用Pytorch实现CIFAR10数据集分类(持续修改中)
1.导包
"""导包"""
import collections
import numpy as np
import math
import os
import shutil
import pandas as pd
import torch
import torchvision
import matplotlib.pyplot as plt
from torch import nn
import torch .nn.functional as F
2.整理数据集
"""整理数据集"""
def read_csv_labels(fname):
"""读取 fname 来给标签字典返回一个文件名"""
with open(fname, 'r') as f:
# 跳过文件头行 (列名)
lines = f.readlines()[1:] #将文件按行读取,返回值为列表
tokens = [l.rstrip().split(',') for l in lines] #将每一行用逗号分隔开来,并去掉多余的空格
return dict(((name, label) for name, label in tokens)) #将token里面的信息遍历出来,并赋值给name和label并做成字典
labels = read_csv_labels('../CIFAR10 Image-Classification/trainLabels.csv')
for item in labels.items():
print(item)
print('类别 :', len(set(labels.values())))
整理好后的样子

3.将验证集从原始的数据集中拆分出来
"""将验证集从原始的数据集中拆分出来"""
data_dir=('../CIFAR10 Image-Classification/')
def copyfile(filename, target_dir):
"""将文件复制到目标目录"""
os.makedirs(target_dir, exist_ok=True) #创建多层目录,目录名为target—dir
shutil.copy(filename, target_dir) #将filename的文件复制到target—dir当中
def reorg_train_valid(data_dir, labels, valid_ratio):
# 训练数据集中示例最少的类别中的示例数
n = collections.Counter(labels.values()).most_common()[-1][1]
# 验证集中每个类别的示例数
n_valid_per_label = max(1, math.floor(n * valid_ratio)) #示例数与1比大小,n为训练数据集中示例最少的类别中的示例数,valid_ratio 是验证集中的示例数与原始训练集中的示例数之比
label_count = {}
for train_file in os.listdir(os.path.join(data_dir,'train')): #列出train 路径下所有的文件并遍历给train_file,该数据集是打乱的
label = labels[train_file.split('.')[0]] #用.将train_file切片,切片后只有两行,第一行为类别标号,第二行为类别名称,我们只取第一行赋值给label
fname = os.path.join(data_dir, 'train', train_file) #fname=data_dir/train/train_file,train_file有label和名称组成
copyfile(fname, os.path.join(data_dir, 'train_valid_test',
'train_valid', label)) #将data_dir/train/train_file的文件复制到data_dir/train_valid_test/train_valid/label,原始的cifar10数据未经过划分
if label not in label_count or label_count[label] < n_valid_per_label:
copyfile(fname, os.path.join(data_dir, 'train_valid_test',
'valid', label)) #将数据添加到验证集
label_count[label] = label_count.get(label, 0) + 1 #返回字典label_count中label元素所对应的值,label_count[label]给字典label——count中元素label赋值为label值+1
else:
copyfile(fname, os.path.join(data_dir, 'train_valid_test',
'train', label)) #将数据添加到训练集
return n_valid_per_label
4.在预测期间整理测试集,以方便读取
def reorg_test(data_dir):
for test_file in os.listdir(os.path.join(data_dir, 'test')): #将测试集的数据全部列出,然后遍历出来
copyfile(os.path.join(data_dir, 'test', test_file),
os.path.join(data_dir, 'train_valid_test', 'test',
'unknown')) #将data_dir/test/test_file文件夹复制到data_dir/train_valid_test/test,标签放到unknown下面
5.调用前面定义的函数
def reorg_cifar10_data(data_dir, valid_ratio):
labels = read_csv_labels(os.path.join(data_dir, 'trainLabels.csv')) #读取data_dir/trainLabels.csv中的name和label以字典形式输出
reorg_train_valid(data_dir, labels, valid_ratio)
reorg_test(data_dir)
# batch_size = 32
valid_ratio = 0.1 #验证集与训练集为1比9
reorg_cifar10_data(data_dir, valid_ratio) ##输出一个data_dir文件,里面有划分好i的test,train,valid
6.图像增广
transform_train = torchvision.transforms.Compose([
# 在高度和宽度上将图像放大到40像素的正方形 图片本身是32*32太小了
torchvision.transforms.Resize(40),
