轻量级图像分类模型-MobileNetV3阅读笔记
文章目录
- 前言
- 摘要(Abstract)
- 1. 介绍(Introduction)
- 2. 相关工作(Related Work)
- 3. 高效的移动构造模块(Efficient Mobile Building Blocks)
- 4. 网络搜索(Network Search)
-
- 4.1 针对基于块的搜索的平台NAS(Platform-Aware NAS for Block-wise Search)
- 4.2 基于层搜索的NetAdapt(NetAdapt for Layer-wise Search)
- 5.网络提升(Network Improvements)
- 5.1 重新设计计算昂贵层(Redesigning Expensive Layers)
-
- 5.2 非线性(Nonlinearities)
- 5.3 大型SE(Large squeeze-and-excite)
- 5.4 MoibleNetV3定义(MobileNetV3 Definitions)
- 6. 实验(Expermients)
-
- 6.1 分类(Classification)
-
- 6.1.1 训练计划(Training setup)
- 6.1.2 度量计划(Measurement setup)
- 6.2 结果(Results)
-
- 6.2.1 消融研究(Ablation Study)
- 6.3 检测(Detection)
- 6.4 语义分割(Sematic Segmentation)
- 总结
前言
今天开始阅读MobileNetV3这一轻量级图像分类网络模型论文,这是最初开始阅读MobileNet系列论文的目的,项目中就是用到MibleNetV3来进行图像分类,但是不清楚模型架构,感觉不爽。
论文标题:Searching for MobileNetV3
摘要(Abstract)
论文提出新一代的MobileNetV3网络模型,它结合了硬件和以NetAdapt算法实现的网络架构搜索技术(network architecture search, NAS),提升了算法性能。论文提出两种网络模型:MobileNetV3-Large 和MobileNetV3-Small分别对应高和低的资源需求,可以将这两个模型应用于目标检测和语义分割任务。关于语义分割任务(或者任意密集像素预测),论文提出一种新的有效的分割解码器LR-ASPP(Lite Reduced Atrous Spatial Pyramid Pooling)。论文在移动端分类, 检测和分割任务实现最优(state-of-the art)。MobileNetV3-Large模型,在ImageNet分类中准确性提高了3.2%,与MobileNetV2相比速度提升了20%。MobileNetV3-Small模型与MobileNetV2相比,在可比的延迟下精度提高了6.6%。MobileNetV3-Large模型在COCO数据集中与MobileNetV2相比在大致相同的准确率下检测速度超过25%。在Cityscapes分割数据集中, 在准确率相同的条件下,MobileNetV3-Large LR-ASPP模型的速度比MobileNetV2 R-ASPP快34%。
1. 介绍(Introduction)
这篇论文的目标是开发最优的计算机视觉架构能够在移动设备上优化准确率与延迟的权衡效果。为了实现这个目标,论文介绍了:
(1)网络模型搜索技术;
(2)对于移动配置来说,新的高效版本的非线性实践;
(3)新的高效网络设计
(4)新的高效分割解码器
论文提出了详尽的实验在广泛的用例和移动电话上证实高效性并评估了每种技术的价值。
论文的组织结构如下:
第二章讨论了相关工作。
第三章复习了在移动模型上应用的高效建造模块。
第四章复习了架构搜索和MnasNet,NetAdapt算法的互补性。
第五章描述了论文提出的新颖的架构设计,它提升了模型的效率,这个模型是通过连接点搜索发现的。
第六章为了证实有效性和理解不同元素的贡献,论文对分类、检测、分割进行了实验。
第七章对论文进行总结。
2. 相关工作(Related Work)
为准确率和高效性间权衡的优化而进行的深度神经网络架构设计在近年来称为一个热点研究领域。在网络架构设计中,手工设计和用算法进行神经架构搜索这两种方法扮演了重要角色。
SqueezeNet大量使用了 1 × 1 1\times 1 1×1卷积,因为在挤压(squeeze)和扩展(expand)模块主要用于减少参数数量。最近的工作重点从减少参数数量到减少操作量(MAdds)和延迟上。MobilenetV1使用深度可分离卷积来提高计算效率。MobileNetV2在对V1版本进行扩展,因为一个带反向残差和线性瓶颈的资源-高效模块。Shufflenet使用了分组卷积和打乱通道操作来减少MAdds。CondenseNet在训练阶段为了特征重用,学习分组卷积来保持层间的有用的密集连接。ShiftNet提出了偏移操作(shift), 交错使用基于点的卷积来替代操作昂贵的空间卷积。
为了自动化架构设计流程,使用增强学习(Reinforcement learning, RL)来进行高效架构搜索,因为它的准确率比较好。因为架构搜索空间比较大(指数级),之前的架构搜索工作主要集中于cell级别,所有层都使用相同的cell。最近,探索了一种block级别的分层搜索,它允许在网络不同分辨率的block上有不同层结构。为减少搜索资源的消耗,差分架构搜索矿建使用了基于梯度的优化。在资源首先的移动平台使用已有的网络,一些论文提出了更高效的网络简化算法。
量化(Quantization)是另外一种比较重要的可以提高网络效率的技巧。最后,知识蒸馏提供了一种额外的补充方法:它通过大型“教师”网络的指导来生成小型准确的“学生”网络。
3. 高效的移动构造模块(Efficient Mobile Building Blocks)
移动模型的构造是基于高效的构造模块。MoibleNetV1引入了基于深度可分离的卷积来替换传统的卷积层。深度可分离卷积有效地将传统卷积分解,即将空间过滤功能从特征生成机制中分割出来。深度可分离卷积被定义为两层:关于空间过滤的轻量级深度卷积以及关于特征生成的重量级 1 × 1 1\times 1 1×1点卷积。

