自然语言处理(持续更新中...)
文章目录
-
- @[TOC](文章目录)
- 前言#
- 一、文本表示
-
- 1.1词的独热表示
- 1.2词的分布式表示
-
- 1.2.1分布式语义假设
- 1.2.2点互信息
- 1.2.3奇异值分解
- 1.3词嵌入式
- 1.4文本的词袋表示
- 二、自然语言处理任务
-
- 2.1语言模型
- 2.2自然语言处理基础任务
-
- 2.2.1中文分词
- 2.2.2子词切分(Subword)
- 2.2.3字节对编码(Byte Pair Encoding,BPE)
- 2.2.4句法分析
- 2.2.5信息抽取
- 2.2.6情感分析
- 2.2.7问答系统
- 总结
- 参考:
-
- 参考教材:
文章目录
-
- @[TOC](文章目录)
- 前言#
- 一、文本表示
-
- 1.1词的独热表示
- 1.2词的分布式表示
-
- 1.2.1分布式语义假设
- 1.2.2点互信息
- 1.2.3奇异值分解
- 1.3词嵌入式
- 1.4文本的词袋表示
- 二、自然语言处理任务
-
- 2.1语言模型
- 2.2自然语言处理基础任务
-
- 2.2.1中文分词
- 2.2.2子词切分(Subword)
- 2.2.3字节对编码(Byte Pair Encoding,BPE)
- 2.2.4句法分析
- 2.2.5信息抽取
- 2.2.6情感分析
- 2.2.7问答系统
- 总结
- 参考:
-
- 参考教材:
前言#
自然语言处理的基础问题:文本如何在计算机内表示,才能达到易于处理和计算的目的。
词的表示大体经过:独热表示、分布式表示、词向量表示。
三大类自然语言处理任务:语言模型、基础任务、应用任务。
基础任务包括:中文分词、词性标注、句法分析、语义分析。
应用任务包括信息抽取、情感分析、问答系统、机器翻译、对话系统。
任务基础包括文本分类、结构预测、序列到序列。
提示:以下是本篇文章正文内容
一、文本表示
1.1词的独热表示
词的独热表示,即使用一个词表大小的向量表示一个词,然后将词表中的第i个词wi表示为向量。
在该向量中,词中第i个词在第i维上被设置为1,其他维均为0。
缺点:独热模型会导致数据稀疏问题。
为了缓解数据稀疏问题,可以提取更多和词相关的泛化特征:词性特征、词义特征(WordNet)、词类聚特征。
1.2词的分布式表示
1.2.1分布式语义假设
分布式语义假设:词的含义可由其上下文的分布进行表示。
以词所在句子中的其他词语作为上下文,创建词语共现频次表。
存在问题:1.高频词误导计算结果 2.共现频次无法反映词之间的高阶关系(无法传递关系)。3.仍然存在稀疏性问题(向量中还存在着大量的值为0)。
1.2.2点互信息
主要针对分布式语义假设出现的问题(高频词误导计算结果)。
直接想法:如果一个词与很多词共现,则降低其权重;反之如果一个词只与个别词共现,则提高其权重。分别是共现概率、w和c单独出现的概率
![]()
通过PMI计算可知:如果共现概率较高、单独出现的概率也较高,则PMI值会变小;反之PMI值会变大。可以较好的解决高频词误导计算结果的问题。
当共现频率出现次数较低时,PMI可能会出现负值。
所以需要PMII(w,c)=max(PMII(w,c),0)
1.2.3奇异值分解
解决共现频次无法反映词之间的高阶关系。
对共现矩阵进行奇异值分解:
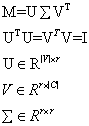
1.3词嵌入式
分布式表示一旦完成训练,则无法修改。
词嵌入表示也使用一个连续、低维、稠密的向量来表示词,称为词向量。
与分布式表示的区别在于:其赋值方式不同。
词向量中的向量值是随着目标任务的优化过程而自动调整的。
具体步骤:先利用自然语言文本中所蕴含的自监督信号(即上下文的共现信息),预训练词向量
1.4文本的词袋表示
词袋表示,就是假设文本中的词语是没有顺讯的集合,将文本中的全部词所对应的向量表示相加(可以是独热,分布式或者是独热+分布式)。
优点:简单、直观
缺点:
1.没有考虑词的顺序信息,导致顺序不同,结果一样
2.无法融入上下文信息
解决方法:增加词表(治标不治本,词表增大会导致数据稀疏性)
二、自然语言处理任务
三大类自然语言处理任务:语言模型、基础任务、应用任务
2.1语言模型
语言模型(Language Model,LM)描述一段自然语言的概率或给定上文时下一个词出现的概率
![]()
以上两种定义等价(链式法则)
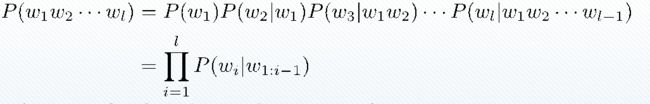
广泛应用于多种自然语言处理任务
机器翻译(词排序) P(the cat is small) > P(small the is cat)
语音识别(词选择) P(there are four cats) > P(there are for cats)
2.2自然语言处理基础任务
2.2.1中文分词
词(Word)
最小的能独立使用的音义结合体
以汉语为代表的汉藏语系,以阿拉伯语为代表的闪-含语系中不包含明显的词之间的分隔符
中文分词是将中文字序列切分成一个个单独的词
分词的歧义 如:
严守一把手机关了
严守一/ 把/ 手机/ 关/ 了
严守/ 一把手/ 机关/ 了
严守/ 一把/ 手机/ 关/ 了
严守一/把手/ 机关/ 了
……
2.2.2子词切分(Subword)
以英语为代表的印欧语系语言,是否需要进行分词?
