学习笔记|Pytorch使用教程30(PyTorch常见报错 )
学习笔记|Pytorch使用教程30
本学习笔记主要摘自“深度之眼”,做一个总结,方便查阅。
使用Pytorch版本为1.2
- PyTorch常见报错
- PyTorch框架训练营课程总结
一.PyTorch常见报错
共同贡献PyTorch常见错误与坑汇总文档:
《PyTorch常 见报错/坑汇总》

1.报错: ValueError: num_samples should be a positive integer value, but got num_samples=0
可能的原因:
- 传入的Dataset中的len(self.data_ info)= =0,即传入该dataloader的dataset里没有数据
解决方法:
- 检查dataset中的路径
- 检查Dataset的len__.()函数为何输出为零
测试代码:
import os
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.transforms as transforms
import torchvision.models as models
from torch.utils.data import DataLoader
from tools.my_dataset import RMBDataset
from torch.utils.data import Dataset
from model.lenet import LeNet
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# ========================== 1 num_samples=0
# flag = 0
flag = 1
if flag:
train_dir = os.path.join("..", "data", "rmb_split", "train")
# train_dir = os.path.join("..", "..", "data", "rmb_split", "train")
train_data = RMBDataset(data_dir=train_dir)
# 构建DataLoder
train_loader = DataLoader(dataset=train_data, batch_size=16, shuffle=True)
输出:
Traceback (most recent call last):
File "common_errors.py", line 32, in <module>
train_loader = DataLoader(dataset=train_data, batch_size=16, shuffle=True)
File "/home/omnisky/anaconda3/envs/pytorch/lib/python3.7/site-packages/torch/utils/data/dataloader.py", line 213, in __init__
sampler = RandomSampler(dataset)
File "/home/omnisky/anaconda3/envs/pytorch/lib/python3.7/site-packages/torch/utils/data/sampler.py", line 94, in __init__
"value, but got num_samples={}".format(self.num_samples))
ValueError: num_samples should be a positive integer value, but got num_samples=0
这是路径错误,设置train_dir = os.path.join("..", "..", "data", "rmb_split", "train")
2.报错: TypeError: pic should be PIL Image or ndarray. Got
可能的原因:
- 当前操作需要PIL Image或ndarray数据类型,但传入了Tensor
解决方法:
- 检查transform中是否存在两次ToTensor()方法
- 检查transform中每一一个操作的数据类型变化
测试代码:
# ========================== 2
# TypeError: pic should be PIL Image or ndarray. Got 输出:
Traceback (most recent call last):
File "common_errors.py", line 54, in <module>
data, label = next(iter(train_loader))
File "/home/omnisky/anaconda3/envs/pytorch/lib/python3.7/site-packages/torch/utils/data/dataloader.py", line 346, in __next__
data = self._dataset_fetcher.fetch(index) # may raise StopIteration
File "/home/omnisky/anaconda3/envs/pytorch/lib/python3.7/site-packages/torch/utils/data/_utils/fetch.py", line 44, in fetch
data = [self.dataset[idx] for idx in possibly_batched_index]
File "/home/omnisky/anaconda3/envs/pytorch/lib/python3.7/site-packages/torch/utils/data/_utils/fetch.py", line 44, in <listcomp>
data = [self.dataset[idx] for idx in possibly_batched_index]
File "/home/omnisky/zdh1911/pytorch/07-04-代码-PyTorch常见报错/lesson-31/tools/my_dataset.py", line 34, in __getitem__
img = self.transform(img) # 在这里做transform,转为tensor等等
File "/home/omnisky/anaconda3/envs/pytorch/lib/python3.7/site-packages/torchvision/transforms/transforms.py", line 61, in __call__
img = t(img)
File "/home/omnisky/anaconda3/envs/pytorch/lib/python3.7/site-packages/torchvision/transforms/transforms.py", line 92, in __call__
return F.to_tensor(pic)
File "/home/omnisky/anaconda3/envs/pytorch/lib/python3.7/site-packages/torchvision/transforms/functional.py", line 54, in to_tensor
raise TypeError('pic should be PIL Image or ndarray. Got {}'.format(type(pic)))
TypeError: pic should be PIL Image or ndarray. Got <class 'torch.Tensor'>
