
agent.plot_score(scores)
cartpole_v1_model.py
from tensorflow.keras import layers, Input, Model
import numpy as np
class representation:
def __init__(self, observation_size):
observation = Input(shape=(observation_size))
x = layers.Flatten()(observation)
x = layers.Dense(units=128, activation='relu')(x)
x = layers.Dense(units=128, activation='relu')(x)
hidden_state = layers.Dense(units=observation_size)(x)
self.model = Model(inputs=observation, outputs=hidden_state)
# self.model.summary()
self.trainable_variables = self.model.trainable_variables
def predict(self, observation):
observation = np.array([observation])
hidden_state = np.array(self.model(observation)[0])
return hidden_state
class dynamics:
def __init__(self, observation_size, action_size):
self.action_size = action_size
hidden_state = Input(shape=(observation_size))
action = Input(shape=(action_size))
x = layers.concatenate([hidden_state, action])
x = layers.Dense(units=128, activation='relu')(x)
x = layers.Dense(units=128, activation='relu')(x)
next_hidden_state = layers.Dense(units=observation_size)(x)
reward = layers.Dense(units=1)(x)
self.model = Model(inputs=[hidden_state, action], outputs=[next_hidden_state, reward])
# self.model.summary()
self.trainable_variables = self.model.trainable_variables
def predict(self, hidden_state, action):
hidden_state = np.array([hidden_state])
action = np.array([[1 if i == action else 0 for i in range(self.action_size)]])
next_hidden_state, reward = self.model([hidden_state, action])
next_hidden_state = np.array(next_hidden_state[0])
reward = np.array(reward[0][0])
return next_hidden_state, reward
class prediction:
def __init__(self, observation_size, action_size):
hidden_state = Input(shape=(observation_size))
x = layers.Dense(units=128, activation='relu')(hidden_state)
x = layers.Dense(units=128, activation='relu')(x)
policy = layers.Dense(units=action_size, activation='softmax')(x)
value = layers.Dense(units=1)(x)
self.model = Model(inputs=hidden_state, outputs=[policy, value])
# self.model.summary()
self.trainable_variables = self.model.trainable_variables
def predict(self, hidden_state):
hidden_state = np.array([hidden_state])
policy, value = self.model(hidden_state)
policy = np.array(policy[0])
value = np.array(value[0][0])
return policy, value
class linner_model:
def __init__(self, observation_size, action_size):
self.representation = representation(observation_size)
self.dynamics = dynamics(observation_size, action_size)
self.prediction = prediction(observation_size, action_size)
self.trainable_variables = self.representation.trainable_variables + \
self.dynamics.trainable_variables + \
self.prediction.trainable_variables
def save_weights(self):
pass
def load_weights(self):
pass
MCTS.py
import numpy as np
PB_C_INIT = 1.25
PB_C_BASE = 19652
class MinMax:
def __init__(self):
self.maximum = -float("inf")
self.minimum = float("inf")
def update(self, value):
self.maximum = max(self.maximum, value)
self.minimum = min(self.minimum, value)
def normalize(self, value):
if self.maximum > self.minimum:
return (value - self.minimum) / (self.maximum - self.minimum)
return value
class TreeNode:
def __init__(self):
self.parent = None
self.prior = 1.0
self.hidden_state = None
self.children = {}
self.visit_count = 0
self.reward = 0
self.Q = 0
def is_leaf_Node(self):
return self.children == {}