# 随机裁剪出一个高度和宽度均为40像素的正方形图像,
# 生成一个面积为原始图像面积0.64到1倍的小正方形,
# 然后将其缩放为高度和宽度均为32像素的正方形
torchvision.transforms.RandomResizedCrop(32, scale=(0.64, 1.0), #裁剪的图里面有高和宽至少是原来的64%
ratio=(1.0, 1.0)),
torchvision.transforms.RandomHorizontalFlip(),
torchvision.transforms.ToTensor(),
# 标准化图像的每个通道
torchvision.transforms.Normalize([0.4914, 0.4822, 0.4465],
[0.2023, 0.1994, 0.2010])]) #对RGB的三个通道做Normalize
transform_test = torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize([0.4914, 0.4822, 0.4465],
[0.2023, 0.1994, 0.2010])])
6.读取由原图像组成的数据集
"""读取由原图像组成的数据集"""
train_ds, train_valid_ds = [torchvision.datasets.ImageFolder(
os.path.join(data_dir, 'train_valid_test', folder),
transform=transform_train) for folder in ['train', 'train_valid']]
valid_ds, test_ds = [torchvision.datasets.ImageFolder(
os.path.join(data_dir, 'train_valid_test', folder),
transform=transform_test) for folder in ['valid', 'test']]
7.制作dataloader
train_loader, train_valid_loader = [torch.utils.data.DataLoader(
dataset, batch_size=100, shuffle=True, drop_last=True,num_workers=2)
for dataset in (train_ds, train_valid_ds)]
valid_loader = torch.utils.data.DataLoader(valid_ds, batch_size=10, shuffle=False,
drop_last=True,num_workers=2)
test_loader = torch.utils.data.DataLoader(test_ds, batch_size=100, shuffle=False,
drop_last=False,num_workers=2)
8.定义模型
from torchvision import models as models
net=models.resnet18(pretrained=True)
net.fc=torch.nn.Linear(512,10)
print(net)
修改后的全连接层
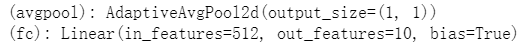
9.权重初始化
import torch
import torch.nn.init as init
for name,module in net._modules.items() :
if (name=='fc'):
init.kaiming_uniform_(module.weight,a=0,mode='fan_in')
10.调用GPU
devices=torch.device("cuda:0" if torch.cuda.is_available() else"cpu")
# import torch.nn
# if torch.cuda.device_count()>1:
# model=torch.nn.DataParallel(model)
print(devices)
11.定义优化器
optimizer = torch.optim.SGD(net.parameters(), lr=1e-1, momentum=0.9,weight_decay=5e-4) #weight_decay为权重衰减
StepLR = torch.optim.lr_scheduler.StepLR(optimizer, step_size=5,gamma=0.65) #优化lr,每隔 lr_period个epoch就给当前的lr乘以lr_decay
12.定义准确率函数
import torch
def accuracy(pred,target):
pred_label=torch .argmax(pred,1) #返回每张照片10个预测值里面最大数的标签
correct=sum(pred_label==target).to(torch .float ) #如果这个标签等于真实标签,则将数值转化为个数,转化为float类型并返回给correct
return correct,len(pred)#返回正确的个数
13.定义损失函数
celoss=nn.CrossEntropyLoss()
best_acc=0
14.定义字典来存放loss和acc
acc={'train':[],"val":[]}
loss_all={'train':[],"val":[]}
15.验证和训练
"""训练和验证"""
net.to(devices)
for epoch in range(10):
print('epoch',epoch+1,'*******************************')
net.train()
train_total_loss,train_correctnum, train_prednum=0.,0.,0.
for images,labels in train_loader:
images,labels=images.to(devices),labels.to(devices)
outputs=net(images)
loss=celoss(outputs,labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_total_loss+=loss.item()
correctnum,prednum= accuracy(outputs,labels)
train_correctnum +=correctnum
train_prednum +=prednum
net.eval()
valid_total_loss,valid_correctnum, valid_prednum=0.,0.,0.