需要注释代码:transforms.ToTensor(),
3.报错: RuntimeError: invalid argument 0: Sizes of tensors must match except in dimension 0. Got 93 and 89 in dimension 1 at /Users/soumith/code/builder/wheel/pytorch-src/aten/src/TH/generic/THTensorMath.cpp:3616
可能的原因:
- dataloader的__ getitem__ 函数中 ,返回的图片形状不一致,导致无法stack
解决方法:
- 检查__ getitem__ 函数中的操作
测试代码:
# ========================== 3
# RuntimeError: invalid argument 0: Sizes of tensors must match except in dimension 0
# flag = 0
flag = 1
if flag:
class FooDataset(Dataset):
def __init__(self, num_data, data_dir=None, transform=None):
self.foo = data_dir
self.transform = transform
self.num_data = num_data
def __getitem__(self, item):
size = torch.randint( 64, size=(1, ))
fake_data = torch.zeros((3, size, size))
fake_label = torch.randint(0, 10, size=(1, ))
return fake_data, fake_label
def __len__(self):
return self.num_data
foo_dataset = FooDataset(num_data=10)
foo_dataloader = DataLoader(dataset=foo_dataset, batch_size=4)
data, label = next(iter(foo_dataloader))
输出:
......
return torch.stack(batch, 0, out=out)
RuntimeError: invalid argument 0: Sizes of tensors must match except in dimension 0. Got 4 and 23 in dimension 2 at /pytorch/aten/src/TH/generic/THTensor.cpp:689
尺度(shape)不匹配,设置代码为:size = torch.randint(63, 64, size=(1, ))
4.报错:
conv: RuntimeError: Given groups=1, weight of size 6 1 5 5, expected input[16, 3, 32, 32] to have 1 channels, but got 3 channels instead linear: RuntimeError: size mismatch, m1: [16 x 576], m2: [400 x 120] at …/aten/src/TH/generic/THTensorMath.cpp:752
可能的原因:
- 网络层输入数据与网络的参数不匹配
解决方法:
- 检查对应网络层前后定义是否有误
- 检查输入数据shape
测试代码:
# ========================== 4
# Given groups=1, weight of size 6 3 5 5, expected input[16, 1, 32, 32] to have 3 channels, but got 1 channels instead
# RuntimeError: size mismatch, m1: [16 x 576], m2: [400 x 120] at ../aten/src/TH/generic/THTensorMath.cpp:752
# flag = 0
flag = 1
if flag:
class FooDataset(Dataset):
def __init__(self, num_data, shape, data_dir=None, transform=None):
self.foo = data_dir
self.transform = transform
self.num_data = num_data
self.shape = shape
def __getitem__(self, item):
fake_data = torch.zeros(self.shape)
fake_label = torch.randint(0, 10, size=(1, ))
if self.transform is not None:
fake_data = self.transform(fake_data)
return fake_data, fake_label
def __len__(self):
return self.num_data
# ============================ step 1/5 数据 ============================
channel = 1 # 1 3
img_size = 32 # 36 32
train_data = FooDataset(num_data=32, shape=(channel, img_size, img_size))
train_loader = DataLoader(dataset=train_data, batch_size=16, shuffle=True)
# ============================ step 2/5 模型 ============================
net = LeNet(classes=2)
# ============================ step 3/5 损失函数 ============================
criterion = nn.CrossEntropyLoss()
# ============================ step 4/5 优化器 ============================
optimizer = optim.SGD(net.parameters(), lr=0.01, momentum=0.9) # 选择优化器
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=10)
# ============================ step 5/5 训练 ============================
data, label = next(iter(train_loader))
outputs = net(data)
输出:
......
self.padding, self.dilation, self.groups)
RuntimeError: Given groups=1, weight of size 6 3 5 5, expected input[16, 1, 32, 32] to have 3 channels, but got 1 channels instead
输入输出不匹配,修改代码:channel = 3
如果设置img_size = 36
报错:
......