MobileNetV2为制作更高效的层结构引入了线性瓶颈和反向残差结构。Figure.3展示了这一结构
,它由一个 1 × 1 1\times 1 1×1的扩展卷积,然后紧跟着一个基于深度的卷积和一个 1 × 1 1\times 1 1×1投影层(线性层)组成。输入与输出通过一个残差连接进行连接,前提条件是当且仅当输入与输出层通道数相同。这个结构在输入与输出上维持了一个紧凑的表示,然而扩展到更高维度的特征空间时,这本质上通过每一通道变换增加了非线性表示能力。

MnasNet在MobileNetV2结构基础上将基于SE(squeeze and excitation)的轻量级注意力模块引入瓶颈结构中。注意,SE模块被集成于不同位置,这个模块被放在基于深度的过滤器后面,同时在该模块后引入注意力机制,如在Figure.4中所示。
对于MobileNetV3, 为了构造最有效的模型,论文将这些层组合成构造块。这些层使用了被修改的 s w i s h swish swish非线性来升级。SE模块和 s w i s h swish swish非线性都使用了 s i g m o i d sigmoid sigmoid, s i g m o i d sigmoid sigmoid既计算量大又是对保持固定点计算的准确性很有挑战,因此论文使用 h a r d s i g m o i d hard\ sigmoid hard sigmoid来替代它,具体细节将在5.2节讨论。
4. 网络搜索(Network Search)
已经证实了网络搜索对于发现和优化网络架构是一个非常强大的工具。对于MobileNetV3,论文使用了NAS来通过优化每一网络模块来搜索全局网络结构,然后使用NetAdapt算法搜索每一层的过滤器数量。这些技术是互补的并可以通过组合方式为一个给定的硬件平台找到一个优化模型。
4.1 针对基于块的搜索的平台NAS(Platform-Aware NAS for Block-wise Search)
论文使用了基于平台的神经架构方法来查找一个全局网络结构。因为论文使用了和基于RNN相同的控制器,和分解层次搜索空间相同的方法,关于Large移动模型得到亮丝的结果 - 目标延迟大约80ms。因此,论文简单使用了MnasNet-A1作为Large移动网络模型的初始模型,然后在它基础上使用了NetAdapt算法和其它优化方法。
然而,论文发现初始的设计没有对Small移动模型进行优。论文使用了多目标激励 A C C ( m ) × [ L A T ( m ) / T A R ] w ACC(m)\times [LAT(m)/TAR]^{w} ACC(m)×[LAT(m)/TAR]w来近似Pareto优化方案,它基于目标延迟 T A R TAR TAR对每一个模型 m m m平衡模型精度 A C C ( m ) ACC(m) ACC(m)和延迟 L A T ( m ) LAT(m) LAT(m)。
论文发现对于小型模型,伴随延迟,准确性变化更加剧烈。因此,论文需要一个更小的权重因子 w = − 0.15 w=-0.15 w=−0.15 (和原始的 w = − 0.07 w=-0.07 w=−0.07对比)来对不同的延迟造成的准确率改变做出补偿。因为这个新的权重因子 w w w的改变,论文从头开始一个新的架构搜索来查找一个初始的种子模型,然后使用 N e t A d a p t NetAdapt NetAdapt和其它优化方法得到最终的MobileNetV3-Small模型。
4.2 基于层搜索的NetAdapt(NetAdapt for Layer-wise Search)
论文用于架构搜索中的第二个技术是 N e t A d a p t NetAdapt NetAdapt,这个方法是和基于平台的 N A S NAS NAS互补的:它允许以序列方式对独立层进行微调,而不是尝试推理粗糙但是全局的架构。论文参考了原始论文的整个细节,这一技术的处理流程简述如下:
-
通过基于平台的 N A S NAS NAS技术来查找一个种子网络架构。
-
对于每一步:
(a)生成一个新方法的集合。每一个方法表示一个架构的修改:和之前的步骤相比,在延迟方面生成至少减少 δ \delta δ
(b)对新方法集合中的每一方法,论文使用之前的步骤生成的模型作为预训练模型,并填充这一新的架构,裁剪和随机初始化这些丢失的权重。微调每一方法 T T T步,获得一个粗糙的准确率评估。
(c)依据一些准则选择最好的方法。 -
遍历上述步骤直到达到目标延迟。
论文使用的准则:最小化延迟改变与准确率改变的比率。对于每一 N e t A d a p t NetAdapt NetAdapt步骤生成的所有方法,论文挑选一个使公式最大化:
这里, △ l a t e n c y \triangle latency △latency满足2(a)限制。因为论文提出的方法是离散的,所以论文更偏爱最大化的曲线斜率。
这一过程被重复执行直到达到目标延迟,然后丛台开始重新训练洗的架构。论文使用和MobileNetV2宏相同的生成器,论文尤其沿用了下面两种类型的方法:
- 减少任一扩展层的大小;
- 减少所有模块里的瓶颈,为维护残差连接需要所有模块共享相同的瓶颈大小。
论文实验中使用 T = 10000 T=10000 T=10000并发现虽然它能够增加初始微调的准确率,然而,当从头开始训练时它却不能改变最终的准确率。论文设置 δ = 0.01 ∣ L ∣ \delta = 0.01|L| δ=0.01∣L∣,这里 L L L是种子模型的延迟。
5.网络提升(Network Improvements)
除了网络搜索外,论文也引入几个新的组件到模型中来提升最终的模型。论文重新设计了在网络开始和结束部分计算昂贵的层。论文也引入一个新的非线性激活函数: h − s w i s h h-swish h−swish,它是最近非线性激活函数 s w i s h swish swish改进版,这样能够加速计算并让量化更友好。
5.1 重新设计计算昂贵层(Redesigning Expensive Layers)
一旦通过架构搜索(architecture search)发现模型,论文发现最后几层和开始几层比其它部分计算代价更高。论文对架构提出几点改动来减少这些速度慢的层的延迟但是维护准确率。这些修改超出了目前搜索空间的范围。
第一个改动为了更有效的生成最后的特征论文修正了网络最后几层的交互。当前模型是基于MobileNetV2的反向瓶颈结构的,为了扩展到一个更高维的特征空间,变量使用了 1 × 1 1\times 1 1×1卷积作为一个最终层。为预测需要的丰富特征,这一层是非常重要的,然而,这却带来额外的延迟消耗。
为减少延迟并保存高维特征,论文将这层移到最后平均池化层的后面。这个最后的特征集合由 1 × 1 1\times 1 1×1空间分辨率计算来替代 7 × 7 7\times 7 7×7的空间分辨率。这种设计选择的结果就计算量和延迟而言,几乎没有什么特征计算量。

