直通大厂:6年工作经验面了腾讯云,聊聊什么是零拷贝?
前言
大家好,小编最近一位朋友(6年工作经验)面试了腾讯云,应广大网友要求,向他请教了整理出面试题和答案。加油,一起卷!
- 聊聊项目,好的设计,好的代码
- 谈谈什么是零拷贝?
- 一共有几种 IO 模型?NIO 和多路复用的区别?
- Future 实现阻塞等待获取结果的原理?
- ReentrantLock和 Synchronized 的区别?Synchronized 的原理?
- 聊聊AOS?ReentrantLock的实现原理?
- 乐观锁和悲观锁, 让你来写你怎么实现?
- Paxos 协议了解?工作流程是怎么样的?
- B+树聊一下?B+树是不是有序?B+树和B-树的主要区别?B+树索引,一次查找过程?
- TCP的拥塞机制
- 聊聊JVM调优
- 数据库分库分表的缺点是啥?
- 分布式事务如何解决?TCC 了解?
- RocketMQ 如何保证消息的准确性和安全性?
- 算法题:三个数求和
1.聊聊项目,好的设计,好的代码
项目的话,你可以聊聊你平时做的项目,尤其是有亮点的项目。如果没有什么特别亮点的项目,也可以说说一些好的设计,或者你优化了什么接口,性能提升了多少,优化了什么慢SQL都可以。甚至是一些好的代码写法都可以。
如果是讲优化接口的话,你可以看下我这篇文章哈:
记一次接口性能优化实践总结:优化接口性能的八个建议
如果是代码优化细节,可以看我这篇文章:
工作四年,分享50个让你代码更好的小建议
如果是慢SQL优化,可以看下我之前MySQL专栏系列文章哈:
- 看一遍就理解:order by详解
- 看一遍就能理解:group by详解
- 实战!聊聊如何解决MySQL深分页问题
- 后端程序员必备:书写高质量SQL的30条建议
- 阿里一面,给了几条SQL,问需要执行几次树搜索操作?
- 生产问题分析!delete in子查询不走索引?!
2. 谈谈什么是零拷贝?
零拷贝是指计算机执行IO操作时,CPU不需要将数据从一个存储区域复制到另一个存储区域,从而可以减少上下文切换以及CPU的拷贝时间。它是一种I/O操作优化技术。
传统 IO 的执行流程
传统的IO流程,包括read和write的过程。
- read:把数据从磁盘读取到内核缓冲区,再拷贝到用户缓冲区
- write:先把数据写入到socket缓冲区,最后写入网卡设备。

- 用户应用进程调用read函数,向操作系统发起IO调用,上下文从用户态转为内核态(切换1)
- DMA控制器把数据从磁盘中,读取到内核缓冲区。
- CPU把内核缓冲区数据,拷贝到用户应用缓冲区,上下文从内核态转为用户态(切换2),read函数返回
- 用户应用进程通过write函数,发起IO调用,上下文从用户态转为内核态(切换3)
- CPU将用户缓冲区中的数据,拷贝到socket缓冲区
- DMA控制器把数据从socket缓冲区,拷贝到网卡设备,上下文从内核态切换回用户态(切换4),write函数返回
传统IO的读写流程,包括了4次上下文切换(4次用户态和内核态的切换),4次数据拷贝(两次CPU拷贝以及两次的DMA拷贝)。
零拷贝实现方式:
零拷贝并不是没有拷贝数据,而是减少用户态/内核态的切换次数以及CPU拷贝的次数。零拷贝一般有这三种实现方式:
- mmap+write
- sendfile
- 带有DMA收集拷贝功能的sendfile
mmap+write
mmap就是用了虚拟内存这个特点,它将内核中的读缓冲区与用户空间的缓冲区进行映射,以减少数据拷贝次数!
