第29期Datawhale组队学习——NLP之transformer
目录
- 前言
- 学习路线
-
- Task01:熟悉规则,学习概览(9.13)
-
- 1、环境配置+本地阅读
- 2、NLP之Transformers初了解
- Task02:attention和transformer(9.14、9.15)
-
- 1、Attention
- 2、Transformer
- 3、Pytorch编写完整的Transformer
- Task03:学习BERT(9.16、9.17)
-
- 1、图解BERT
- 2、模型结构
- 3、与训练任务
- 4、BERT的应用
- Task04:学习GPT(9.18、9.19)
-
- 0、语言模型
- 1、GPT详解
- 2、GPT-2的应用
- Task05:编写BERT模型(9.20、9.21)
- Task06:BERT应用到下游任务(9.22、9.23)
- Task07:文本分类、超参搜索
- Task08:序列标注
- Task09:抽取式问答
前言
Datawhale第29期组队学习来了!这次选择的是Datawhale开源学习项目——“基于transformers的自然语言处理入门”,学习周期为9.13-10.1,在此记录初次接触NLP的小白学习历程。基于教程写的比较详细,这里的记录只作为补充。
学习路线
Task01:熟悉规则,学习概览(9.13)
教程:第一章前言1.0-本地阅读和代码运行环境配置和1.1-Transformers在NLP中的兴起
1、环境配置+本地阅读
笔者使用的软件实验环境为Win10系统,Anaconda3。
1、环境配置(Anaconda Prompt)
(1)建立NLP的环境:conda create --name NLP python=3.8.5然后输入 y
(2)激活环境:conda activate NLP
(3)安装transformers、datasets、notebook、torch、sklearn、scipy、matplotlib、torchtext、seaborn、spacy(不加-i选项豆瓣的源也没有问题,我配置用的是中科大的)
pip install transformers==4.4.2 -i https://pypi.douban.com/simple/
pip install datasets==1.6.2 -i https://pypi.douban.com/simple/
pip install torch==1.9.0 -i https://pypi.douban.com/simple/
pip install jupyter scikit-learn scipy matplotlib torchtext seaborn spacy
2、打开文件(Anaconda Prompt)
首先到下载好的文件夹路径(D盘)D:
cd D:\Datawhale\learn-nlp-with-transformers-main\docs
然后启动NLP环境conda activate NLP
然后使用jupyter notebook
3、关闭Jupyter
首先关闭jupyter的网页
然后在Anaconda Prompt中退出jupyter按键ctrl+C
然后退出NLP环境conda deactivate
退出cmdexit
问题1尝试用VSCode软件打开.md格式(Markdown)文件,发现图片没有正常显示
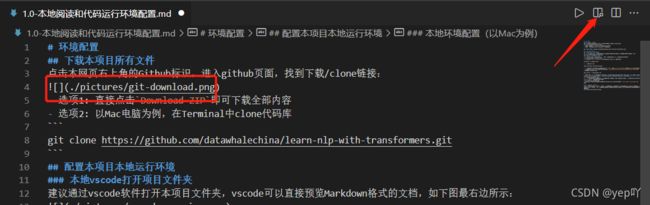
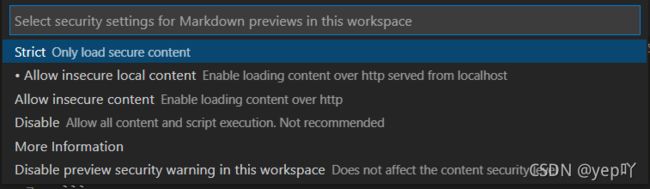
解决1首先点击右上角按钮打开预览窗口Open Preview to the Side;如果依然没有图片显示,需要修改预览安全设置:在VScode编辑页面,按快捷键Ctrl+Shift+P,搜索Markdown:Change Preview Security Settings(Markdown:更改预览安全设置),然后选择Allow insecure local content(允许本地不安全内容)即可


问题2运行conda create --name NLP python=3.8.5 报错Collecting package metadata (current_repodata.json): failed。
解决2沿路径C:\Users\1207\.condarc把除了defaults的源都删除再运行安装代码,为了避免后面安装软件速度太慢而需要再次添加国内的源,等下载完成后就马上加回来~
2、NLP之Transformers初了解
文章一:2021年如何科学的“微调”预训练模型?
