时隔两年,盘点ECCV 2018影响力最大的20篇论文

上周CV君盘点了去年CVPR中引用量最高的 20 篇论文:
时隔一年,盘点CVPR 2019影响力最大的20篇论文
不少朋友催更ECCV 2018的。
同样是计算机视觉领域顶级会议,ECCV 每两年举办一次,今年的ECCV 2020 在八月末举行,本文盘点 ECCV 2018 影响力最大的20篇论文,毕竟两年过去了,足以看出论文的含金量,事实上直到如今这些工作还深刻影响着计算机视觉领域。
本文所指的影响力以谷歌学术上显示的论文的引用量排序,截止时间为2020年8月3日(今天)。
同前文,先说一些有意思的结论:
1. 这些论文均有开源代码,大部分算法有官方开源版本,少部分由他人实现,其中的著名算法如 DeepLabv3+、CBAM、Group normalization、ShuffleNet V2、BiseNet 都有很多开源实现。经过时间检验的算法,当然会有很多人复现。
2. 这20篇论文包含方向:语义分割(3篇)、注意力模型、网络归一化、神经架构搜索(2篇)、轻量级网络结构、图像翻译(GAN,2篇)、超分辨率、人员重识别(Person ReID)、目标检测、图像修复(Inpainting)、无监督学习、弱监督学习、姿态估计、目标跟踪、动作识别、三维重建。
3. DeepLabv3+ 引用数第一除了因为自身精度高长期霸榜、光芒万丈外,近两年语义分割方向太火肯定也是一个很大的因素,ECCV 2018 就有 3 篇语义分割文章入前20。
4. 排名靠前的算法除了引用数第一的 DeepLabv3+ 为特定方向的算法外(引用数 1941,将近是第 2、3、4位论文引用数总和),其他如CBAM注意力模型(引用数 780)、GN网络归一化方法(引用数 685)、神经架构搜索PNASNet(引用数 663)、轻量级网络结构Shufflenet v2(引用数 654)等研究的均为通用的网络设计、训练方法和组件。
5. CornerNet 算法排名第九,作为anchor-free类目标检测算法的代表作,勉强守住了前十。CVPR 2019 引用最高的20篇论文中出现两篇3D目标检测算法,很明显能看出3D目标检测越来越引起学界的兴趣。
6. 大部分论文有工业界的身影,比如谷歌 4 篇,Facebook 3篇,英伟达 2 篇,Adobe、Intel各 1 篇,国内企业界旷视 2 篇、商汤 2 篇、腾讯 2 篇、微软亚研院 1 篇。
大家还发现了哪些有意思的地方,欢迎在文末留言交流。
NO.1 语义分割 DeepLabv3+
Encoder-decoder with atrous separable convolution for semantic image segmentation
作者 | Liang-Chieh Chen, Yukun Zhu, George Papandreou, Florian Schroff, Hartwig Adam
单位 | 谷歌
论文 | https://arxiv.org/abs/1802.02611
解读 | https://zhuanlan.zhihu.com/p/126567709
代码 | https://github.com/tensorflow/models/
tree/master/research/deeplab
引用 | 1941