一旦特征生成层的计算量减轻,其实就不需要之前瓶颈投影层,这一层是用于减少计算量的。这个发现给论文移除投影和过滤层提供了依据,进一步减少计算复杂性。Figure.5展示了原始和优化后的最后阶段。优化后的最后阶段减少了7毫秒的延迟,即减少了 11 % 11\% 11%的运行时间,减少了30 millions MAdds操作量,同时几乎没有带来准确率的下降。章节6包含了详细结果。
另一个计算昂贵的层是过滤器集合的初始化。目前移动模型趋向于使用 3 × 3 3\times 3 3×3卷积、 32个过滤器来为边缘检测构建初始过滤器集。通常,这些过滤器互为镜像图像。论文通过减少过滤器数量和使用不同非线性激活这类方法进行实验来尝试和减少冗余。和其它非线性激活函数相比,论文发现使用 h a r d s w i s h hard swish hardswish非线性激活函数表现不错。论文能够减少过滤器数量到 16 16 16同时和使用 32 32 32个过滤器保持相同的准确率,论文也使用了 R e L U ReLU ReLU或者 s w i s h swish swish。这节省了额外2毫秒和10 millon MAdds。
5.2 非线性(Nonlinearities)
论文引入非线性激活函数 s w i s h swish swish来替代 R e L U ReLU ReLU,这对于提升神经网络准确率意义重大。非线性函数定义如下:

这个非线性函数在提升准确率的同时,在嵌入式环境中伴随着non-zero损失,因为 s i g m o i d sigmoid sigmoid激活函数在移动设备上需要更多的计算资源。论文用两种方法来处理这个问题:
- 使用如下分段线性函数来替代 s i g m o i d sigmoid sigmoid函数:
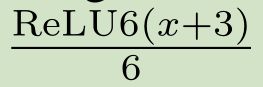
这里较小差异是论文使用 R e L U 6 ReLU6 ReLU6而不是一个定制裁剪常量。hard版本的 s w i s h swish swish定义如下:

Figure.6展示了非线性函数 s i g m o i d sigmoid sigmoid和 s w i s h swish swish,soft和hard版本对比。

在实验中发现,这些函数的hard版本在准确率方面没有明显差异,但是从部署角度来说有多个优势。首先,优化实现的 R e L U 6 ReLU6 ReLU6在所有软硬件框架中都是可用的。第二,在量化模式方面,通过近似 s i g m o i d sigmoid sigmoid不同实现,它减少了潜在的数字精度损失。最终,受大幅降低延迟消耗驱动, h − s w i s h h-swish h−swish可用一个分段函数来实现进而减少内存访问次数。