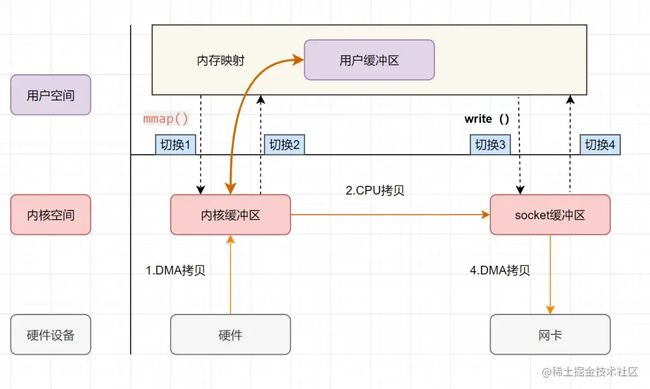
- 用户进程通过mmap方法向操作系统内核发起IO调用,上下文从用户态切换为内核态。
- CPU利用DMA控制器,把数据从硬盘中拷贝到内核缓冲区。
- 上下文从内核态切换回用户态,mmap方法返回。
- 用户进程通过write方法向操作系统内核发起IO调用,上下文从用户态切换为内核态。
- CPU将内核缓冲区的数据拷贝到的socket缓冲区。
- CPU利用DMA控制器,把数据从socket缓冲区拷贝到网卡,上下文从内核态切换回用户态,write调用返回。
mmap+write实现的零拷贝,I/O发生了4次用户空间与内核空间的上下文切换,以及3次数据拷贝(包括了2次DMA拷贝和1次CPU拷贝)。
sendfile
sendfile表示在两个文件描述符之间传输数据,它是在操作系统内核中操作的,避免了数据从内核缓冲区和用户缓冲区之间的拷贝操作
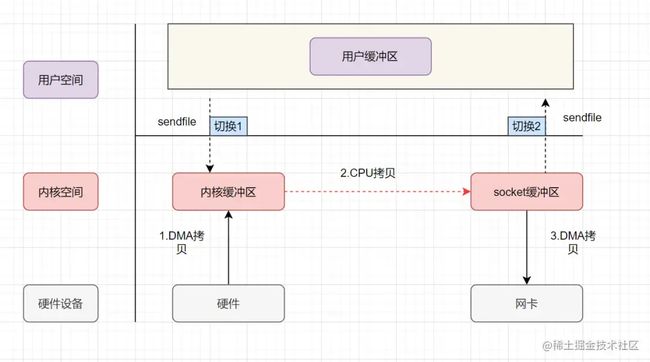
- 用户进程发起sendfile系统调用,上下文(切换1)从用户态转向内核态
- DMA控制器,把数据从硬盘中拷贝到内核缓冲区。
- CPU将读缓冲区中数据拷贝到socket缓冲区
- DMA控制器,异步把数据从socket缓冲区拷贝到网卡,
- 上下文(切换2)从内核态切换回用户态,sendfile调用返回。
sendfile实现的零拷贝,I/O发生了2次用户空间与内核空间的上下文切换,以及3次数据拷贝。其中3次数据拷贝中,包括了2次DMA拷贝和1次CPU拷贝。
带有DMA收集拷贝功能的sendfile
linux 2.4版本之后,对sendfile做了优化升级,引入SG-DMA技术,其实就是对DMA拷贝加入了scatter/gather操作,它可以直接从内核空间缓冲区中将数据读取到网卡。使用这个特点搞零拷贝,即还可以多省去一次CPU拷贝。
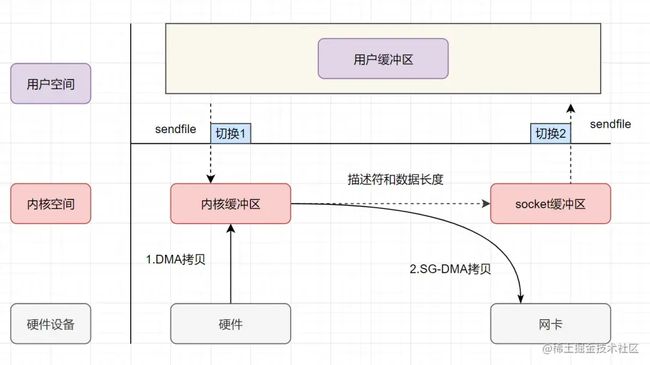
- 用户进程发起sendfile系统调用,上下文(切换1)从用户态转向内核态
- DMA控制器,把数据从硬盘中拷贝到内核缓冲区。
- CPU把内核缓冲区中的文件描述符信息(包括内核缓冲区的内存地址和偏移量)发送到socket缓冲区
- DMA控制器根据文件描述符信息,直接把数据从内核缓冲区拷贝到网卡
- 上下文(切换2)从内核态切换回用户态,sendfile调用返回。
可以发现,sendfile+DMA scatter/gather实现的零拷贝,I/O发生了2次用户空间与内核空间的上下文切换,以及2次数据拷贝。其中2次数据拷贝都是包DMA拷贝。这就是真正的 零拷贝(Zero-copy) 技术,全程都没有通过CPU来搬运数据,所有的数据都是通过DMA来进行传输的。
看一遍就理解:零拷贝详解
3. 一共有几种 IO 模型?NIO 和多路复用的区别?
一共有五种IO模型
- 阻塞IO模型
- 非阻塞IO模型
- IO多路复用模型
- IO模型之信号驱动模型
- IO 模型之异步IO(AIO)
NIO(非阻塞IO模型)
NIO,即Non-Blocking IO,是非阻塞IO模型。非阻塞IO的流程如下:
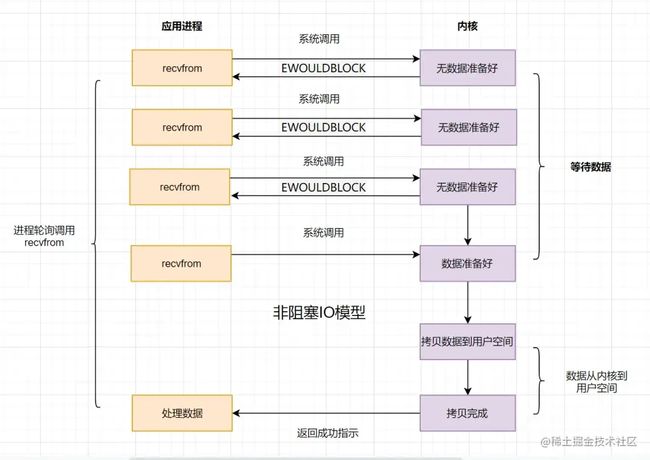
- 应用进程向操作系统内核,发起recvfrom读取数据。
- 操作系统内核数据没有准备好,立即返回EWOULDBLOCK错误码。
- 应用程序进程轮询调用,继续向操作系统内核发起recvfrom读取数据。
- 操作系统内核数据准备好了,从内核缓冲区拷贝到用户空间。
- 完成调用,返回成功提示。
NIO(非阻塞IO模型)存在性能问题,即频繁的轮询,导致频繁的系统调用,同样会消耗大量的CPU资源。可以考虑IO复用模型去解决这个问题。
IO多路复用模型
IO多路复用就是,等到内核数据准备好了,主动通知应用进程再去进行系统调用。
IO复用模型核心思路:系统给我们提供一类函数(如我们耳濡目染的select、poll、epoll函数),它们可以同时监控多个fd的操作,任何一个返回内核数据就绪,应用进程再发起recvfrom系统调用。
IO多路复用之select
应用进程通过调用select函数,可以同时监控多个fd,在select函数监控的fd中,只要有任何一个数据状态准备就绪了,select函数就会返回可读状态,这时应用进程再发起recvfrom请求去读取数据。

非阻塞IO模型(NIO)中,需要N(N>=1)次轮询系统调用,然而借助select的IO多路复用模型,只需要发起一次询问就够了,大大优化了性能。
但是呢,select有几个缺点:
- 监听的IO最大连接数有限,在Linux系统上一般为1024。
- select函数返回后,是通过遍历fdset,找到就绪的描述符fd。(仅知道有I/O事件发生,却不知是哪几个流,所以遍历所有流)
因为存在连接数限制,所以后来又提出了poll。与select相比,poll解决了连接数限制问题。但是呢,select和poll一样,还是需要通过遍历文件描述符来获取已经就绪的socket。如果同时连接的大量客户端,在一时刻可能只有极少处于就绪状态,伴随着监视的描述符数量的增长,效率也会线性下降。