for images,labels in valid_loader:
images,labels=images.to(devices),labels.to(devices)
outputs=net(images)
loss=celoss(outputs,labels)
valid_total_loss += loss.item()
correctnum,prednum= accuracy(outputs,labels)
valid_correctnum +=correctnum
valid_prednum +=prednum
"""计算平均损失"""
train_loss = train_total_loss/len(train_loader)
valid_loss = valid_total_loss/len(valid_loader)
"""将损失值存入字典"""
loss_all['train'].append(train_loss )
loss_all['val'].append(valid_loss)
"""将准确率存入字典"""
acc['train'].append(train_correctnum/train_prednum)
acc['val'].append(valid_correctnum/valid_prednum)
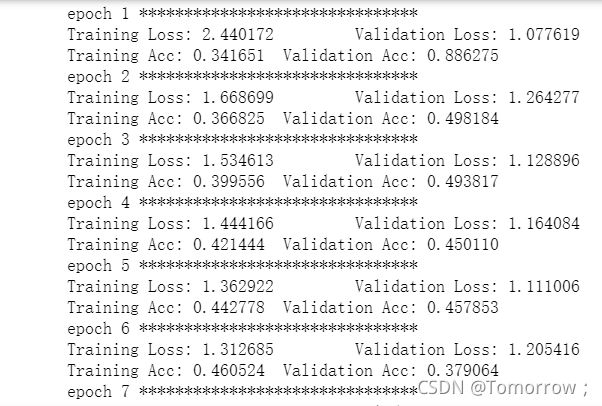
print('Training Loss: {:.6f} \tValidation Loss: {:.6f}'.format(train_loss, valid_loss))
print('Training Acc: {:.6f} \tValidation Acc: {:.6f}'.format(train_correctnum/train_prednum,valid_correctnum/valid_prednum))
16.训练结果
17.绘制loss和acc曲线
"""绘图"""
plt.xlabel('Epoch')
plt.xlim((0,9))
plt.ylabel('Loss Value')
plt.ylim((1,2.5))
plt.title('loss function')
plt.plot(loss_all['train'] ,color='orange')
plt.plot(loss_all['val'],color='blue' )
plt.show()
plt.ylim((0, 1))
plt.xlim((0, 9))
plt.plot(acc['train'] ,color='orange')
plt.plot(acc['val'],color='blue' )
plt.title('accuracy rate')
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.show()
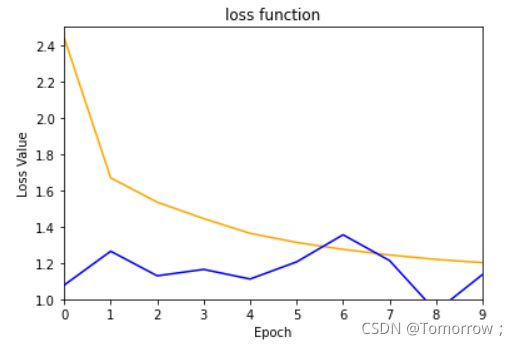
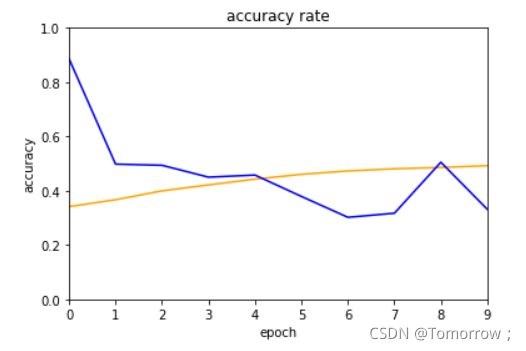
验证集的数据有一些问题,后面会持续修改
18.完整代码
"""导包"""
import collections
import numpy as np
import math
import os
import shutil
import pandas as pd
import torch
import torchvision
import matplotlib.pyplot as plt
from torch import nn
import torch .nn.functional as F
"""整理数据集"""
def read_csv_labels(fname):
"""读取 fname 来给标签字典返回一个文件名"""
with open(fname, 'r') as f:
# 跳过文件头行 (列名)
lines = f.readlines()[1:] #将文件按行读取,返回值为列表
tokens = [l.rstrip().split(',') for l in lines] #将每一行用逗号分隔开来,并去掉多余的空格
return dict(((name, label) for name, label in tokens)) #将token里面的信息遍历出来,并赋值给name和label并做成字典
labels = read_csv_labels('../CIFAR10 Image-Classification/trainLabels.csv')
for item in labels.items():
print(item)
print('类别 :', len(set(labels.values())))
"""将验证集从原始的数据集中拆分出来"""
data_dir=('../CIFAR10 Image-Classification/')
def copyfile(filename, target_dir):
"""将文件复制到目标目录"""
os.makedirs(target_dir, exist_ok=True) #创建多层目录,目录名为target—dir