文章二:从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史
这两篇文章只看懂浅显的地方,很多文字有待进一步学习~
Task02:attention和transformer(9.14、9.15)
教程:第二章2.1-图解Attention、2.2-图解transformer、2.2.1-Pytorch编写完整的Transformer(2.2.2选修)
1、Attention
-
什么是seq2seq模型?——seq2seq是一种常见的NLP模型结构,由编码器(Encoder)和解码器(Decoder)组成,编码器会处理输入序列中的每个元素并获得输入信息,这些信息会被转换成为context向量。当我们处理完整个输入序列后,编码器把 context向量发送给解码器,解码器通过context向量中的信息,逐个元素输出新的序列。
-
基于RNN的seq2seq模型如何处理文本/长文本序列?——采用第n个时间步得到hidden state#i(隐藏层状态)和第n+1个时间步的输入向量input#i+1,来得到新的输出hidden state#i+1。与编码器类似,解码器在每个时间步也会得到 hidden state(隐藏层状态),而且也需要把 hidden state(隐藏层状态)从一个时间步传递到下一个时间步。
-
seq2seq模型处理长文本序列时遇到了什么问题?——基于RNN的seq2seq模型编码器所有信息都编码到了一个context向量中,便是这类模型的瓶颈。一方面单个向量很难包含所有文本序列的信息,另一方面RNN递归地编码文本序列使得模型在处理长文本时面临非常大的挑战(比如RNN处理到第500个单词的时候,很难再包含1-499个单词中的所有信息了)
-
基于RNN的seq2seq模型如何结合attention来改善模型效果?——编码器会把更多的数据传递给解码器,编码器把所有时间步的 hidden state(隐藏层状态)传递给解码器,而不是只传递最后一个 hidden state(隐藏层状态),注意力模型的解码器在产生输出之前,做了一个额外的attention处理。因此,attention可以简单理解为:一种有效的加权求和技术,其艺术在于如何获得权重。
2、Transformer
- Transformer宏观结构
Transformer宏观结构属于seq2seq范畴,只是将之前seq2seq中的编码器和解码器,从RNN模型替换成了Transformer模型。Transformer由编码部分和解码部分组成,而编码部分和解码部分又由多个网络结构相同的编码层和解码层组成。每个编码层由self-attention和FFNN组成,每个解码层由self-attention、FFN和encoder-decoder attention组成。
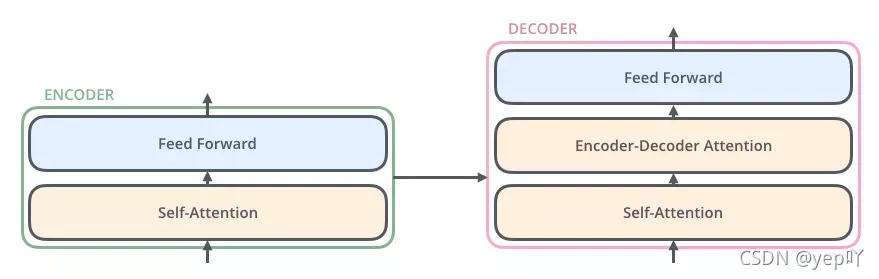
- Transformer细节结构
·输入处理(词向量+位置向量)——输入文本序列经过输入处理之后得到了一个向量序列,这个向量序列将被送入第1层编码器。
·编码器——向量序列在单层encoder中的流动:融合位置信息的词向量进入self-attention层,self-attention的输出每个位置的向量再输入FFN神经网络得到每个位置的新向量。编码器的每个子层(Self Attention 层和 FFNN)都有一个残差连接和层标准化(layer-normalization)。
·解码器——编码器一般有多层,第一个编码器的输入是一个序列文本,最后一个编码器输出是一组序列向量。
·线性层和softmax——线性层就是一个普通的全连接神经网络,可以把解码器输出的向量,映射到一个更大的向量,这个向量称为 logits 向量。Softmax 层会将其转换为概率。
·损失函数——Transformer训练的时候,需要将解码器的输出和label一同送入损失函数,以获得loss,最终模型根据loss进行方向传播。
3、Pytorch编写完整的Transformer
问题:之前已经装好环境,打开jupyter notebook导入库文件报错ModuleNotFoundError: No module named ‘torch’,以为是模块没有安装好,但经检查发现竟然kernel error(错误文档显示错误:ImportError: DLL load failed while importing win32api: 找不到指定的程序。)
解决:参考教程可以解决上述问题!