IO多路复用之epoll
为了解决select/poll存在的问题,多路复用模型epoll诞生,它采用事件驱动来实现,流程图如下:
epoll先通过epoll_ctl()来注册一个fd(文件描述符),一旦基于某个fd就绪时,内核会采用回调机制,迅速激活这个fd,当进程调用epoll_wait()时便得到通知。这里去掉了遍历文件描述符的坑爹操作,而是采用监听事件回调的机制。这就是epoll的亮点。
4. Future 实现阻塞等待获取结果的原理?
Future.get()用于异步结果的获取。它是阻塞的,背后原理是什么呢?
我们可以看下FutureTask的类结构图:
FutureTask实现了RunnableFuture接口,RunnableFuture继承了Runnable和Future这两个接口, 对于Runnable,我们太熟悉了, 那么Future呢?
Future 表示一个任务的生命周期,并提供了相应的方法来判断是否已经完成或取消,以及获取任务的结果和取消任务等。
public interface Future {
boolean cancel(boolean mayInterruptIfRunning);
//Future 是否被取消
boolean isCancelled();
//当前 Future 是否已结束
boolean isDone();
//或取Future的结果值。如果当前 Future 还没有结束,当前线程阻塞等待,
V get() throws InterruptedException, ExecutionException;
//获取 Future 的结果值。与 get()一样,不过多了超时时间设置
V get(long timeout, TimeUnit unit)
throws InterruptedException, ExecutionException, TimeoutException;
}
复制代码 FutureTask 就是Runnable和Future的结合体,我们可以把Runnable看作生产者, Future 看作消费者。而FutureTask 是被这两者共享的,生产者运行run方法计算结果,消费者通过get方法获取结果。
生产者消费者模式,如果生产者数据还没准备的时候,消费者会被阻塞。当生产者数据准备好了以后会唤醒消费者继续执行。我们来看下FutureTask内部是如何实现的。
FutureTask内部维护了任务状态state
//NEW 新建状态,表示FutureTask新建还没开始执行
private static final int NEW = 0;
//完成状态,表示FutureTask
private static final int COMPLETING = 1;
//任务正常完成,没有发生异常
private static final int NORMAL = 2;
//发生异常
private static final int EXCEPTIONAL = 3;
//取消任务
private static final int CANCELLED = 4;
//发起中断请求
private static final int INTERRUPTING = 5;
//中断请求完成
private static final int INTERRUPTED = 6;
复制代码生产者run方法:
public void run() {
// 如果状态state不是 NEW,或者设置 runner 值失败,直接返回
if (state != NEW ||
!UNSAFE.compareAndSwapObject(this, runnerOffset,
null, Thread.currentThread()))
return;
try {
Callable c = callable;
if (c != null && state == NEW) {
V result;
boolean ran;
try {
//调用callable的call方法,获取结果
result = c.call();
//运行成功
ran = true;
} catch (Throwable ex) {
result = null;
//运行不成功
ran = false;
//设置异常
setException(ex);
}
//运行成功设置返回结果
if (ran)
set(result);
}
} finally {
runner = null;
int s = state;
if (s >= INTERRUPTING)
handlePossibleCancellationInterrupt(s);
}
}
复制代码 消费者的get方法
public V get() throws InterruptedException, ExecutionException {
int s = state;
//如果状态小于等于 COMPLETING,表示 FutureTask 任务还没有完成, 则调用awaitDone让当前线程等待。
if (s <= COMPLETING)
s = awaitDone(false, 0L);
return report(s);
}
复制代码awaitDone做了什么事情呢?
