Transformer前沿——语义分割
Transformer 进军语义分割
- 进军方向
- SETR: Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers (CVPR 2021)
-
- 网络结构图
- 实验效果
-
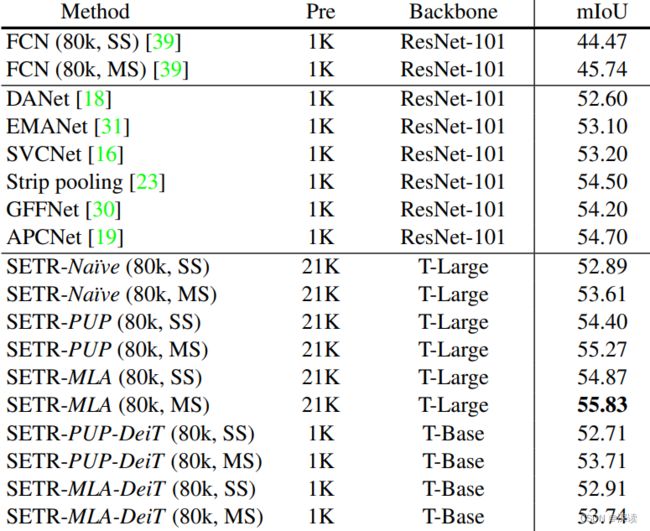
- ADE20K 数据集上效果
- Pascal Voc 数据集上的效果
- TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation
-
- 网络结构图
- 实验效果
-
- Synapse multi-organ CT 数据集上的效果
- SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers (NeuralPS 2021)
-
- 网络结构图
- 实验效果
-
- ADE20K和Cityscape数据集上的效果
进军方向
Transformer自2017年诞生之后,迅速在NLP领域攻城略地,在极短的时间内晋升成为NLP领域绝对的霸主。Transformer进军CV领域的行动早在2018年就开始了,但是行进缓慢,直到2020年谷歌再次出手,提出Transformer进军CV领域的里程碑式的神作 ViT ,屠榜ImageNet、CIFAR10、CIFAR100,将Transformer在CV领域的潜力展示给世人,大家深受震撼与启发,随即争相涌入ViT研究浪潮中,直接推动了ViT的蓬勃发展。
在阐述Transformer在CV领域开疆拓土的行军路线前,简单概括一条范式。基于深度学习的方法解决计算机视觉领域的各种任务,诸如图像分类、目标检测、语义分割、实例分割等,都遵循统一的范式,即,特征提取模块+任务模块。
特征提取模块 + 分类器 = 图像分类网络
特征提取模块 + 检测器 = 目标检测网络
特征提取模块 + 分割器 = 语义分割网络
…
到这里,读者朋友可能已经猜到了,Transformer可以取代语义分割任务中的特征提取模块。但Transformer是否比原本基于 CNN 的特征提取模块更好?答案是肯定的,
C N N : 级 联 卷 积 虽 能 扩 大 感 受 野 , 但 是 有 效 感 受 野 只 占 理 论 感 受 野 很 小 一 部 分 , 也 就 是 说 , 卷 积 无 法 直 接 提 取 长 距 离 信 息 ; T r a n s f o r m e r : 提 取 到 的 特 征 向 量 有 更 丰 富 的 全 局 上 下 文 信 息 。 \begin{aligned} CNN &: 级联卷积虽能扩大感受野,但是有效感受野只占理论感受野很小一部分,也就是说,卷积无法直接提取长距离信息;\\ Transformer &: 提取到的特征向量有更丰富的全局上下文信息。 \end{aligned} CNNTransformer:级联卷积虽能扩大感受野,但是有效感受野只占理论感受野很小一部分,也就是说,卷积无法直接提取长距离信息;:提取到的特征向量有更丰富的全局上下文信息。
至此,我们了解到,用Transformer取代语义分割中的特征提取模块是可行的,接下来,首先介绍Transformer在语义分割领域的开山制作 SETR
SETR: Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers (CVPR 2021)
SETR 是 Segmentation Transformer 前两个字母的组合
作者单位是 复旦、牛津大学、萨里大学、腾讯优图、Facebook
网络结构:ViT 特征提取 + 多层次特征融合 + 解码器
网络结构图
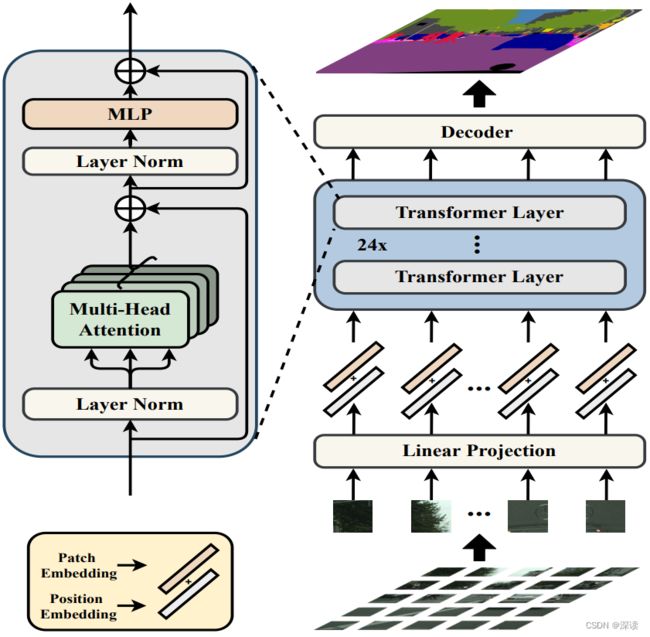
在语义分割中特征提取模块又称编码器,分割器又称解码器,SETR中直接采用 ViT 中 24 层做高层语义上下文建模。
ViT 特征提取:ViT先将输入图像等分为许多个patch,然后通过 展平(Flatten) 和 线性映射(Linear Projection) 操作将这些patch映射为序列,然后加上各自的位置编码,输入Transformer中做特征提取。
多层次特征融合:编码器中包括 24个 Transformer Layer,为了同时获得高层语义和低层语义信息,作者将 第6、12、18、24层的输出结果从序列恢复到二维,然后按通道维度拼接(concat),得到具有丰富语义层次的特征向量。
解码器:采用的传统的 CNN 逐级解码,将特征向量的宽高恢复到原图像大小,扩大宽高的同时缩减通道数为类别数。
实验效果
在ADE20K取得 50.28%的mIoU,这是该数据集首次出现mIoU超过50%的记录,同时在 Pascal Context取得 55.83%的mIoU,均是 STOA效果。
ADE20K 数据集上效果