先找到文件pywin32_postinstall.py的路径
输入命令:python D:\Anaconda\Scripts\pywin32_postinstall.py -install
Task03:学习BERT(9.16、9.17)
教程:第二章2.3
1、图解BERT
图解BERT:BERT首先在大规模无监督语料上进行预训练,然后在预训练好的参数基础上增加一个与任务相关的神经网络层,并在该任务的数据上进行微调训练,最终取得很好的效果。BERT的这个训练过程可以简述为:预训练+微调(finetune)。BERT可以理解为基于双向Transformer的编码器,而BERT模型更大,训练数据更多;输入句子对时,片段嵌入,位置编码可学习。

2、模型结构
BERT原始论文提出了BERT-base和BERT-large两个模型,base的参数量比large少一些,BERT模型结构基本上就是Transformer的encoder部分,BERT-base对应的是12层encoder,BERT-large对应的是24层encoder。

(1)模型输入
BERT模型输入在一句话最开始拼接了一个[CLS] token,这个特殊的[CLS] token经过BERT得到的向量表示通常被用作当前的句子表示。BERT将一串单词作为输入,这些单词多层encoder中不断向上流动,每一层都会经过 Self-Attention和前馈神经网络。

(2)模型输出
BERT输入的所有token经过BERT编码后,会在每个位置输出一个大小为 hidden_size(在 BERT-base中是 768,在BERT-large中是 1024)的向量。

3、与训练任务
(1)任务一:带掩码的语言模型
(2)任务二:相邻句子的判断/下一个句子预测
4、BERT的应用
(1)判断两个句子是否相似
(2)判断单个句子的情感
(3)序列标注
(4)问答
… …
Task04:学习GPT(9.18、9.19)
教程:第二章2.4
0、语言模型
(1)自编码语言模型(如BERT):通过随机Mask输入的部分单词,预测被Mask的单词,可以融入上下文信息,即双向预训练。
(2)自回归语言模型(如GPT):根据输入句子的一部分文本来预测下一个词,即单向预训练。
1、GPT详解
BERT是基于Encoder构建的,BERT使用是Self Attention层(允许一个位置关注到它两边的信息),而GPT-2基于Decoder构建,GPT-2 使用masked Self Attention(只让模型看到左边的信息)。

(1)GPT-2能够处理1024 个token。每个token沿着自己的路径经过所有的Decoder层。 token在所有Decoder层中依次被处理,然后沿着该路径生成一个向量。根据这个向量和模型的词汇表给所有可能的词计算出一个分数。把上一步的输出添加到下一步输入序列,然后让模型做下一个预测。