def is_root_Node(self):
return self.parent is None
def add_exploration_noise(node, dirichlet_alpha=0.3, exploration_fraction=0.25):
actions = list(node.children.keys())
noise = np.random.dirichlet([dirichlet_alpha] * len(actions))
frac = exploration_fraction
for a, n in zip(actions, noise):
node.children[a].prior = node.children[a].prior * (1 - frac) + n * frac
def ucb_score_Atari(node, minmax, pb_c_init=PB_C_INIT, pb_c_base=PB_C_BASE):
pb_c = np.log(
(node.parent.visit_count + pb_c_base + 1) / pb_c_base
) + pb_c_init
pb_c *= np.sqrt(node.parent.visit_count) / (node.visit_count + 1)
prior_score = pb_c * node.prior
return minmax.normalize(node.Q) + prior_score
def select_argmax_pUCB_child_Atari(node, minmax):
return max(
node.children.items(),
key=lambda key_node_tuple: ucb_score_Atari(key_node_tuple[1], minmax)
)
def expand_Atari(node, model):
if node.parent is not None:
node.hidden_state, node.reward = model.dynamics.predict(node.parent.hidden_state, node.action)
policy, value = model.prediction.predict(node.hidden_state)
node.Q = value
keys = list(range(len(policy)))
for k in keys:
child = TreeNode()
child.action = k
child.prior = policy[k]
child.parent = node
node.children[k] = child
def backpropagate_Atari(node, minmax, discount):
value = node.Q
while True:
node.visit_count += 1
minmax.update(node.Q)
if node.is_root_Node():
break
else:
value = node.reward + discount * value
node = node.parent
node.Q = (node.Q * node.visit_count + value) / (node.visit_count + 1)
class MCTS_Atari:
def __init__(self, model, observation):
self.root_Node = TreeNode()
self.model = model
self.root_Node.hidden_state = self.model.representation.predict(observation)
self.minmax = MinMax()
def simulations(self, num_simulation, discount, add_noise=True):
for _ in range(num_simulation + 1):
node = self.root_Node
while True:
if node.is_leaf_Node():break
else:
_key, node = select_argmax_pUCB_child_Atari(node, self.minmax)
expand_Atari(node, self.model)
if node == self.root_Node and add_noise:
add_exploration_noise(node)
backpropagate_Atari(node, self.minmax, discount)
action_visits = {}
for k, n in self.root_Node.children.items():
action_visits[k] = n.visit_count
return action_visits, self.root_Node.Q
def __str__(self):
return "Muzero_MCTS_Atari"
def ucb_score_Chess(node, minmax, pb_c_init=PB_C_INIT, pb_c_base=PB_C_BASE):
pb_c = np.log(
(node.parent.visit_count + pb_c_base + 1) / pb_c_base
) + pb_c_init
pb_c *= np.sqrt(node.parent.visit_count) / (node.visit_count + 1)
prior_score = pb_c * node.prior
return minmax.normalize(node.Q) + prior_score
def select_argmax_pUCB_child_Chess(node, minmax):
return max(
node.children.items(),
key=lambda key_node_tuple: ucb_score_Chess(key_node_tuple[1], minmax)
)
def expand_Chess(node, model):
if node.parent is not None:
node.hidden_state = model.dynamics.predict(node.parent.hidden_state, node.action)
policy, value = model.prediction.predict(node.hidden_state)
node.Q = value
keys = list(range(len(policy)))
for k in keys:
child = TreeNode()
child.action = k
child.prior = policy[k]
child.parent = node
node.children[k] = child
def backpropagate_Chess(node, minmax):
value = node.Q
while True:
node.visit_count += 1
minmax.update(node.Q)
if node.is_root_Node():
break
else:
value = - value
node = node.parent
node.Q = (node.Q * node.visit_count + value) / (node.visit_count + 1)