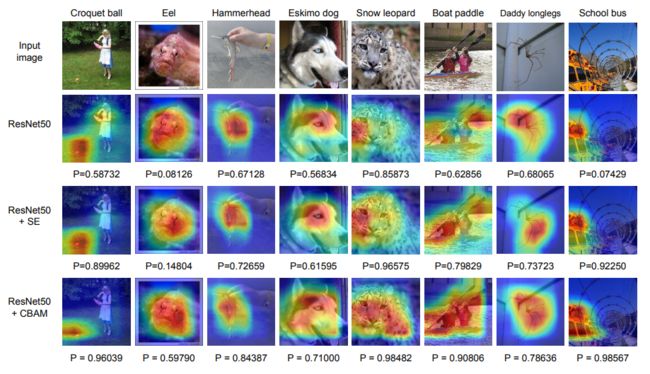
NO.2 注意力模型 CBAM
CBAM: Convolutional block attention module
通用提升CNN模型性能的卷积块注意力模型
作者 | Sanghyun Woo, Jongchan Park, Joon-Young Lee, In So Kweon
单位 | 韩国科学技术院;Lunit Inc;Adobe Research
论文 | https://arxiv.org/abs/1807.06521
代码 | https://github.com/Jongchan/attention-module
引用 | 780
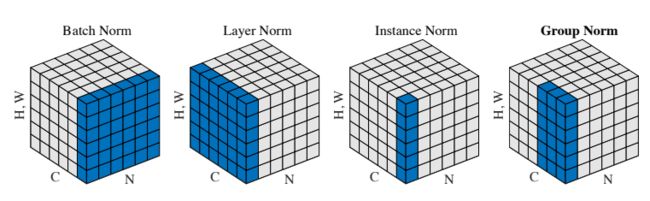
NO.3 归一化方法 GN
Group normalization
可代替BN的深度学习归一化方法
作者 | Yuxin Wu, Kaiming He
单位 | FAIR
论文 | https://arxiv.org/abs/1803.08494
解读 | 全面解读Group Normalization-(吴育昕-何恺明 )
https://zhuanlan.zhihu.com/p/35005794
代码 | https://github.com/facebookresearch/
Detectron/tree/master/projects/GN
引用 | 685
NO.4 神经架构搜索 PNASNet
提高了NAS 在ImageNet上的精度,大幅减少了训练时间
Progressive neural architecture search
作者 | Chenxi Liu, Barret Zoph, Maxim Neumann, Jonathon Shlens, Wei Hua, Li-Jia Li, Li Fei-Fei, Alan Yuille, Jonathan Huang, Kevin Murphy
单位 | 约翰斯霍普斯金大学;谷歌AI;斯坦福大学
论文 | https://arxiv.org/abs/1712.00559
解读 | PNASNet详解
https://zhuanlan.zhihu.com/p/52798148
代码 | https://github.com/tensorflow/models/tree/
master/research/slim#Pretrained
代码 | https://github.com/chenxi116/PNASNet
TF(TensorFlow)
代码 | https://github.com/chenxi116/PNASNet.
pytorch(PyTorch)
备注 | ECCV 2018 oral
引用 | 663

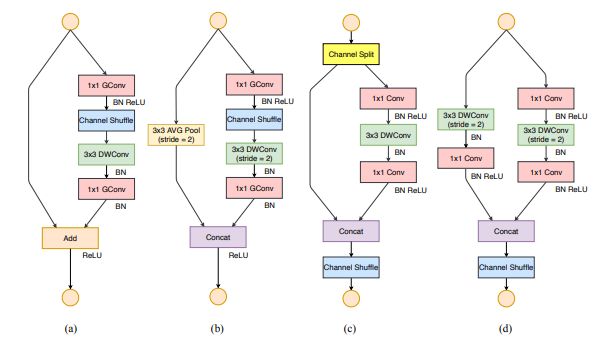
NO.5 轻量级网络结构 Shufflenet v2
Shufflenet v2: Practical guidelines for efficient cnn architecture design
新型轻量架构ShuffleNet V2:从理论复杂度到实用设计准则
作者 | Ningning Ma, Xiangyu Zhang, Hai-Tao Zheng, Jian Sun
单位 | 旷视;清华
论文 | https://arxiv.org/abs/1807.11164
代码 | https://github.com/megvii-model/ShuffleNet-Series
解读 | https://zhuanlan.zhihu.com/p/40824527
引用 | 654
NO.6 多模态无监督图像到图像翻译 MUNIT
Multimodal unsupervised image-to-image translation
多模态无监督的图像到图像翻译
作者 | Xun Huang, Ming-Yu Liu, Serge Belongie, Jan Kautz
单位 | 康奈尔大学;英伟达
论文 | https://arxiv.org/abs/1804.04732
解读 | https://zhuanlan.zhihu.com/p/97326646
代码 | https://github.com/nvlabs/MUNIT
引用 | 593
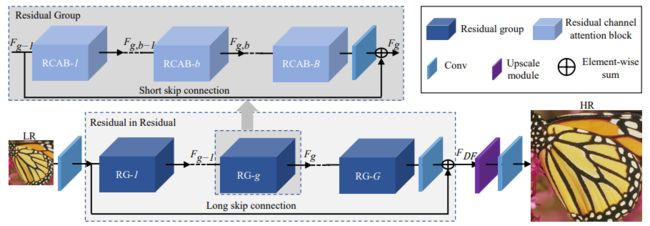
NO.7 超分辨率 残差通道注意力网络(RCAN)
Image super-resolution using very deep residual channel attention networks
作者 | Yulun Zhang, Kunpeng Li, Kai Li, Lichen Wang, Bineng Zhong, Yun Fu
单位 | (美国)东北大学;
论文 | https://arxiv.org/abs/1807.02758
代码 | https://github.com/yulunzhang/RCAN
引用 | 563
NO.8 人员重识别 PCB
Beyond part models: Person retrieval with refined part pooling (and a strong convolutional baseline)
作者 | Yifan Sun, Liang Zheng, Yi Yang, Qi Tian, Shengjin Wang
单位 | 清华大学;悉尼科技大学;
德克萨斯大学圣安东尼奥分校(圣安东尼奥)
论文 | https://arxiv.org/abs/1711.09349
代码 | https://github.com/huanghoujing/beyond-part-models
解读 | https://zhuanlan.zhihu.com/p/31947809
引用 | 526
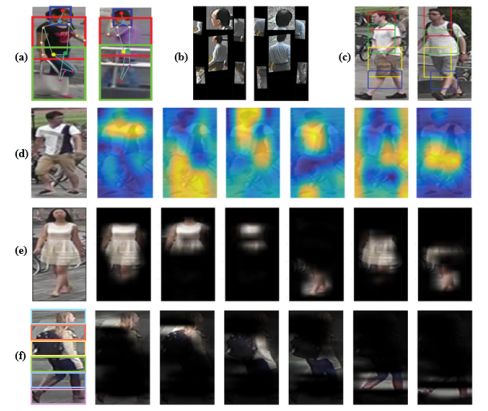
NO.9 目标检测 anchor-free方法
Cornernet: Detecting objects as paired keypoints
作者 | Hei Law, Jia Deng
单位 | 普林斯顿大学
论文 | https://arxiv.org/abs/1808.01244
解读 | ECCV18 Oral | CornerNet目标检测开启预测“边界框”到预测“点对”的新思路
代码 | https://github.com/umich-vl/CornerNet
引用 | 450

