命名实体识别Baseline模型BERT-MRC总结
文章目录
- BERT-MRC模型
- BERT-MRC模型的理论基础
-
- MRC机器阅读理解
- Pointer Network指针网络
- BERT-MRC模型的细节
-
- 模型的输入
- 模型结构
- 实验
-
- 数据集
- 结果
- 代码地址及使用方法
-
- GitHub地址
- 使用方法举例
-
- 1.原始数据
- 2.预处理一:使用basicTokenizer分词
- 3.预处理二:给输入数据添加query
- 4.开始训练
- 5.预处理三:数据加载
- 6.训练过程
- 7.预测结果
BERT-MRC模型
BERT-MRC模型是目前实体识别领域的一个SOTA模型,在数据量较小的情况下效果较其他模型要更好,原因是因为BERT-MRC模型可以通过问题加入一些先验知识,减小由于数据量太小带来的问题,在实际实验中,在数据量比较小的情况下,BERT-MRC模型的效果要较其他模型要更好一点。BERT-MRC模型很适合在缺乏标注数据的场景下使用。
BERT-MRC模型的理论基础
MRC机器阅读理解
给定一个文本序列X,它的长度为n,要抽取出其中的每个实体,其中实体都属于一种实体类型。假设该数据集的所有实体标签集合为Y,那么对其中的每个实体标签y,比如地点“国家”,都有一个关于它的问题 q ( y ) q(y) q(y) 。这个问题可以是一个词,也可以是一句话等等。使用上述MRC中片段抽取的思想,输入文本序列X和问题 q ( y ) q(y) q(y), a a a 是需要抽取的实体,BERT-MRC通过建模 P ( a ∣ C , Q ) P(a∣C,Q) P(a∣C,Q) 来实现实体抽取
对于问题 q ( y ) q(y) q(y) 的构造是建模 P ( a ∣ C , Q ) P(a∣C,Q) P(a∣C,Q) 的重要环节。BERT-MRC使用“标注说明”作为每个标签的问题。所谓“标注说明”,是在构造某个数据集的时候提供给标注者的简短的标注说明。比如标注者要去标注标签为“国家”的所有实体,那么对应“国家”的标注说明就是 “指拥有共同的语言、文化、种族、血统、领土、政府或者历史的社会群体
Pointer Network指针网络
在某些任务中,输入严格依赖于输入,或者说输出只能从输入中选择。例如输入一段话,提取这句话中最关键的几个词语。又或是输入一串数字,输出对这些数字的排序。这时如果使用传统seq2seq模型,则忽略了输入只能从输出中选择这个先验信息,Pointer Networks正是为了解决这个问题而提出的。
Pointer Networks模型非常简洁,结构是基本的seq2seq + attention。对于传统的attention模型,在计算权重之后会对encoder的state进行加权,求得一个向量c。而Pointer Networks则在计算权重之后,选择概率最大的encoder state最为输出。示意图如下:
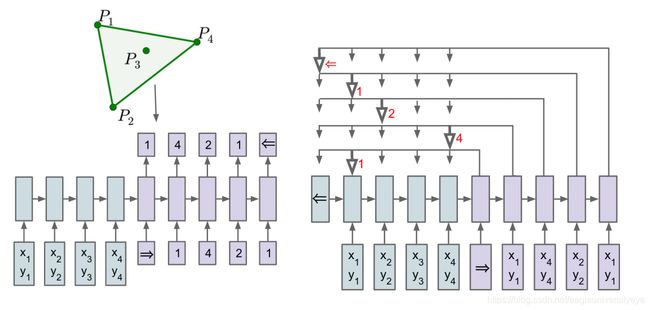
以寻找闭包这个任务作为例子,寻找闭包是从输入的点中找到一些点能把所有的点围起来。例如左上角图的闭包是 ( P 1 , P 2 , P 4 , P 1 ) (P_1, P_2, P_4, P_1) (P1,P2,P4,P1) 。左上角则是使用传统的seq2seq模型来解决这个任务,右边则是使用Pointer Networks。其中箭头指向的则是对应时间步的输出。采用这种方式就能解决输出只能从输入中选择的问题。
Pointer Network经常在摘要和机器阅读理解任务中使用,但是也可以用在信息抽取任务中,信息抽取也是从目标文本中抽取目标(例如实体)片段。
BERT-MRC模型的细节
BERT-MRC模型在不同的数据集上的效果差异比较大,而且数据处理也非常影响模型的性能,所以BERT-MRC模型是一个性能非常不稳定的模型,需要使用者理解其内部的原理后采用合适的方法来使用。
BERT-MRC模型能取得比其他模型更好的性能的原因是它特殊的数据处理方法,在输入文本前加上了实体类型的描述信息,这些实体类型的描述作为先验知识提高了模型抽取的效果,所以BERT-MRC模型在数据量匮乏的场景下,通过在输入文本前面拼接的query获得了一定的先验信息,提升了性能。
模型的输入
与其他模型不同,在使用BERT-MRC模型之前,需要进行大量的数据预处理操作,例如,有一个实体识别数据集,该数据集中有一下三种类型的实体:

在数据预处理阶段需要将实体类型的描述作为query,拼接到每个输入句子的前面,然后针对性的修改原有的标注。例如下面的例子:

对于输入文本 “比尔盖茨1975年与好友保罗·艾伦一起创办了微软公司” 这句话,由于数据集共有三种类型的实体,所以需要为这句话构建三条数据,首先以人名的描述作为query,这条数据中标注有两个人名类型的实体(上述绿色虚线圈出);然后以地名的描述作为query,这条数据中没有实体;以机构名作为query的这条数据有一个实体。可以发现,BERT-MRC模型增加了数据的规模,并通过query增加了先验信息,但是同时也造成一条数据中的实体更少了,这回增加标签不平衡问题。
同时作为query的实体类型的描述,也会很大地影响BERT-MRC模型的性能,在BERT-MRC模型的论文中,作者就提出了多种不同的方式作为query,例如举一些实体的例子等,但是实验结果表明,还是自然语言形式的实体描述效果最佳。
模型结构
在使用BERT编码得到词向量之后,训练三个分类器,分别用于预测开始、结束位置标签以及一个概率矩阵。开始、结束位置序列是和输入文本等长的一个序列,对应每个字符是否是实体片段的开始和结束位置,概率矩阵代表文本中每个片段是否是实体片段的概率。
上述两个标签序列和一个矩阵三个分类器在训练过程中共可以求三个loss,模型的总loss是上述三个loss之和。

在实验过程中,我发现片段的概率矩阵在数据量较大的情况下会占用很多内存和显存,所以当数据超过一定规模时,需要将文本片段的概率矩阵分类器去掉,否则模型将难以训练。
只使用开始和结束位置序列在难以解决重叠实体问题,在数据量较大,无法使用文本片段概率矩阵的情况下,可以使用五个二分类器,通过对BIOES五个标签进行分类,代替两个二分类器对开始和结束位置进行分类。

实验
数据集
采用 CLUENER 数据集
结果
| 模型 | f1 |
|---|---|
| BiLSTM+CRF | 0.8714 |
| BERT | 0.9341 |
| BERT+BiLSTM+CRF | 0.9371 |
| BERT-MRC | 0.9542 |
代码地址及使用方法
GitHub地址
https://github.com/JavaStudenttwo/BERT_MRC
使用方法举例
这里以 CCKS竞赛 链想家计算科技大赛:COVID-19 知识图谱构建 赛道一 为例,分析一些数据预处理,模型训练以及最终结果整合的过程。
1.原始数据
原始数据存放在 data_dir/KG_Covid19_Task1/origin_data 文件夹下,其中 new_train.json 有标注,可以分成训练集和验证集用于模型的训练,new_val.json无标注,是测试一,submit_example.json是竞赛提交格式样例
2.预处理一:使用basicTokenizer分词
data_dir/KG_Covid19_Task1/process/origin_process.py中的generate_process_data()函数
使用basicTokenizer将英文词汇做初步的切分,将原来按照字符为单位切分的标注方式,改为使用basicTokenizer分词后的词汇为单位的标注方式。
以上一步的文件作为输入,这一步输出文件为data_dir/KG_Covid19_Task1/process/文件夹下的train.json和val.json

3.预处理二:给输入数据添加query
data_dir/KG_Covid19_Task1/generate_data.py
这一步的处理会给文本句子添加query,query是实体类型的描述,自己定义即可,推荐用Wikipedid搜索的结果

data_dir/KG_Covid19_Task1/query文件夹下
自己定义的query,即实体类型的描述

预处理二的结果存放到data_dir/KG_Covid19_Task1/data文件夹下,mrc-ner.tarin和mrc-ner.dev两个文件
对一个句子都,将其不同类型的实体分开组织,每一条数据包括一个文本句子,一个实体类型描述,该类型实体的开始结束位置。

4.开始训练
run/train_bert_mrc.py 文件修改完参数后开始训练


5.预处理三:数据加载
数据加载部分的内容主要在data_loader文件夹下

data_loader/mrc_utils.py对之前的数据进一步处理,解决bert的tokener将完整单词切分成多个片段的问题。

6.训练过程
BERT_MRC的模型结构非常简单,就是将bert编码的hidden向量解码为start_pos和end_pos两个序列,求两个loss后相加,再反向迭代更新

7.预测结果
run/evaluate_mrc_ner.py 文件修改完参数后开始预测,预测使用的数据为data_dir/KG_Covid19_Task1/data/mrc-ner.dev,预测结果保存在result.json文件中
将模型预测得到的结果result.json文件放到data_dir/KG_Covid19_Task1/process/文件夹下进行后处理。
调用origin_process.py文件的generate_result()函数,将数据处理成可以在评测系统中提交的格式。