Pascal Voc 数据集上的效果
TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation
面向医学图像分割,结合 擅于长距离上下文建模的Transformer 和 擅于捕捉低层细节信息的UNet。
作者单位:约翰霍普金斯大学、电子科技大学、斯坦福大学
网络结构:CNN特征提取 + 长距离上下文建模 + UNet解码器
网络结构图
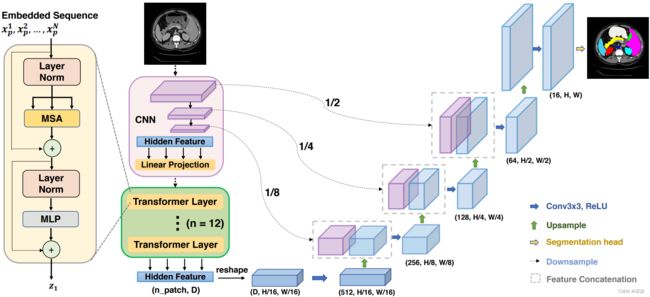
CNN特征提取:级联卷积提取特征向量,各个stage的输出用于跳跃连接。
长距离上下文建模:使用12个Transformer层对CNN特征提取模块中得到特征向量,进一步做长距离上下文建模。
UNet解码器:跳跃连接,逐级解码。
实验效果
Synapse multi-organ CT 数据集上的效果

SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers (NeuralPS 2021)
作者单位:香港大学、南京大学、英伟达、加州理工大学
网络结构:Mix-FFN取代位置嵌入 + Efficient Self-Attention缩减时间复杂度 + Overlapped patch Merging 保留局部连续性 + 极简decoder
网络结构图

Mix-FFN:ViT中位置编码的分辨率是固定的,在模型测试使用阶段,输入图像的分辨率并不固定,因此如果采用位置编码,则需通过重采样获得位置编码,显然,这会影响模型预测。本文作者认为通过填充零,卷积核尺寸3x3的卷积可以获得位置信息。具体做法是在一个简单的 前馈神经网络(FFN)中加入3x3 Conv,公式表示如下:
x o u t = MLP ( GELU ( Conv 3 × 3 ( MLP ( x i n ) ) ) ) + x i n \mathbf{x}_{o u t}=\operatorname{MLP}\left(\operatorname{GELU}\left(\operatorname{Conv}_{3 \times 3}\left(\operatorname{MLP}\left(\mathbf{x}_{i n}\right)\right)\right)\right)+\mathbf{x}_{i n} xout=MLP(GELU(Conv3×3(MLP(xin))))+xin
Efficient Self-Attention:作者指出经典的自注意力机制算法时间复杂度为 O ( N 2 ) O(N^2) O(N2),其中N为序列的长度。在ViT中序列长度 N 通常等于 H*W,其中H、W分别为图像高和宽。作者指出对于高分辨率图像,自注意力机制的时间复杂度太大,因此提出更高效的自制注意力算法。核心步骤为:
1)通过 reshape 操作,将输入序列的shape从 N × C N\times C N×C变为 N R × C R \frac{N}{R}\times CR RN×CR,其中R为缩减系数;
2)通过线性映射,将 shape为 N R × C R \frac{N}{R}\times CR RN×CR 的序列映射为 shape为 N R × C \frac{N}{R}\times C RN×C 的序列。
SegFormer的四个stage的缩减系数分别为 64、16、 4、1。
Overlapped patch Merging:本文的作者认为ViT中采用的 patch merging 算法丢失了patch周围的局部连续性信息。因此提出,重叠的patch划分方法,具体做法通过一个宽高为3的窗口,步长为2,边缘填充为1,进行滑动。通过重叠保留了patch周围的局部连续性。
极简decoder:作者认为特征提取过程中使用的自注意力机制,已经提取到了充分高层的语义特征,因此在解码阶段,无需通过级联卷积进一步提升模型感受野。因此,本文中的解码器只包含几个简单的线性映射和上采样层。
实验效果
ADE20K和Cityscape数据集上的效果

面向移动设备的TopFormer (CVPR 2022),医学分割 DS-TransUNet,…