class MCTS_Chess:
def __init__(self, model, observation):
self.root_Node = TreeNode()
self.model = model
self.root_Node.hidden_state = self.model.representation.predict(observation)
self.minmax = MinMax()
def simulations(self, num_simulation, add_noise=True):
for _ in range(num_simulation + 1):
node = self.root_Node
while True:
if node.is_leaf_Node(): break
else:
key, node = select_argmax_pUCB_child_Chess(node, self.minmax)
expand_Chess(node, self.model)
if node == self.root_Node and add_noise:
add_exploration_noise(node)
backpropagate_Chess(node, self.minmax)
action_visits = {}
for k, n in self.root_Node.children.items():
action_visits[k] = n.visit_count
return action_visits
def __str__(self):
return "Muzero_MCTS_Chess"
trainer.py
from tensorflow.keras import optimizers, losses
from collections import deque
import tensorflow as tf
import numpy as np
import random
class ReplayBuffer:
def __init__(self, max_size, unroll_steps):
self.memory = deque(maxlen=max_size)
self.unroll = deque(maxlen=unroll_steps)
self.unroll_steps = unroll_steps
def save_memory(self, state, policy, action, reward, value_next, next_state, done):
self.unroll.append([state, policy, action, reward, value_next, next_state, done])
if len(self.unroll) == self.unroll_steps:
self.memory.append(list(self.unroll))
def simple(self, simple_size):
batchs = min(simple_size, len(self.memory))
return random.sample(self.memory, batchs)
def process_data(data):
data = np.array(data)
new_data = []
for d in data:
new_data.append(d.T)
new_data = np.array(new_data).T
return new_data
class Trainer:
def __init__(self, discount, lr=2e-3):
self.optimizer = optimizers.Adam(lr)
self.discount = discount
def update_weight(self, model, replay_buffer, batch_size):
data = replay_buffer.simple(batch_size)
data = process_data(data)
with tf.GradientTape() as tape:
first_observations = np.array(list(data[0][0]))
hidden_state = model.representation.model(first_observations)
policy_targets, value_targets, reward_targets = [], [], []
policy_preds, value_preds, reward_preds = [], [], []
for step in range(len(data)):
policy_pred, value_pred = model.prediction.model(hidden_state)
action = np.array(list(data[step][2]))
hidden_state, reward_pred = model.dynamics.model([hidden_state, action])
policy_target = np.array(list(data[step][1]))
value_target = data[step][3] + self.discount * (1 - data[step][6]) * data[step][4]
value_target = np.reshape(value_target, newshape=(-1, 1))
policy_targets.append(policy_target)
value_targets.append(value_target)
reward_targets.append(np.reshape(data[step][3], newshape=(-1, 1)))
policy_preds.append(policy_pred)
value_preds.append(value_pred)
reward_preds.append(reward_pred)
policy_loss = losses.categorical_crossentropy(
y_pred=policy_preds,
y_true=policy_targets
)
value_loss = losses.mean_squared_error(
y_pred=value_preds,
y_true=value_targets
)
reward_loss = losses.mean_squared_error(
y_pred=reward_preds,
y_true=reward_targets
)
loss = policy_loss + value_loss + reward_loss
grad = tape.gradient(loss, model.trainable_variables)
self.optimizer.apply_gradients(zip(grad, model.trainable_variables))
return tf.reduce_mean(policy_loss), tf.reduce_mean(value_loss), tf.reduce_mean(reward_loss)
训练 500 轮 reward 曲线

更细多线程训练方法
dist_training.py
from network import linner_model
from trainer import ReplayBuffer, Trainer