private int awaitDone(boolean timed, long nanos)
throws InterruptedException {
final long deadline = timed ? System.nanoTime() + nanos : 0L;
WaitNode q = null;
boolean queued = false;
for (;;) {
// 如果当前线程是中断标记,则
if (Thread.interrupted()) {
//那么从列表中移除节点 q,并抛出 InterruptedException 异常
removeWaiter(q);
throw new InterruptedException();
}
int s = state;
//如果状态已经完成,表示FutureTask任务已结束
if (s > COMPLETING) {
if (q != null)
q.thread = null;
//返回
return s;
}
// 表示还有一些后序操作没有完成,那么当前线程让出执行权
else if (s == COMPLETING) // cannot time out yet
Thread.yield();
//将当前线程阻塞等待
else if (q == null)
q = new WaitNode();
else if (!queued)
queued = UNSAFE.compareAndSwapObject(this, waitersOffset,
q.next = waiters, q);
//timed 为 true 表示需要设置超时
else if (timed) {
nanos = deadline - System.nanoTime();
if (nanos <= 0L) {
removeWaiter(q);
return state;
}
//让当前线程等待 nanos 时间
LockSupport.parkNanos(this, nanos);
}
else
LockSupport.park(this);
}
}
复制代码当然,面试的时候,不一定要讲到源码这么细,只需要将个大概思路就好啦。
5. ReentrantLock和 Synchronized 的区别?Synchronized 的原理?
ReentrantLock和 Synchronized 的区别?
- Synchronized是依赖于JVM实现的,而ReenTrantLock是API实现的。
- 在Synchronized优化以前,synchronized的性能是比ReenTrantLock差很多的,但是自从Synchronized引入了偏向锁,轻量级锁(自旋锁)后,两者性能就差不多了。
- Synchronized的使用比较方便简洁,它由编译器去保证锁的加锁和释放。而ReenTrantLock需要手工声明来加锁和释放锁,最好在finally中声明释放锁。
- ReentrantLock可以指定是公平锁还是⾮公平锁。⽽synchronized只能是⾮公平锁。
- ReentrantLock可响应中断、可轮回,而Synchronized是不可以响应中断的,
至于Synchronized的原理,大家可以看我这篇文章哈
Synchronized解析——如果你愿意一层一层剥开我的心
6. 聊聊AOS?ReentrantLock的实现原理?
AQS(抽象同步队列)的核心回答要点就是:
- state 状态的维护。
- CLH队列
- ConditionObject通知
- 模板方法设计模式
- 独占与共享模式。
- 自定义同步器。
大家可以看下我之前这篇文章哈:AQS解析与实战
大家综合ReentrantLock的功能,比如可重入,公平锁,非公平锁等,与AQS结合一起讲就好啦。
7. 乐观锁和悲观锁, 让你来写你怎么实现?
悲观锁:
悲观锁她专一且缺乏安全感了,她的心只属于当前线程,每时每刻都担心着它心爱的数据可能被别的线程修改。因此一个线程拥有(获得)悲观锁后,其他任何线程都不能对数据进行修改啦,只能等待锁被释放才可以执行。
- SQL语句select ...for update就是悲观锁的一种实现
- 还有Java的synchronized关键字也是悲观锁的一种体现
乐观锁:
乐观锁的很乐观,它认为数据的变动不会太频繁,操作时一般都不会产生并发问题。因此,它不会上锁,只是在更新数据时,再去判断其他线程在这之前有没有对数据进行过修改。实现方式:乐观锁一般会使用版本号机制或CAS算法实现。
之前业务上使用过CAS解决并发问题,大家有兴趣可以看一下哈:
- CAS乐观锁解决并发问题的一次实践
8. Paxos 协议了解?工作流程是怎么样的?
8.1 为什么需要Paxos算法?
当前我们应用都是集群部署的,要求所有机器状态一致。假设当前有两台机器A和B,A要把状态修改为a,B要把状态修改为b,那么应该听谁的呢?这时候可以像2PC一样,引入一个协调者,谁最先到就听谁的。
这里有个问题,就是协调者是单节点,如果它挂了呢。因为可以引入多个协调者
但是这么多协调者,应该听谁的呢?
引入Paxos算法解决这个问题,Paxos算法是一种基于消息传递的分布式一致性算法。
8.2 Paxos的角色
Paxos涉及三种角色,分别是Proposer、Accecptor 、Learners。
- Proposer:它可以提出提案 (Proposal),提案信息包括提案编号和提案值。
- Acceptor:接受接受(accept)提案。一旦接受提案,提案里面的提案值(可以用V表示)就被选定了。
- Learner: 哪个提案被选定了, Learner就学习这个被选择的提案
一个进程可能是Proposer,也可能是Acceptor,也可能是Learner。
8.2 Paxos算法推导过程
一致性算法需要前置条件
在这些被提出的提案中,只有一个会被选定 如果没有提案被提出,就不应该有被选定的提案
-当提案被选定后,learner可以学习被选中的提案
假设只有一个Acceptor,只要Acceptor接受它收到的第一个提案,就可以保证只有一个value会被选定。但是这个 Acceptor 宕机,会导致整个系统不可用。
如果是是多个Proposer和多个Acceptor,如何选定一个提案呢?