2. 在网络的更深层,使用非线性激活减少了消耗,因为每次分辨率下降,每层激活内存都会减半。顺便说下,论文发现 s w i s h swish swish的大部分好处在于在更深层使用它们。因此在论文架构中,论文仅在模型的后半部分使用 h − s w i s h h-swish h−swish,具体分布可以参考Table.1和Table.2。
即使有这些优化, h − s w i s h h-swish h−swish仍然引入一些延迟消耗。然而在章节6证实了:当使用基于分段函数这一优化实现时,在准确率和延迟方面使用无优化网络的影响也是积极的。
5.3 大型SE(Large squeeze-and-excite)
SE瓶颈层的大小是和卷积瓶颈层的大小相关的。论文替换扩展层中SE瓶颈通道数到原来的 1 / 4 1/4 1/4。论文发现,这样做增加了准确率,虽然增加了参数量,但没有带来明显的延迟消耗。
5.4 MoibleNetV3定义(MobileNetV3 Definitions)
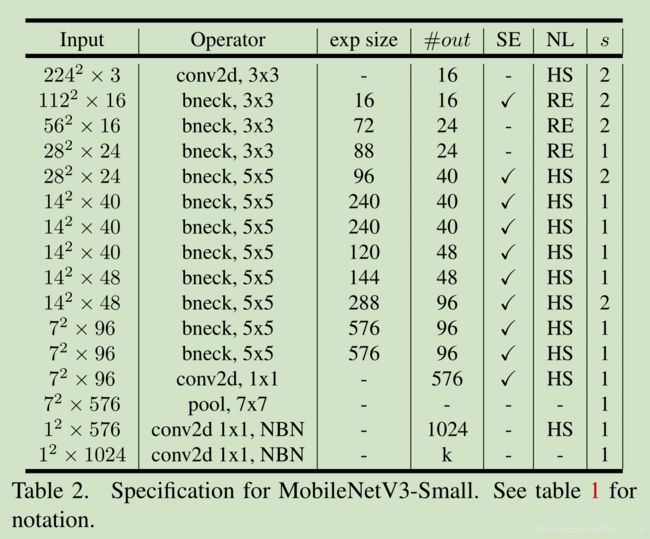
MobileNetV3定义有两个模型:MoibleNetV3-Large和MoibleNetV3-Samll。这两个模型分别针对高、低资源用例。这两个模型使用了基于平台的NAS和NetAdapt来进行网络搜索并使用了这章使用的网络提升方法。Table.1和Table.2是这两个模型的完整说明。
6. 实验(Expermients)
论文呈现的实验结果证实了MobileNetV3模型的有效性。论文报告了分类、检测和分割的结果。论文也报告了各种消融研究来阐明各种设计决策的影响。
6.1 分类(Classification)
论文对所有的分类实验都使用了ImageNet数据集,通过各种资源使用的测量来比较准确率,比如MAdds。