from MCTS import MCTS_Atari
import matplotlib.pyplot as plt
import multiprocessing
import threading
import numpy as np
import copy
import gym
ENV_NAME = "CartPole-v1"
OBSERVATION_SIZE = 4
ACTION_SIZE = 2
RENDER = False
DISCOUNT = 0.9
NUM_SIMULATIONS = 50
UNROLL_STEPS = 6
MEMORY_SIZE = int(1e6)
SIMPLE_SIZE = 256
EPISODES = 20
WORKERS = 8
def choice_action(observation, model, T=1.0):
MCTS = MCTS_Atari(model, observation)
visit_count, MCTS_value = MCTS.simulations(NUM_SIMULATIONS, DISCOUNT)
visit_counts = list(visit_count.values())
prob = np.array(visit_counts) ** (1 / T) / np.sum(np.array(visit_counts) ** (1 / T))
return np.random.choice(len(prob), p=prob), prob, MCTS_value
def play_warker(pipe):
worker_model = linner_model(OBSERVATION_SIZE, ACTION_SIZE)
env = gym.make(ENV_NAME)
for e in range(EPISODES):
weights = pipe.recv()
worker_model.representation.model.set_weights(weights[0])
worker_model.dynamics.model.set_weights(weights[1])
worker_model.prediction.model.set_weights(weights[2])
state = env.reset()
action_next, policy_next, _ = choice_action(state, worker_model)
rewards = 0
trajectory = []
while True:
if RENDER:
env.render()
action, policy = action_next, policy_next
next_state, reward, done, _ = env.step(action)
action_next, policy_next, value_next = choice_action(next_state, worker_model)
reward = - 100 if done else reward
done = 1 if done else 0
rewards += reward
action_onehot = np.array([1 if i == action else 0 for i in range(ACTION_SIZE)])
trajectory.append([state, policy, action_onehot, reward, value_next, next_state, done])
state = copy.deepcopy(next_state)
if done: break
rewards += 100
pipe.send([trajectory, rewards, e])
def training(trainer, replay_buffer):
global break_train
global global_model
while True:
policy_loss, value_loss, reward_loss, entropy = trainer.update_weight(global_model, replay_buffer, SIMPLE_SIZE)
print("\r policy_loss: {:.2f}, value_loss: {:.2f}, reward_loss:{:.2f}, losses: {:.2f}, entropy: {:.2f}".format(
policy_loss, value_loss, reward_loss, policy_loss + value_loss + reward_loss, entropy),
end="")
if break_train: break
def communication(replay_buffer, pipe_dict):
global global_model
global break_train
while True:
for pipe in pipe_dict.values():
pipe[0].send(
[
global_model.representation.model.get_weights(),
global_model.dynamics.model.get_weights(),
global_model.prediction.model.get_weights()
]
)
avg_rewards = []
es = []
for pipe in pipe_dict.values():
trajectory, rewards, e = pipe[0].recv()
for s_p_a_r_v_n_d in trajectory:
replay_buffer.save_memory(
s_p_a_r_v_n_d[0],
s_p_a_r_v_n_d[1],
s_p_a_r_v_n_d[2],
s_p_a_r_v_n_d[3],
s_p_a_r_v_n_d[4],
s_p_a_r_v_n_d[5],
s_p_a_r_v_n_d[6],
)
avg_rewards.append(rewards)
es.append(e)
r = sum(avg_rewards) / WORKERS
print("\t socres: {:.2f}".format(r))
break_train = all([(i + 1) >= EPISODES for i in es])
if break_train:
break
if __name__ == "__main__":
global_model = linner_model(OBSERVATION_SIZE, ACTION_SIZE)
trainer = Trainer(discount=DISCOUNT)
break_train = False
replay_buffer = ReplayBuffer(MEMORY_SIZE, UNROLL_STEPS)
train_thread = threading.Thread(target=training, args=[trainer, replay_buffer])
train_thread.start()
pipe_dict = {}
for w in range(WORKERS):
pipe_dict["worker_{}".format(str(w))] = multiprocessing.Pipe()
process = []
for w in range(WORKERS):
self_play_process = multiprocessing.Process(
target=play_warker,