我们可以加个约定条件,假设就叫约束P1:一个 Acceptor 必须接受它收到的第一个提案。但是这样还是可能会有问题,如果每个Proposer分别提出不同的value(如下图V1,V2,V3),发给了不同的Acceptor,最后会导致不同的value被选择。
我们可以给多一个额外的约定P1a:一个提案被选定,需要被半数以上 Acceptor 接受。这跟P1有点矛盾啦,我们可以使用一个全局的编号来标识每一个Acceptor批准的提案,当一个具有某value值的提案被半数以上的Acceptor批准后,我们就认为该value被选定了。即提案P= 提案参数 + 提案值,可以记为【M,V】。
现在可以允许多个提案被选定,但必须保证所有被选定的提案都具有相同的value值。要不然又会出现不一致啦。因此可以再加个约束P2:
如果提案 P[M1,V1] 被选定了,那么所有比M1编号更高的被选定提案P,其 value 的值也必须是 V1。
复制代码一个提案要被选定,至少要被一个 Acceptor 接受,因此我们可以把P2约束改成对Acceptor接受的约束P2a:
如果提案 P[M1,V1] 被接受了,那么所有比M1编号更高的,且被Acceptor接受的P,其值也是 V1。
复制代码多提案被选择的问题解决了,但是如果是网络不稳定或者宕机的原因,还是会有问题。
假设有 5 个 Acceptor。Proposer2 提出 [M1,V1]的提案,Acceptor2
5(半数以上)均接受了该提案,于是对于 Acceptor25 和 Proposer2 来讲,它们都认为 V1 被选定。Acceptor1 刚刚从 宕机状态 恢复过来(之前 Acceptor1 没有收到过任何提案),此时 Proposer1 向 Acceptor1 发送了 [M2,V2] 的提案 (V2≠V1且M2>M1)。对于 Acceptor1 来讲,这是它收到的 第一个提案。根据 P1(一个 Acceptor 必须接受它收到的 第一个提案),Acceptor1 必须接受该提案。同时 Acceptor1 认为 V2 被选定。
这就出现了两个问题:
- Acceptor1 认为V2被选定,Acceptor2~5和Proposer2认为V1被选定。出现了不一致。
- V1被选定了,但是编号更高的被Acceptor1接受的提案[M2,V2]的 value 为 V2,且 V2≠V1。这就跟 P2a(如果提案 P[M1,V1] 被接受了,那么所有比M1编号更高的,且被Acceptor接受的P,其值也是 V1。)矛盾了。
我们要对P2a约束强化一下得到约束P2b,
如果 P[M1,V1] 被选定后,任何Proposer 产生的 P,其值也是 V1。
复制代码对于 P2b 中的描述,如何保证任何Proposer产生的P,其值也是V1 ?只要满足 P2c 即可:
对于任意的M和V,如果提案[M,V]被提出,那么肯定存在一个由半数以上的Acceptor组成的集合S,满足以下两个条件 中的任意一个:
要么S中每个Acceptor都没有接受过编号小于M的提案。 要么S中所有Acceptor批准的所有编号小于Mn的提案中,编号最大的那个提案的value值为Vn
8.3 算法流程
8.3.1. Proposer生成提案
- Prepare请求
- Accept请求
在 P2c约束基础上,如何生成提案呢?
Proposer选择一个新的提案编号N,向 Acceptor 集合 S(数目在半数以上)发送请求,要求 S 中的每一个 Acceptor 做出如下响应:
- 如果 Acceptor 没有接受过提案,则向 Proposer 保证 不再接受编号小于N的提案。
- 如果 Acceptor 接受过请求,则向 Proposer 返回 已经接受过的编号小于N的编号最大的提案。
我们将这个请求称为编号为N的Prepare请求。
- 如果Proposer收到半数以上的Acceptor 响应,则生成编号为N,value 为 V 的提案 [N,V],V 为所有响应中编号最大的提案的value。
- 如果 Proposer收到的响应中没有提案,那么 value 由 Proposer 自己生成,生成后将此提案发给 S,并期望Acceptor 能接受此提案。
我们称这个请求为Accept请求
8.3.2 Acceptor接受提案
一个Acceptor可能会受到来自Proposer的两种请求:Prepare请求和Accept请求。Acceptor 什么时候可以响应一个请求呢,它也有个约束:P1b:
一个Acceptor只要尚未响应过任何编号大于N的Prepare请求,那么他就可以接受这个编号为N的提案。
复制代码Acceptor收到编号为 N的Prepare 请求,如果在此之前它已经响应过编号大于N的Prepare请求。由约束P1b,该Acceptor不会接受这个编号为N的提案。因此,Acceptor会忽略这个请求。
一个 Acceptor 只需记住两点:已接受的编号最大的提案和已响应的请求的最大编号。
8.3.3 Paxos算法描述
阶段一:
- Proposer选择一个提案编号N,然后向半数以上的Acceptor发送编号为N的Prepare请求。
- 如果一个Acceptor收到一个编号为N的Prepare请求,且N大于该Acceptor已经响应过的所有Prepare请求的编 号,那么它就会将它已经接受过的编号最大的提案(如果有的话)作为响应反馈给Proposer,同时该Acceptor 承诺不再接受任何编号小于N的提案。
阶段二:
- 如果Proposer收到半数以上Acceptor对其发出的编号为N的Prepare请求的响应,那么它就会发送一个针对 [N,V]提案的Accept请求给半数以上的Acceptor。注意:V就是收到的响应中编号最大的提案的value,如果响应 中不包含任何提案,那么V就由Proposer自己决定。