RuntimeError: size mismatch, m1: [16 x 576], m2: [400 x 120] at /pytorch/aten/src/TH/generic/THTensorMath.cpp:197
5.报错: AttributeError: ‘DataParallel’ object has no attribute ‘linear’
可能的原因:
- 并行运算时,模型被dataparallel包装,所有module都增加一个属性module.因此需要通过net.module.linear调用
解决方法:
- 网络层前加入module.
测试代码:
# ========================== 5
# AttributeError: 'DataParallel' object has no attribute 'linear'
# flag = 0
flag = 1
if flag:
class FooNet(nn.Module):
def __init__(self):
super(FooNet, self).__init__()
self.linear = nn.Linear(3, 3, bias=True)
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool1 = nn.MaxPool2d(5)
def forward(self, x):
return 1234567890
net = FooNet()
for layer_name, layer in net.named_modules():
print(layer_name)
net = nn.DataParallel(net)
for layer_name, layer in net.named_modules():
print(layer_name)
print(net.linear)
输出:
linear
conv1
pool1
module
module.linear
module.conv1
module.pool1
Traceback (most recent call last):
File "common_errors.py", line 157, in <module>
print(net.linear)
File "/home/omnisky/anaconda3/envs/pytorch/lib/python3.7/site-packages/torch/nn/modules/module.py", line 585, in __getattr__
type(self).__name__, name))
AttributeError: 'DataParallel' object has no attribute 'linear'
修改代码:print(net.module.linear)
输出:
linear
conv1
pool1
module
module.linear
module.conv1
module.pool1
Linear(in_features=3, out_features=3, bias=True)
6.报错:
RuntimeError: Attempting to deserialize object on a CUDA device but torch.cuda.is_ available() is False. If you are running on a CPU-only machine, please use torch.load with map_location= torch.device(‘cpu’) to map your storages to the CPU.
可能的原因:
- gpu训练的模型保存后,在无gpu设备上无法直接加载
解决方法:
- 需要设置map_ location= “cpu”
# ========================== 6
# RuntimeError: Attempting to deserialize object on a CUDA device but torch.cuda.is_available() is False.
# If you are running on a CPU-only machine, please use torch.load with map_location=torch.device('cpu')
# to map your storages to the CPU.
# flag = 0
flag = 1
if flag:
path_state_dict = "./model_in_multi_gpu.pkl"
state_dict_load = torch.load(path_state_dict)
# state_dict_load = torch.load(path_state_dict, map_location="cpu")
7.报错:
AttributeError: Can’t get attribute ‘FooNet2’ on
可能的原因:
- 保存的网络模型在当前python脚本中没有定义
解决方法:
- 提前定义该类
测试代码:
# ========================== 7
# AttributeError: Can't get attribute 'FooNet2' on
# flag = 0
flag = 1
if flag:
path_net = os.path.join(BASE_DIR, "foo_net.pkl")
# save
"""
class FooNet2(nn.Module):
def __init__(self):
super(FooNet2, self).__init__()
self.linear = nn.Linear(3, 3, bias=True)
def forward(self, x):
return 1234567890
"""
#
# net = FooNet2()
# torch.save(net, path_net)
# load
net_load = torch.load(path_net)
输出:
......