args=(
pipe_dict["worker_{}".format(str(w))][1],
)
)
process.append(self_play_process)
[p.start() for p in process]
communication_thread = threading.Thread(target=communication, args=[replay_buffer, pipe_dict])
communication_thread.start()
为防止报错修改的 trainer.py
from tensorflow.keras import optimizers, losses
from collections import deque
import tensorflow as tf
import numpy as np
import random
class ReplayBuffer:
def __init__(self, max_size, unroll_steps):
self.memory = deque(maxlen=max_size)
self.unroll = deque(maxlen=unroll_steps)
self.unroll_steps = unroll_steps
def save_memory(self, state, policy, action, reward, value_next, next_state, done):
self.unroll.append([state, policy, action, reward, value_next, next_state, done])
if len(self.unroll) == self.unroll_steps:
self.memory.append(list(self.unroll))
def simple(self, simple_size):
batchs = min(simple_size, len(self.memory))
return random.sample(self.memory, batchs)
def process_data(data):
data = np.array(data)
new_data = []
for d in data:
new_data.append(d.T)
new_data = np.array(new_data).T
return new_data
class Trainer:
def __init__(self, discount, lr=1e-3):
self.optimizer = optimizers.Adam(lr)
self.discount = discount
def update_weight(self, model, replay_buffer, batch_size, trainin_step=1):
data = replay_buffer.simple(batch_size)
if len(data) == 0: # 为防止在多线程中报错,如果 memory 为空返回 0.0
return 0.0, 0.0, 0.0, 0.0
data = process_data(data)
p_loss, v_loss, r_loss, ent = [], [], [], []
for t in range(trainin_step):
with tf.GradientTape() as tape:
first_observations = np.array(list(data[0][0]))
hidden_state = model.representation.model(first_observations)
policy_targets, value_targets, reward_targets = [], [], []
policy_preds, value_preds, reward_preds = [], [], []
for step in range(len(data)):
policy_pred, value_pred = model.prediction.model(hidden_state)
action = np.array(list(data[step][2]))
hidden_state, reward_pred = model.dynamics.model([hidden_state, action])
policy_target = np.array(list(data[step][1]))
value_target = data[step][3] + self.discount * (1 - data[step][6]) * data[step][4]
value_target = np.reshape(value_target, newshape=(-1, 1))
policy_targets.append(policy_target)
value_targets.append(value_target)
reward_targets.append(np.reshape(data[step][3], newshape=(-1, 1)))
policy_preds.append(policy_pred)
value_preds.append(value_pred)
reward_preds.append(reward_pred)
entropys = []
for policy in policy_preds:
entropy = - np.sum(policy[0] * np.log(policy[0] + 1e-8))
entropys.append(entropy)
policy_loss = losses.categorical_crossentropy(
y_pred=policy_preds,
y_true=policy_targets
)
value_loss = losses.mean_squared_error(
y_pred=value_preds,
y_true=value_targets
)
reward_loss = losses.mean_squared_error(
y_pred=reward_preds,
y_true=reward_targets
)
loss = policy_loss + value_loss + reward_loss
grad = tape.gradient(loss, model.trainable_variables)
self.optimizer.apply_gradients(zip(grad, model.trainable_variables))
p_loss.append(tf.reduce_mean(policy_loss))
v_loss.append(tf.reduce_mean(value_loss))
r_loss.append(tf.reduce_mean(reward_loss))
ent.append(tf.reduce_mean(entropys))
# return tf.reduce_mean(policy_loss), tf.reduce_mean(value_loss), tf.reduce_mean(reward_loss), tf.reduce_mean(entropys)
return np.mean(p_loss), np.mean(v_loss), np.mean(r_loss), np.mean(ent)
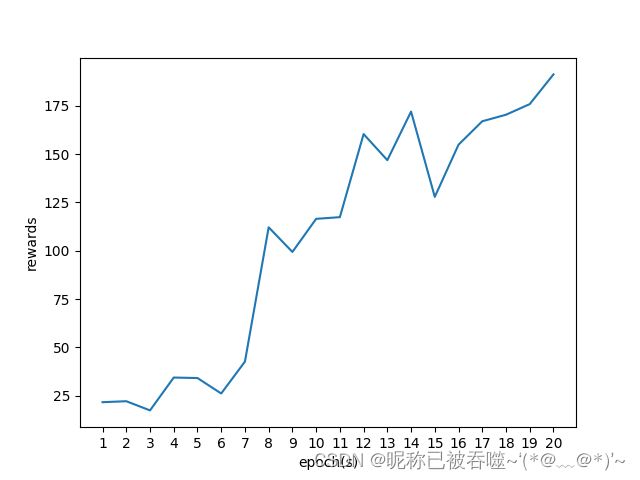
多线程的 20 轮训练的 rewards 曲线