- 如果Acceptor收到一个针对编号为N的提案的Accept请求,只要该Acceptor没有对编号大于N的Prepare请求 做出过响应,它就接受该提案。
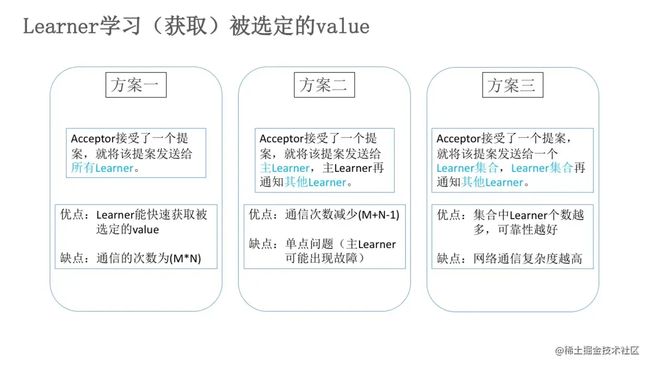
8.3.4 Learner学习被选定的value
9. B+树聊一下?B+树是不是有序?B+树和B-树的主要区别?B+树索引,一次查找过程?
B+树是有序的。
B+树和B-树的主要区别?
- B-树内部节点是保存数据的;而B+树内部节点是不保存数据的,只作索引作用,它的叶子节点才保存数据。
- B+树相邻的叶子节点之间是通过链表指针连起来的,B-树却不是。
- 查找过程中,B-树在找到具体的数值以后就结束,而B+树则需要通过索引找到叶子结点中的数据才结束
- B-树中任何一个关键字出现且只出现在一个结点中,而B+树可以出现多次。
假设有这么一个SQL:
select * from Temployee where age=32;
复制代码age加个一个索引,这条SQL是如何在索引上执行的?大家可以举例子画个示意图哈,比如二级索引树,
再画出id主键索引,我们先画出聚族索引结构图,如下:
因此,这条 SQL 查询语句执行大概流程就是酱紫:
- 搜索idx_age索引树,将磁盘块1加载到内存,由于32<37,搜索左路分支,到磁盘寻址磁盘块2。
- 将磁盘块2加载到内存中,在内存继续遍历,找到age=32的记录,取得id = 400.
- 拿到id=400后,回到id主键索引树。
- 搜索id主键索引树,将磁盘块1加载内存,在内存遍历,找到了400,但是B+树索引非叶子节点是不保存数据的。索引会继续搜索400的右分支,到磁盘寻址磁盘块3.
- 将磁盘块3加载内存,在内存遍历,找到id=400的记录,拿到R4这一行的数据,好的,大功告成。
10. TCP 怎么实现拥塞控制?
拥塞控制是作用于网络的,防止过多的数据包注入到网络中,避免出现网络负载过大的情况。它的目标主要是最大化利用网络上瓶颈链路的带宽。
实际上,拥塞控制主要有这几种常用算法
- 慢启动
- 拥塞避免
- 拥塞发生
- 快速恢复
慢启动算法
慢启动算法,表面意思就是,别急慢慢来。它表示TCP建立连接完成后,一开始不要发送大量的数据,而是先探测一下网络的拥塞程度。由小到大逐渐增加拥塞窗口的大小,如果没有出现丢包,每收到一个ACK,就将拥塞窗口cwnd大小就加1(单位是MSS)。每轮次发送窗口增加一倍,呈指数增长,如果出现丢包,拥塞窗口就减半,进入拥塞避免阶段。
- TCP连接完成,初始化cwnd = 1,表明可以传一个MSS单位大小的数据。
- 每当收到一个ACK,cwnd就加一;
- 每当过了一个RTT,cwnd就增加一倍; 呈指数让升
为了防止cwnd增长过大引起网络拥塞,还需设置一个慢启动阀值ssthresh(slow start threshold)状态变量。当cwnd到达该阀值后,就好像水管被关小了水龙头一样,减少拥塞状态。即当cwnd >ssthresh时,进入了拥塞避免算法。
拥塞避免算法
一般来说,慢启动阀值ssthresh是65535字节,cwnd到达慢启动阀值后
- 每收到一个ACK时,cwnd = cwnd + 1/cwnd
- 当每过一个RTT时,cwnd = cwnd + 1
显然这是一个线性上升的算法,避免过快导致网络拥塞问题。
拥塞发生
当网络拥塞发生丢包时,会有两种情况:
- RTO超时重传
- 快速重传
如果是发生了RTO超时重传,就会使用拥塞发生算法
- 慢启动阀值sshthresh = cwnd /2
- cwnd 重置为 1
- 进入新的慢启动过程
这真的是辛辛苦苦几十年,一朝回到解放前。其实还有更好的处理方式,就是快速重传。发送方收到3个连续重复的ACK时,就会快速地重传,不必等待RTO超时再重传。
慢启动阀值ssthresh 和 cwnd 变化如下:
- 拥塞窗口大小 cwnd = cwnd/2
- 慢启动阀值 ssthresh = cwnd
- 进入快速恢复算法
快速恢复
快速重传和快速恢复算法一般同时使用。快速恢复算法认为,还有3个重复ACK收到,说明网络也没那么糟糕,所以没有必要像RTO超时那么强烈。
正如前面所说,进入快速恢复之前,cwnd 和 sshthresh已被更新:
- cwnd = cwnd /2
- sshthresh = cwnd
复制代码然后,真正的快速算法如下:
- cwnd = sshthresh + 3
- 重传重复的那几个ACK(即丢失的那几个数据包)
- 如果再收到重复的 ACK,那么 cwnd = cwnd +1
- 如果收到新数据的 ACK 后, cwnd = sshthresh。因为收到新数据的 ACK,表明恢复过程已经结束,可以再次进入了拥塞避免的算法了。
11. JVM调优
11.1 一般什么时候考虑JVM调优呢?