NO.10 图像修复 Partial Convolutions
基于部分卷积Pconv的图片修复
Image inpainting for irregular holes using partial convolutions
作者 | Guilin Liu, Fitsum A. Reda, Kevin J. Shih, Ting-Chun Wang, Andrew Tao, Bryan Catanzaro
单位 | 英伟达
论文 | https://arxiv.org/abs/1804.07723
解读 | https://zhuanlan.zhihu.com/p/163165243
代码 | https://github.com/NVIDIA/partialconv
引用 | 412

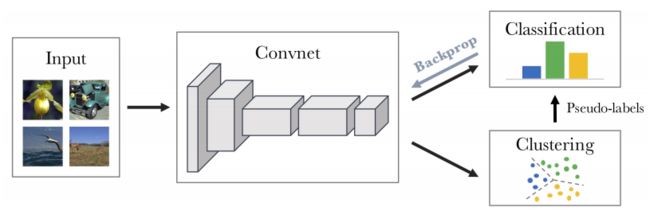
NO.11 无监督学习 DeepCluster
用聚类方法结合卷积网络,实现无监督端到端图像分类
Deep clustering for unsupervised learning of visual features
作者 | Mathilde Caron, Piotr Bojanowski, Armand Joulin, Matthijs Douze
单位 | FAIR
论文 | https://arxiv.org/abs/1807.05520
代码 | https://github.com/facebookresearch/deepcluster
解读 | https://zhuanlan.zhihu.com/p/41457268
引用 | 373
NO.12 语义分割 ICNet
高分辨率图像实时语义分割算法ICNet
ICNet for real-time semantic segmentation on high-resolution images
作者 | Hengshuang Zhao, Xiaojuan Qi, Xiaoyong Shen, Jianping Shi, Jiaya Jia
单位 | 香港中文大学;腾讯优图;商汤
论文 | https://arxiv.org/abs/1704.08545
代码 | https://github.com/hszhao/ICNet
引用 | 348