(2)输入编码:得到词向量+位置编码
GPT-2 在嵌入矩阵中查找输入的单词的对应的 embedding 向量,并且融入位置编码(指示单词在序列中的顺序),再把这个 embedding+position 传给模型的第一个模块。

(3)多层Decoder
第一层Decoder现在可以处理 token所对应的向量了:首先通过 Self Attention 层,然后通过全连接神经网络。一旦Transformer 的第1个Decoder处理了 token,依旧可以得到一个向量,这个结果向量会再次被发送到下一层Decoder。
(4)Self-Attention过程
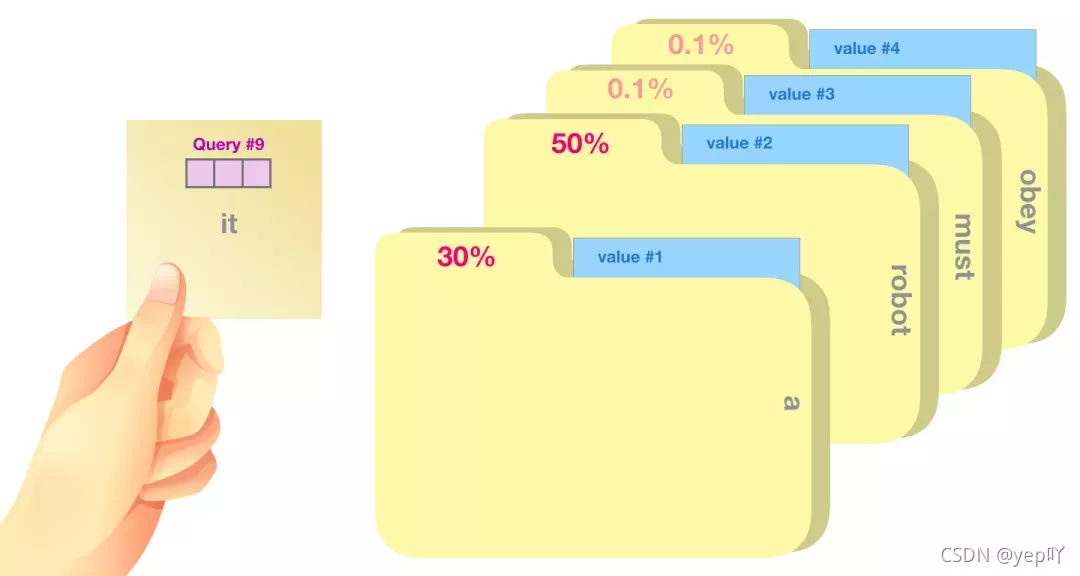
Self-Attention 沿着句子中每个 token 进行处理,主要组成部分包括 3 个向量:Query、Key和Value,可以类比成在一个文件柜里面搜索,Query 向量是一个便签,上面写着你正在研究的主题,而 Key 向量就像是柜子里的文件夹的标签。当你将便签与标签匹配时,我们取出匹配的那些文件夹的内容,这些内容就是 Value 向量,而且是需要找到一系列Value 向量。将 Query 向量与每个文件夹的 Key 向量相乘,会为每个文件夹产生一个分数score,将每个 Value 向量乘以对应的分数,然后求和,就得到了 Self Attention 的输出。
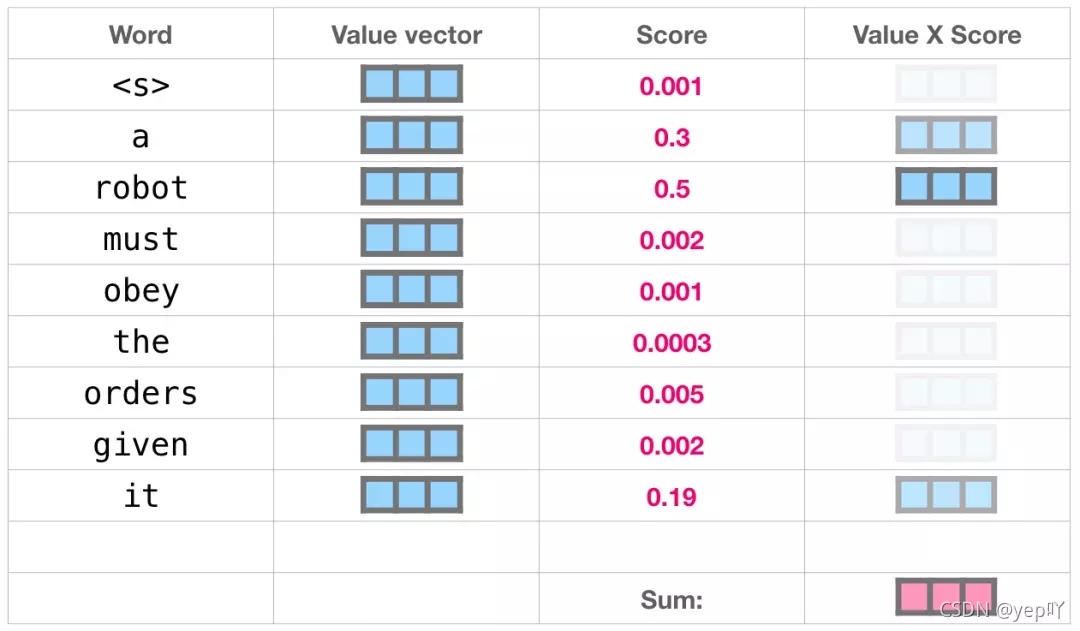
(5)模型的输出
当模型顶部的Decoder层产生输出向量时,模型会将这个向量乘以一个巨大的嵌入矩阵来计算该向量和所有单词embedding向量的相关得分,结果被解释为模型词汇表中每个词的分数,经过softmax之后被转换成概率。选择最高分数的 token,模型就完成了一次迭代,输出一个单词。模型会继续迭代,直到所有的单词都已经生成,或者直到输出了表示句子末尾的 token。
2、GPT-2的应用
(1)机器翻译
(2)生成摘要
(3)迁移学习
(4)音乐生成
… …
Task05:编写BERT模型(9.20、9.21)
教程:第三章3.1
HuggingFace/Transformers/models/bert:代码网址
1、Tokenization分词-BertTokenizer
BertTokenizer 是基于BasicTokenizer和WordPieceTokenizer的分词器。BasicTokenizer负责按标点、空格等分割句子,并处理是否统一小写,以及清理非法字符。WordPieceTokenizer在词的基础上,进一步将词分解为子词(subword)。
2、Model-BertModel
BertModel 主要为 transformer encoder 结构,包含三个部分:
embeddings,即BertEmbeddings类的实体,根据单词符号获取对应的向量表示;encoder,即BertEncoder类的实体;pooler,即BertPooler类的实体,这一部分是可选的。
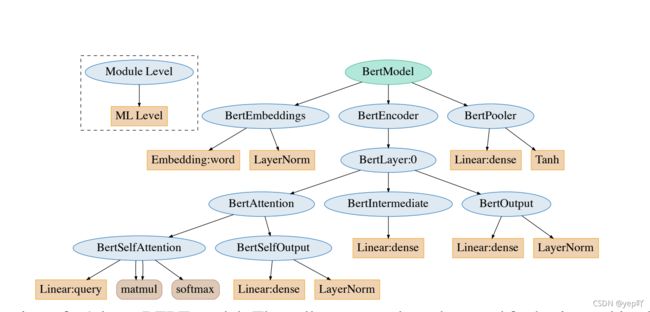
2.1-BertEmbeddings(word_embeddings,token_type_embeddings, position_embeddings,三个 embedding 不带权重相加,并通过一层 LayerNorm+dropout 后输出,其大小为(batch_size, sequence_length, hidden_size))
2.2-BertEncoder(包含多层 BertLayer,利用 gradient checkpointing 技术以降低训练时的显存占用。)
2.2.1.1 BertAttention
2.2.1.1.1 BertSelfAttention
2.2.1.1.2 BertSelfOutput
2.2.1.2 BertIntermediate
2.2.1.3 BertOutput
2.3-BertPooler(简单地取出了句子的第一个token,即[CLS]对应的向量,然后过一个全连接层和一个激活函数后输出:(这一部分是可选的,因为pooling有很多不同的操作))
--------未完待续----------------
Task06:BERT应用到下游任务(9.22、9.23)
教程:第三章3.2
3、BERT-based Models应用模型
4、BERT训练和优化
5、Bert解决NLP任务
BertForSequenceClassification
BertForMultiChoice
BertForTokenClassification
BertForQuestionAnswering
6、BERT训练与优化
Pre-Training
Fine-Tuning
--------未完待续----------------
Task07:文本分类、超参搜索
教程:第四章4.0 基于Hugging Face -Transformers的预训练模型微调
1、加载数据
2、数据预处理
3、微调预训练模型
4、超参数搜索
问题1 ValueError: check_hostname requires server_hostname
解决1关掉
问题2 ConnectionError: Couldn’t reach https://raw.githubusercontent.com/huggingface/datasets/1.6.2/metrics/glue/glue.py
Task08:序列标注
--------未完待续----------------
Task09:抽取式问答
教程:第四章4.3 抽取式问答
注意:本篇抽取式问答任务是从文本中抽取答案,并不是直接生成答案!
------------分割线--------------