- Heap内存(老年代)持续上涨达到设置的最大内存值;
- Full GC 次数频繁;
- GC 停顿时间过长(超过1秒);
- 应用出现OutOfMemory 等内存异常;
- 应用中有使用本地缓存且占用大量内存空间;
- 系统吞吐量与响应性能不高或下降。
11.2 JVM调优的目标
- 延迟:GC低停顿和GC低频率;
- 低内存占用;
- 高吞吐量;
11.3 JVM调优量化目标
- Heap 内存使用率 <= 70%;
- Old generation内存使用率<= 70%;
- avgpause <= 1秒;
- Full gc 次数0 或 avg pause interval >= 24小时 ;
11.4 JVM调优的步骤
- 分析GC日志及dump文件,判断是否需要优化,确定瓶颈问题点;
- 确定JVM调优量化目标;
- 确定JVM调优参数(根据历史JVM参数来调整);
- 依次调优内存、延迟、吞吐量等指标;
- 对比观察调优前后的差异;
- 不断的分析和调整,直到找到合适的JVM参数配置;
- 找到最合适的参数,将这些参数应用到所有服务器,并进行后续跟踪。
11.5 常见的JVM参数
堆栈配置相关
-Xmx3550m -Xms3550m -Xmn2g -Xss128k
-XX:MaxPermSize=16m -XX:NewRatio=4 -XX:SurvivorRatio=4 -XX:MaxTenuringThreshold=0
复制代码- -Xmx3550m: 最大堆大小为3550m。
- -Xms3550m: 设置初始堆大小为3550m。
- -Xmn2g: 设置年轻代大小为2g。
- -Xss128k: 每个线程的堆栈大小为128k。
- -XX:MaxPermSize: 设置持久代大小为16m
- -XX:NewRatio=4: 设置年轻代(包括Eden和两个Survivor区)与年老代的比值(除去持久代)。
- -XX:SurvivorRatio=4: 设置年轻代中Eden区与Survivor区的大小比值。设置为4,则两个Survivor区与一个Eden区的比值为2:4,一个Survivor区占整个年轻代的1/6
- -XX:MaxTenuringThreshold=0: 设置垃圾最大年龄。如果设置为0的话,则年轻代对象不经过Survivor区,直接进入年老代。
垃圾收集器相关
-XX:+UseParallelGC
-XX:ParallelGCThreads=20
-XX:+UseConcMarkSweepGC
-XX:CMSFullGCsBeforeCompaction=5
-XX:+UseCMSCompactAtFullCollection:
-XX:+UseConcMarkSweepGC
复制代码- -XX:+UseParallelGC: 选择垃圾收集器为并行收集器。
- -XX:ParallelGCThreads=20: 配置并行收集器的线程数
- -XX:+UseConcMarkSweepGC: 设置年老代为并发收集。
- -XX:CMSFullGCsBeforeCompaction:由于并发收集器不对内存空间进行压缩、整理,所以运行一段时间以后会产生“碎片”,使得运行效率降低。此值设置运行多少次GC以后对内存空间进行压缩、整理。
- -XX:+UseCMSCompactAtFullCollection: 打开对年老代的压缩。可能会影响性能,但是可以消除碎片
- -XX:+UseConcMarkSweepGC 使用CMS垃圾收集器
辅助信息
-XX:+PrintGC
-XX:+PrintGCDetails
复制代码11.6 常用调优策略
- 选择合适的垃圾回收器
- 调整内存大小(垃圾收集频率非常频繁,如果是内存太小,可适当调整内存大小)
- 调整内存区域大小比率(某一个区域的GC频繁,其他都正常。)
- 调整对象升老年代的年龄(老年代频繁GC,每次回收的对象很多。)
- 调整大对象的标准(老年代频繁GC,每次回收的对象很多,而且单个对象的体积都比较大。)
- 调整GC的触发时机(CMS,G1 经常 Full GC,程序卡顿严重。)
- 调整 JVM本地内存大小(GC的次数、时间和回收的对象都正常,堆内存空间充足,但是报OOM)
12. 数据库分库分表的缺点是啥?
- 事务问题,已经不可以用本地事务了,需要用分布式事务。
- 跨节点Join的问题:解决这一问题可以分两次查询实现
- 跨节点的count,order by,group by以及聚合函数问题:分别在各个节点上得到结果后在应用程序端进行合并。
- ID问题:数据库被切分后,不能再依赖数据库自身的主键生成机制啦,最简单可以考虑UUID
- 跨分片的排序分页问题(后台加大pagesize处理?)
13. 分布式事务如何解决?TCC 了解?