NO.13 AutoML Amc
用于移动端设备的模型压缩与加速的AutoML方法
Amc: Automl for model compression and acceleration on mobile devices
作者 | Yihui He, Ji Lin, Zhijian Liu, Hanrui Wang, Li-Jia Li, Song Han
单位 | 麻省理工学院;卡内基梅隆大学;谷歌
论文 | https://arxiv.org/abs/1802.03494
代码 | https://github.com/mit-han-lab/amc
引用 | 344

NO.14 图像翻译 DRIT
基于解耦表示的图像翻译
Diverse image-to-image translation via disentangled representations
作者 | Hsin-Ying Lee, Hung-Yu Tseng, Jia-Bin Huang, Maneesh Kumar Singh, Ming-Hsuan Yang
单位 | 加州大学默塞德分校;弗吉尼亚理工大学;Verisk Analytics;谷歌云
论文 | https://arxiv.org/abs/1808.00948
解读 | https://zhuanlan.zhihu.com/p/70402066
代码 | https://github.com/HsinYingLee/DRIT/
主页 | http://vllab.ucmerced.edu/hylee/DRIT/
备注 | ECCV 2018 oral
引用 | 338

NO.15 弱监督学习
探索弱监督学习预训练模型的基线
Exploring the limits of weakly supervised pretraining
作者 | Dhruv Mahajan, Ross Girshick, Vignesh Ramanathan, Kaiming He, Manohar Paluri, Yixuan Li, Ashwin Bharambe, Laurens van der Maaten
单位 | Facebook
论文 | https://arxiv.org/abs/1805.00932
代码 | https://github.com/facebookresearch/WSL-Images
引用 | 331

NO.16 人体姿态估计与跟踪
Simple baselines for human pose estimation and tracking
作者 | Bin Xiao, Haiping Wu, Yichen Wei
单位 | 微软亚洲研究院;电子科技大学
论文 | https://arxiv.org/abs/1804.06208
代码 | https://github.com/microsoft/human-pose-estimation.pytorch
引用 | 302

NO.17 实时语义分割 Bisenet
Bisenet: Bilateral segmentation network for real-time semantic segmentation
作者 | Changqian Yu, Jingbo Wang, Chao Peng, Changxin Gao, Gang Yu, Nong Sang
单位 | 华中科技大学;北大;旷视
论文 | https://arxiv.org/abs/1808.00897
代码 | https://github.com/CoinCheung/BiSeNet
解读 | https://zhuanlan.zhihu.com/p/41475332
引用 | 266

NO.18 视觉目标跟踪 DaSiamRPN
Distractor-aware siamese networks for visual object tracking
作者 | Zheng Zhu, Qiang Wang, Bo Li, Wei Wu, Junjie Yan, Weiming Hu
单位 | 国科大;中国科学院自动化研究所;商汤
论文 | https://arxiv.org/abs/1808.06048
解读 | https://zhuanlan.zhihu.com/p/42546692
代码 | https://github.com/foolwood/DaSiamRPN
引用 | 263

NO.19 动作识别
视频中时间关系推理用于动作识别
Temporal relational reasoning in videos
作者 | Bolei Zhou, Alex Andonian, Aude Oliva, Antonio Torralba
单位 | MIT CSAIL
论文 | https://arxiv.org/abs/1711.08496
解读 | https://zhuanlan.zhihu.com/p/32534351
代码 | https://github.com/metalbubble/TRN-pytorch
主页 | http://relation.csail.mit.edu/
引用 | 260
NO.20 Pixel2mesh 从单帧RGB图像生成三维网格模型
Pixel2mesh: Generating 3d mesh models from single rgb images
作者 | Nanyang Wang, Yinda Zhang, Zhuwen Li, Yanwei Fu, Wei Liu, Yu-Gang Jiang
单位 | 复旦大学;普林斯顿大学;英特尔;腾讯AI实验室
论文 | https://arxiv.org/abs/1804.01654
解读 | https://zhuanlan.zhihu.com/p/44346869
代码 | https://github.com/nywang16/Pixel2Mesh
引用 | 245





备注如:CV

计算机视觉交流群
交流学习最新CV技术前沿,扫码备注拉入群。
我爱计算机视觉
微信号:aicvml
QQ群:805388940
微博知乎:@我爱计算机视觉
网站:www.52cv.net

在看,让更多人看到 