6.1.1 训练计划(Training setup)
论文在 4 × 4 4\times 4 4×4 TPU Pod上使用同步训练启动来训练模型,它使用标准tensorflow RMSPropOptimizer伴随动量值 0.9 0.9 0.9。论文使用初始学习率为 0.1 0.1 0.1, 批处理大小为 4096 4096 4096(每个晶片有128张图片),学习率衰减为每3个epochs下降0.01。论文使用丢弃率为0.8,L2权重衰减1e-5,使用和Inception网络相同的图像预处理。最终论文使用衰减率为0.9999的指数移动平均。所有卷积层使用带平均衰减为0.99的BN层。
6.1.2 度量计划(Measurement setup)
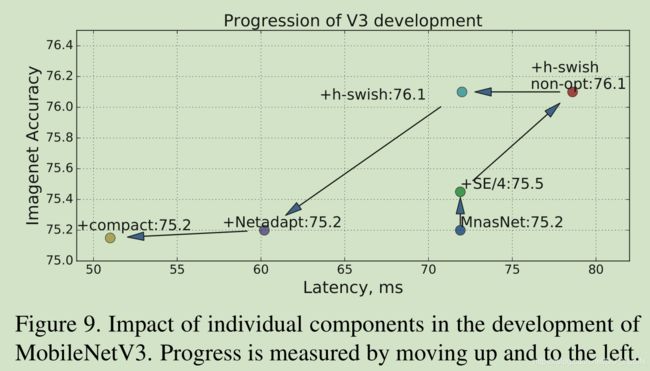
为了度量延迟,论文使用了标准的Google Pixel电话,通过标准的TFLite Benchmark Tool来运行所有网络。在度量中论文使用了单线程大核心。论文没有报告多核心推理时间,但是论文发现这个计划对于移动应用不是很实用。论文主要在tensorflow lite上使用元 h − s w i s h h-swish h−swish操作,在Figure.9中展示了优化的 h − s w i s h h-swish h−swish影响。
6.2 结果(Results)

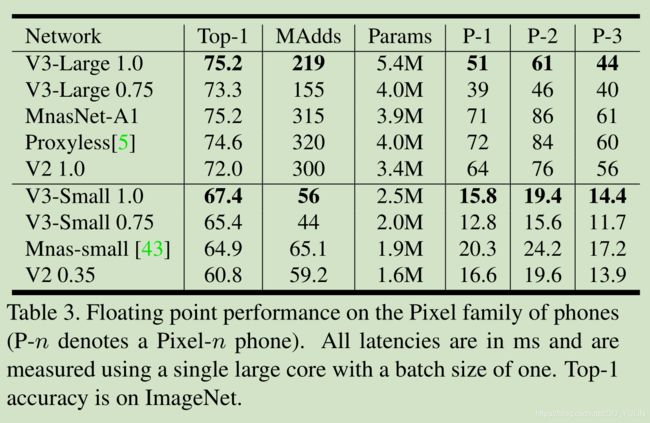
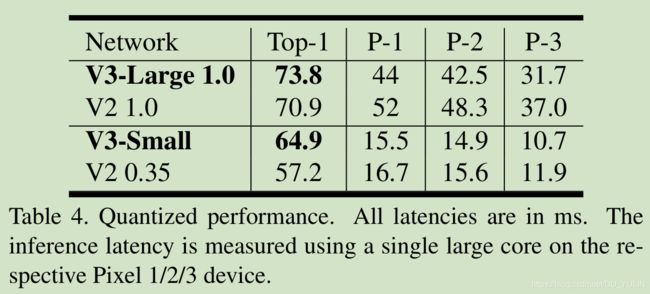
Figure.1 展示了论文提出的模型超过了目前最优模型,比如MnasNet, ProxylessNas和MoibleNetV2。论文报告了在不同Pixel电话上浮点计算性能,如Table.3所示。在Table.4介绍了量化结果。