分布式事务:
就是指事务的参与者、支持事务的服务器、资源服务器以及事务管理器分别位于不同的分布式系统的不同节点之上。简单来说,分布式事务指的就是分布式系统中的事务,它的存在就是为了保证不同数据库节点的数据一致性。
聊到分布式事务,需要知道这两个基本理论哈。
- CAP 理论
- BASE 理论
CAP 理论
- 一致性(C:Consistency):一致性是指数据在多个副本之间能否保持一致的特性。例如一个数据在某个分区节点更新之后,在其他分区节点读出来的数据也是更新之后的数据。
- 可用性(A:Availability):可用性是指系统提供的服务必须一直处于可用的状态,对于用户的每一个操作请求总是能够在有限的时间内返回结果。这里的重点是"有限时间内"和"返回结果"。
- 分区容错性(P:Partition tolerance):分布式系统在遇到任何网络分区故障的时候,仍然需要能够保证对外提供满足一致性和可用性的服务。
BASE 理论
它是对CAP中AP的一个扩展,对于我们的业务系统,我们考虑牺牲一致性来换取系统的可用性和分区容错性。BASE是Basically Available,Soft state,和 Eventually consistent三个短语的缩写。
- Basically Available(基本可用):通过支持局部故障而不是系统全局故障来实现的。如将用户分区在 5 个数据库服务器上,一个用户数据库的故障只影响这台特定主机那 20% 的用户,其他用户不受影响。
- Soft State(软状态):状态可以有一段时间不同步
- Eventually Consistent(最终一致):最终数据是一致的就可以了,而不是时时保持强一致。
分布式事务的几种解决方案:
- 2PC(二阶段提交)方案、3PC
- TCC(Try、Confirm、Cancel)
- 本地消息表
- 最大努力通知
- seata事务
TCC(补偿机制)
TCC 采用了补偿机制,其核心思想是:针对每个操作,都要注册一个与其对应的确认和补偿(撤销)操作。TCC(Try-Confirm-Cancel)包括三段流程:
- try阶段:尝试去执行,完成所有业务的一致性检查,预留必须的业务资源。
- Confirm阶段:该阶段对业务进行确认提交,不做任何检查,因为try阶段已经检查过了,默认Confirm阶段是不会出错的。
- Cancel 阶段:若业务执行失败,则进入该阶段,它会释放try阶段占用的所有业务资源,并回滚Confirm阶段执行的所有操作。
下面再拿用户下单购买礼物作为例子来模拟TCC实现分布式事务的过程:
假设用户A余额为100金币,拥有的礼物为5朵。A花了10个金币,下订单,购买10朵玫瑰。余额、订单、礼物都在不同数据库。
TCC的Try阶段:
- 生成一条订单记录,订单状态为待确认。
- 将用户A的账户金币中余额更新为90,冻结金币为10(预留业务资源)
- 将用户的礼物数量为5,预增加数量为10。
- Try成功之后,便进入Confirm阶段
- Try过程发生任何异常,均进入Cancel阶段
TCC的Confirm阶段:
- 订单状态更新为已支付
- 更新用户余额为90,可冻结为0
- 用户礼物数量更新为15,预增加为0
- Confirm过程发生任何异常,均进入Cancel阶段
- Confirm过程执行成功,则该事务结束
TCC的Cancel阶段:
- 修改订单状态为已取消
- 更新用户余额回100
- 更新用户礼物数量为5
- TCC的优点是可以自定义数据库操作的粒度,降低了锁冲突,可以提升性能
- TCC的缺点是应用侵入性强,需要根据网络、系统故障等不同失败原因实现不同的回滚策略,实现难度大,一般借助TCC开源框架,ByteTCC,TCC-transaction,Himly。
大家有兴趣可以看下我之前这篇文章哈:
后端程序员必备:分布式事务基础篇
14, RocketMQ 如何保证消息的准确性和安全性?
我个人理解的话,这道题换汤不换药,就是为如何保证RocketMQ 不丢消息,保证不重复消费,消息有序性,消息堆积的处理。
消息不丢失的话,即从生产者、存储端、消费端去考虑
大家可以看下我之前这篇文章哈:
消息队列经典十连问
15. 三个数求和
给你一个包含 n 个整数的数组 nums,判断 nums 中是否存在三个元素 a,b,c ,使得 a + b + c = 0 ?请你找出所有和为 0 且不重复的三元组。
注意:答案中不可以包含重复的三元组
实例1:
输入:nums = [-1,0,1,2,-1,-4]
输出:[[-1,-1,2],[-1,0,1]]
复制代码实例2:
输入:nums = [0]
输出:[]
复制代码思路:
这道题可以先给数组排序,接着用左右双指针。
完整代码如下:
class Solution {
public List> threeSum(int[] nums) {
List> result = new LinkedList<>();
if(nums==null||nums.length<3){ //为空或者元素个数小于3,直接返回
return result;
}
Arrays.sort(nums); //排序
for(int i=0;i0){ //大于0可以直接跳出循环了
break;
}
if(i>0&&nums[i]==nums[i-1]){ //过滤重复
continue;
}
int left = i+1; //左指针
int right = nums.length-1; //右指针
int target = - nums[i]; //目标总和,是第i个的取反,也就是a+b+c=0,则b+c=-a即可
while(left 参考与感谢
- Callable/Future 使用及原理分析
- 【JVM进阶之路】十:JVM调优总结
- 分布式理论(五) - 一致性算法Paxos
- 这一定是全网讲的最好的Paxos一致性算法
作者:捡田螺的小男孩
链接:https://juejin.cn/post/7075132492168036388
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。