目标检测组件之FPN介绍
目标检测组件之FPN
论文:https://arxiv.org/abs/1612.03144
FPN网络可以说是一个非常经典的组件,twostage网络中一般都会加上去,能够有效的提升对小目标的检测能力,cascade_rcnn/faster_rcnn+big backbone+fpn+dcn的经典组合经久不衰。
这篇博客就结合mmdetection的fpn模块来简单介绍一下FPN网络


这个是目标检测常用结构,输入一张图像,经过backbone提取特征,最后输出一张featuremap,以fasterrcnn举例,featuremap直接输入rpn得到proposals,proposals在featuremap上提取proposal feature然后进行box的分类和位置的回归。
为了增加多尺度能力,在上面结构上有很多变种,第一个就是下图的特征图像金字塔(Featurized image pyramid ),每一层做预测,缺点是计算量太大。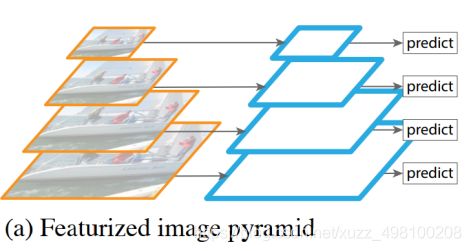
本文提出的FPN:

接下来我会从mmdetection的fpn模块实现具体介绍:
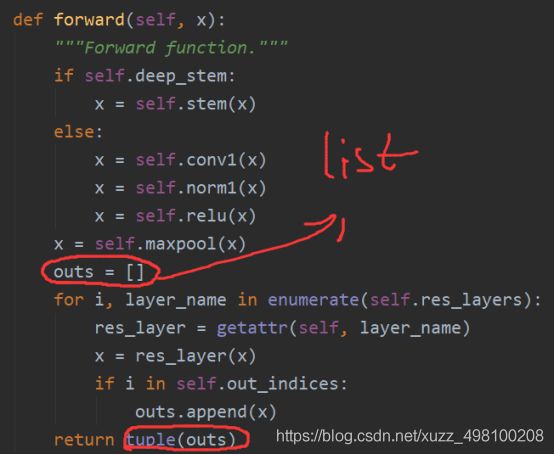
注意在mmdection的backbone中,输出是一个list,list里面是每个block的结果。这样的好处是方便FPN计算
接下来我们再看FPN是如何实现的:
在mmdection中,我们以twostage为例:
在
class TwoStageDetector(BaseDetector)
中。
Backbone输出的结果直接进入neck中,这里的neck就可以是fpn
def extract_feat(self, img):
"""Directly extract features from the backbone+neck."""
x = self.backbone(img)
if self.with_neck:
x = self.neck(x) #注意,这个neck就是FPN
return x
我们再看FPN具体是怎么做的:
在necks/fpn,py中可以直接找到class FPN(nn.Module)
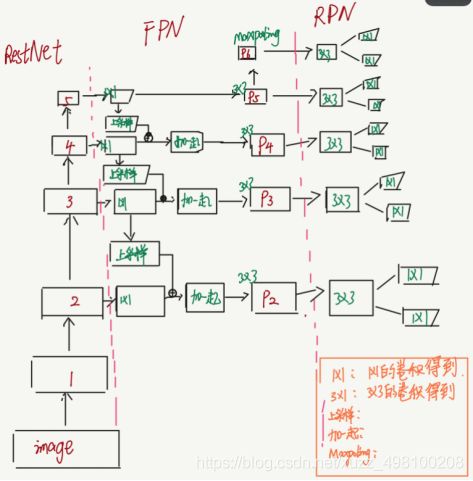
在介绍FPN代码之前我还是先贴一下FPN的结构图,这个是我在这里找到的灵魂绘图,非常的形象。对于backbone来说,已经完成了down-top过程,FPN要做的其实就是top-down。
首先是FPN的init阶段
for i in range(self.start_level, self.backbone_end_level):
l_conv = ConvModule(
in_channels[i],
out_channels,
1,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg if not self.no_norm_on_lateral else None,
act_cfg=act_cfg,
inplace=False)
fpn_conv = ConvModule(
out_channels,
out_channels,
3,
padding=1,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
act_cfg=act_cfg,
inplace=False)
self.lateral_convs.append(l_conv)
self.fpn_convs.append(fpn_conv)
在FPN的init阶段,注意这里的lateral_convs就是一个list,list里面存的就是1x1的卷积,对应的就是配图里这里,同理fpn_convs也是一个list,存的是最后的3x3卷积

完了以后我们来看FPN的前向部分
def forward(self, inputs):
"""Forward function."""
assert len(inputs) == len(self.in_channels)
# build laterals
laterals = [
lateral_conv(inputs[i + self.start_level])
for i, lateral_conv in enumerate(self.lateral_convs)
]
# build top-down path
used_backbone_levels = len(laterals)
for i in range(used_backbone_levels - 1, 0, -1):
# In some cases, fixing `scale factor` (e.g. 2) is preferred, but
# it cannot co-exist with `size` in `F.interpolate`.
if 'scale_factor' in self.upsample_cfg:
laterals[i - 1] += F.interpolate(laterals[i],
**self.upsample_cfg)
else:
prev_shape = laterals[i - 1].shape[2:]
laterals[i - 1] += F.interpolate(
laterals[i], size=prev_shape, **self.upsample_cfg)
# build outputs
# part 1: from original levels
outs = [
self.fpn_convs[i](laterals[i]) for i in range(used_backbone_levels)
]
# part 2: add extra levels
if self.num_outs > len(outs):
# use max pool to get more levels on top of outputs
# (e.g., Faster R-CNN, Mask R-CNN)
if not self.add_extra_convs:
for i in range(self.num_outs - used_backbone_levels):
outs.append(F.max_pool2d(outs[-1], 1, stride=2))
# add conv layers on top of original feature maps (RetinaNet)
else:
if self.add_extra_convs == 'on_input':
extra_source = inputs[self.backbone_end_level - 1]
elif self.add_extra_convs == 'on_lateral':
extra_source = laterals[-1]
elif self.add_extra_convs == 'on_output':
extra_source = outs[-1]
else:
raise NotImplementedError
outs.append(self.fpn_convs[used_backbone_levels](extra_source))
for i in range(used_backbone_levels + 1, self.num_outs):
if self.relu_before_extra_convs:
outs.append(self.fpn_convs[i](F.relu(outs[-1])))
else:
outs.append(self.fpn_convs[i](outs[-1]))
return tuple(outs)
其实这个前向就干了一件事情:完成top-down过程,如果原理图画的一样:

在backbone阶段每个block输出的featuremap经过1x1的卷积(说实话我还是很欣赏mmdetection的代码风格的,除了相比facebook的maskrcnn部署麻烦一点之外,整个结构会清爽很多)
laterals = [
lateral_conv(inputs[i + self.start_level])
for i, lateral_conv in enumerate(self.lateral_convs)
]
然后与下一个block输出进行插值后相加
prev_shape = laterals[i - 1].shape[2:]
laterals[i - 1] += F.interpolate(
laterals[i], size=prev_shape, **self.upsample_cfg)
最后过3x3的卷积:
outs = [
self.fpn_convs[i](laterals[i]) for i in range(used_backbone_levels)
]
然后输出outs,这里的outs同样也是一个list,最后进入RPN。至此FPN阶段结束。