Figure.7展示了MobileNetV3在乘法因子和分辨率函数方面性能的权衡。为匹配性能需求,和MoibleNetV3-Large相比,MobileNetV3-Small模型乘法器被缩小了大约 3 % 3\% 3%。另一方面,和乘法器相比,分辨率提供了更好地折中。然而,分辨率由具体问题确定,例如:分割和检测问题通常需要更高的分辨率,因此不能作为一个可调参数。
6.2.1 消融研究(Ablation Study)
非线性影响

从Table.5可以看出,使用 h − s w i s h h-swish h−swish的一个优化实现可以节省6ms时间,即超过 10 % 10\% 10%的运行时间。和传统的 R e L U ReLU ReLU相比,优化的 h − s w i s h h-swish h−swish方法仅额外增加了1ms。

Figure.8展示了基于非线性选择和网络宽度的有效结果。MoibleNetV3在网络中部使用了 h − s w i s h h-swish h−swish,并且很明显比 R e L U ReLU ReLU要多。有趣的是,将 h − s w i s h h-swish h−swish添加到整个网络比拓宽网络的内插边界更好一点。

其它组件的影响
Figure.9展示了不同组件对延迟和准确率的影响。
6.3 检测(Detection)

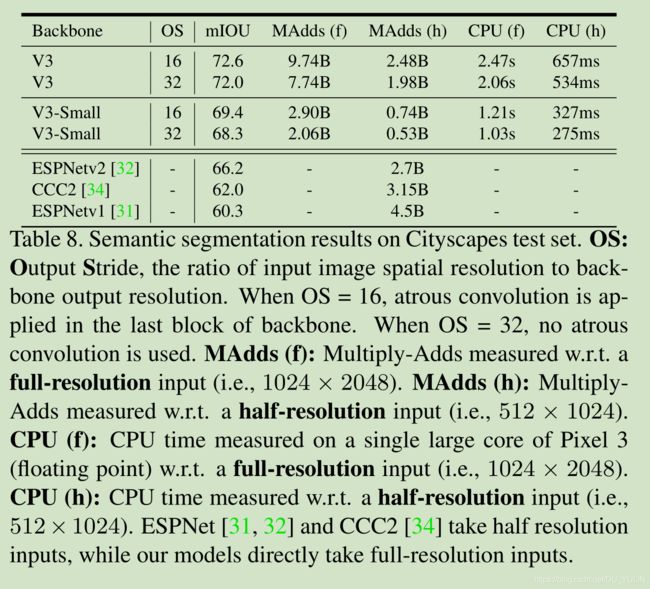
6.4 语义分割(Sematic Segmentation)
这两部分这里就不细说了,大家感兴趣可以自行阅读原论文。这里要着重提一下分割部分,论文在R-ASPP模型的基础上提出了LR-ASPP分割头部,性能更好。


总结
说实话,读完这篇论文,只是大概了解MobileNetV3有哪些改进,具体实现细节还是不太清楚,这一部分需要阅读开源代码才能知道,还有一个感受就是,这篇论文读起来很拗口,可能是个人英语能力的问题,可以说这是个人读作最费劲的论文之一。所以,如果大家在阅读过程中觉得有问题,欢迎指正,尤其一些英文单词真是不太清楚用中文如何更准确表达,谢谢大家。