AttributeError: Can't get attribute 'FooNet2' on __main__' from 'common_errors.py'>
这是因为类没有被定义。
8.报错:
RuntimeError: Assertion ‘cur. target >= 0 && cur. target < n classes’ failed. at …/aten/src/THNN/generic/ClassNLLCriterion.c:94
可能的原因:
- 标签数大于等于类别数量,即不满足cur_ target < n_ classes,通常是因为标签从1开始而不是从0开始
解决方法:
- 修改label从0开始
测试代码:
# ========================== 8
# RuntimeError: Assertion `cur_target >= 0 && cur_target < n_classes' failed.
# flag = 0
flag = 1
if flag:
inputs = torch.tensor([[1, 2], [1, 3], [1, 3]], dtype=torch.float)
target = torch.tensor([0, 0, 2], dtype=torch.long)
criterion = nn.CrossEntropyLoss()
loss = criterion(inputs, target)
输出:
.......
RuntimeError: Assertion `cur_target >= 0 && cur_target < n_classes' failed. at /pytorch/aten/src/THNN/generic/ClassNLLCriterion.c:97
修改代码为:target = torch.tensor([0, 0, 1], dtype=torch.long)
9.报错:
RuntimeError: expected device cuda:0 and dtype Long but got device cpu and dtype Long
Expected object of backend CPU but got backend CUDA for argument #2 ‘weight’
可能的原因:
- 需计算的两个数据不在同一个设备上
解决方法:
- 采用to函数将数据迁移到同一个设备上
测试代码:
# ========================== 9
# RuntimeError: expected device cuda:0 and dtype Long but got device cpu and dtype Long
# flag = 0
flag = 1
if flag:
x = torch.tensor([1])
w = torch.tensor([2]).to(device)
y = w * x
#x = x.to(device)
#y = w * x
输出:
y = w * x
RuntimeError: expected device cuda:0 but got device cpu
修改为:
flag = 1
if flag:
x = torch.tensor([1])
w = torch.tensor([2]).to(device)
# y = w * x
x = x.to(device)
y = w * x
输出:
outputs device:cuda:0
outputs device:cuda:0
10.报错:
RuntimeError: DataLoader worker (pid 27) is killed by signal: Killed. Details are lost due to multiprocessing. Rerunning with num_ workers=0 may give better error trace.
可能原因:
- 内存不够(不是gpu显存,是内存)
解决方法:
- 申请更大内存
测试代码:
# ========================== 10
# RuntimeError: Expected object of backend CPU but got backend CUDA for argument #2 'weight'
# flag = 0
flag = 1
if flag:
def data_loader(num_data):
for _ in range(num_data):
img_ = torch.randn(1, 3, 224, 224)
label_ = torch.randint(0, 10, size=(1,))
yield img_, label_
resnet18 = models.resnet18()
resnet18.to(device)
for inputs, labels in data_loader(2):
inputs.to(device)
labels.to(device)
outputs = resnet18(inputs)
"""
inputs = inputs.to(device)
labels = labels.to(device)
outputs = resnet18(inputs)
"""
print("outputs device:{}".format(outputs.device))
输出:
RuntimeError: Input type (torch.FloatTensor) and weight type (torch.cuda.FloatTensor) should be the same
修改代码:
inputs = inputs.to(device)
labels = labels.to(device)
outputs = resnet18(inputs)
输出:
outputs device:cuda:0
outputs device:cuda:0
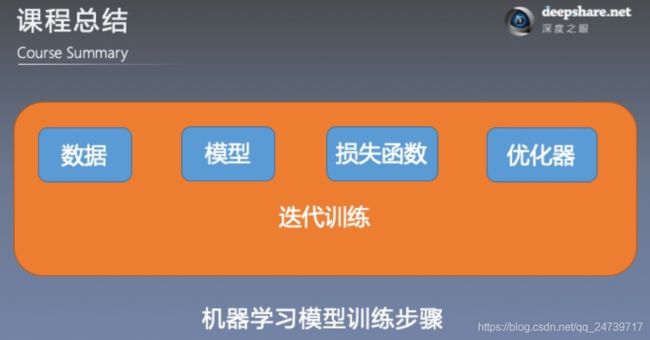
二.PyTorch框架训练营课程总结