这些语言词形变化复杂
如:computer、computers、computing等
仅用空格切分的问题
- 数据稀疏
- 词表过大,降低处理速度
子词切分
将一个单词切分为若干连续的片段(子词)
方法众多,基本原理相似
使用尽量长且频次高的子词对单词进行切分
2.2.3字节对编码(Byte Pair Encoding,BPE)
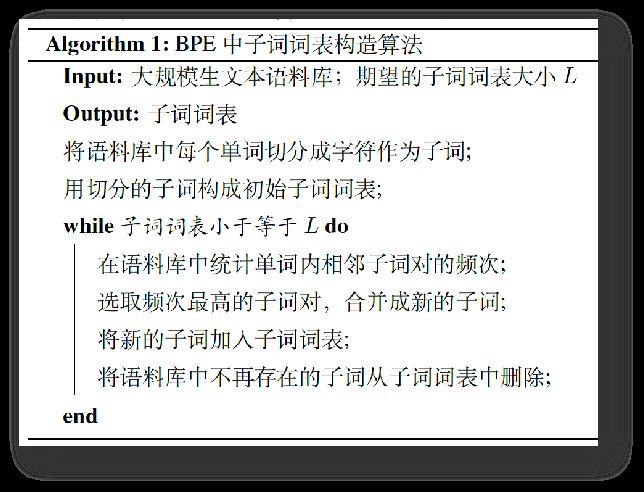

BPE子词切分算法
- 将子词词表按照子词的长度由大到小进行排序
- 从前向后遍历子词词表,依次判断一个子词是否为单词的子串
- 如果是则将该单词进行切分,然后继续向后遍历子词词表
- 如果子词词表全部遍历结束,单词中仍然有子串没有被切分,那么这些子串一定为低频串,则使用统一的标记,如’'进行替换
更多子词切分算法
- WordPiece
- Unigram Language Model(ULM)
- SentencePiece : https://github.com/google/sentencepiece
2.2.4句法分析
- 分析句子的句法成分,如主谓宾定状补等
- 将词序列表示的句子转换成树状结构
- 词义消歧(Word Sense Disambiguation,WSD)
- 语义角色标注(Semantic Role Labeling,SRL)也称谓词论元结构(Predicate-Argument Structure)
- 语义依存图(Semantic Dependency Graph)
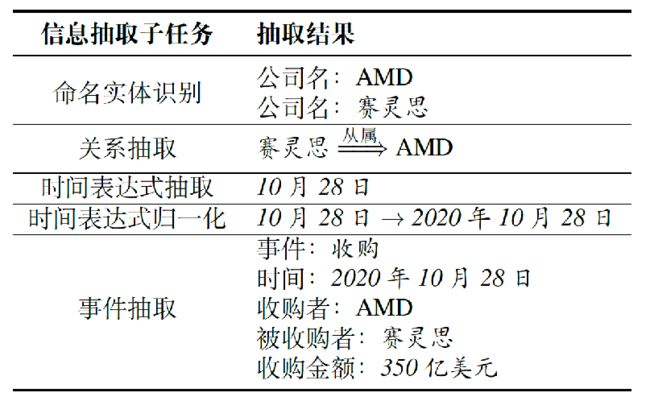
2.2.5信息抽取
信息抽取(Information Extraction,IE)从非结构化的文本中自动提取结构化信息
例子:
输入:10月28日,AMD宣布斥资350亿美元收购FPGA芯片巨头赛灵思。这两家传了多年绯闻的芯片公司终于走到了一起。
2.2.6情感分析
情感分析(Sentiment Analysis)
·个体对外界事物的态度、观点或倾向性,如正面、负面等
·人自身的情绪(Emotion),如喜怒哀惧等
例子:
输入:这款手机的屏幕很不错,性能也还可以。

2.2.7问答系统
问答系统(Question Answering,QA)
用户以自然语言形式描述问题,从异构数据中获得答案
根据数据来源的不同,问答系统可以分为4种主要的类型
- 检索式问答系统 :
答案来源于固定的文本语料库或互联网,系统通过查找相关文档并抽取答案完成问答 - 知识库问答系统:
回答问题所需的知识以数据库等结构化形式存储,问答系统首先将问题解析为结构化的查询语句通过查询相关知识点,并结合知识推理获取答案 - 常问问题集问答系统:
通过对历史积累的常问问题集合进行检索,回答用户提出的类似问题 - 阅读理解式问答系统:
通过抽取给定文档中的文本片段或生成一段答案来回答用户提出的问题
总结
参考:
参考教材:
《自然语言处理:基于预训练模型的方法》
出版社:电子工业出版社
作者:车万翔,郭江,崔一鸣 著;刘挺 主审
书号:ISBN 978-7-121-41512-8
出版时间:2021.7
网购链接 https://item.jd.com/13344628.html
书中代码 https://github.com/HIT-SCIR/plm-nlp-code
