数据挖掘-心跳信号分类预测
task1 baseline
主要工作
1 主要是熟悉一下题目内容,跑通baseline
2 心跳检测,归属到传统机器学习的分类问题。采用的是lightgbm。这个是个结构化赛事比较管用的一个分类器。
3 有一些比较重要的基础内容,需要补充学习一下:
推荐:
机器学习原理与实践
pandas数据处理
Matplotlib可视化
XGBOOST, LIGHTGBM, GBDT等常用大杀器简介
知识点总结
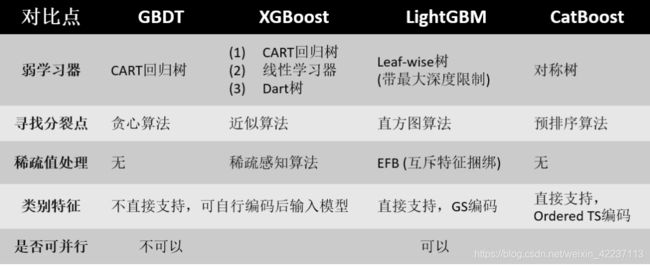

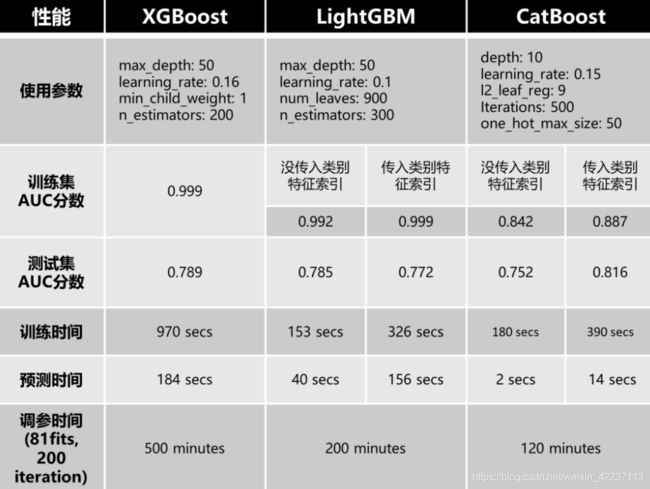
参考上图,我们能看出:
训练集准确度:XGBoost = LightGBM(明确类别特征)>LightGBM(不明确类别特征)>CatBoost(明确类别特征)>CatBoost(不明确类别特征)
测试集准确度:CatBoost(明确类别特征)>XGBoost>LightGBM(不明确类别特征)>LightGBM(明确类别特征)>CatBoost(不明确类别特征)
训练时间:LightGBM(不明确类别特征)>CatBoost(不明确类别特征)>LightGBM(明确类别特征)>CatBoost(明确类别特征)>XGBoost
预测时间:CatBoost(不明确类别特征)>CatBoost(明确类别特征)>LightGBM(不明确类别特征)>LightGBM(明确类别特征)>XGBoost
调参时间:CatBoost>LightGBM>XGBoost
以上结果是针对特定数据集分析的,但实际各模型表现还得看实际数据集和调参设置而定。但总结来说:
XGBoost:训练、预测和调参都是最耗时的。训练集易过拟合,但测试集精度表现不俗,仅次于Catboost(传入类别特征索引)。需要注意,由于XGBoost把类别特征直接当作连续型数值特征看待,一旦遇到类别特征比较重要的数据集,XGBoost就要慎用。
LightGBM:LightGBM本身就是为了保持跟XGBoost相似精度的同时加快训练速度。所以LightGBM速度比XGBoost快,且精确度跟XGBoost近乎相当。需要注意,传入类别特征索引给LightGBM会导致模型过拟合,因为GS编码增大了模型过拟合的风险。所以,如果要在含有类别特征的数据集上使用LightGBM,要么别传入类别特征索引,要么传入类别特征索引后还要留意去调节一些避免过拟合的参数。
CatBoost:相比于其它GBDT模型,CatBoost最不容易过拟合,且在测试集表现很好。但如果明确类别特征,CatBoost会很耗时,因为CatBoost要对指定特征进行Ordered TS编码及特征组合。但如果不明确类别特征,CatBoost在训练、预测和调参上速度很快。需要注意:CatBoost的表现取决于类别特征,只有明确类别特征,CatBoost才会表现很好,但同时速度也会变慢。
截图
task2 数据分析
具体探索的内容参考了:
https://github.com/datawhalechina/team-learning-data-mining/blob/master/HeartbeatClassification/Task2%20%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90.md
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# step1:预览数据的内容,得到初步印象
df = pd.read_csv("data/train.csv",header=None)
df.head()
df.dtypes #查看数据类型
df.info() #数据大小概览
df['label'] = df['label'].astype(int) #将label类型改为int
df.info()
df.isnull().sum(axis=0) #简单查看各列中是否存在缺失值
df.nunique() #观测各列里有几种值,为1时说明该列所有值相同,则该列信息可能无价值
# step2: 图形化显示
#预览数条曲线
y = []
for i in range(20):
temp = df.iloc[i,1].split(",")
temp = list(map(float,temp))
y.append(temp)
y = np.array(y)
plt.figure(figsize=(8,4))
plt.plot(y.T)
plt.show()

task3: 特征工程
数据预处理
- 时间序列数据格式处理
- 加入时间步特征time
特征工程
时间序列特征构造
特征筛选
使用 tsfresh 进行时间序列特征处理
from tsfresh import extract_features
from tsfresh.utilities.dataframe_functions import impute
from tsfresh import select_features
# 特征提取
train_features = extract_features(data_train, column_id='id', column_sort='time')
print(train_features)
# 去除抽取特征中的NaN值
impute(train_features)
# 按照特征和数据label之间的相关性进行特征选择
train_features_filtered = select_features(train_features, data_train_label)
print(train_features_filtered)
可以看到经过特征选择,留下了700个特征。