shutil.copy(filename, target_dir) #将filename的文件复制到target—dir当中
def reorg_train_valid(data_dir, labels, valid_ratio):
# 训练数据集中示例最少的类别中的示例数
n = collections.Counter(labels.values()).most_common()[-1][1]
# 验证集中每个类别的示例数
n_valid_per_label = max(1, math.floor(n * valid_ratio)) #示例数与1比大小,n为训练数据集中示例最少的类别中的示例数,valid_ratio 是验证集中的示例数与原始训练集中的示例数之比
label_count = {}
for train_file in os.listdir(os.path.join(data_dir,'train')): #列出train 路径下所有的文件并遍历给train_file,该数据集是打乱的
label = labels[train_file.split('.')[0]] #用.将train_file切片,切片后只有两行,第一行为类别标号,第二行为类别名称,我们只取第一行赋值给label
fname = os.path.join(data_dir, 'train', train_file) #fname=data_dir/train/train_file,train_file有label和名称组成
copyfile(fname, os.path.join(data_dir, 'train_valid_test',
'train_valid', label)) #将data_dir/train/train_file的文件复制到data_dir/train_valid_test/train_valid/label,原始的cifar10数据未经过划分
if label not in label_count or label_count[label] < n_valid_per_label:
copyfile(fname, os.path.join(data_dir, 'train_valid_test',
'valid', label)) #将数据添加到验证集
label_count[label] = label_count.get(label, 0) + 1 #返回字典label_count中label元素所对应的值,label_count[label]给字典label——count中元素label赋值为label值+1
else:
copyfile(fname, os.path.join(data_dir, 'train_valid_test',
'train', label)) #将数据添加到训练集
return n_valid_per_label
"""在预测期间整理测试集,以方便读取"""
def reorg_test(data_dir):
for test_file in os.listdir(os.path.join(data_dir, 'test')): #将测试集的数据全部列出,然后遍历出来
copyfile(os.path.join(data_dir, 'test', test_file),
os.path.join(data_dir, 'train_valid_test', 'test',
'unknown')) #将data_dir/test/test_file文件夹复制到data_dir/train_valid_test/test,标签放到unknown下面
"""调用前面定义的函数"""
def reorg_cifar10_data(data_dir, valid_ratio):
labels = read_csv_labels(os.path.join(data_dir, 'trainLabels.csv')) #读取data_dir/trainLabels.csv中的name和label以字典形式输出
reorg_train_valid(data_dir, labels, valid_ratio)
reorg_test(data_dir)
# batch_size = 32
valid_ratio = 0.1 #验证集与训练集为1比9
reorg_cifar10_data(data_dir, valid_ratio) ##输出一个data_dir文件,里面有划分好i的test,train,valid
"""图像增广"""
transform_train = torchvision.transforms.Compose([
# 在高度和宽度上将图像放大到40像素的正方形 图片本身是32*32太小了
torchvision.transforms.Resize(40),
# 随机裁剪出一个高度和宽度均为40像素的正方形图像,
# 生成一个面积为原始图像面积0.64到1倍的小正方形,
# 然后将其缩放为高度和宽度均为32像素的正方形
torchvision.transforms.RandomResizedCrop(32, scale=(0.64, 1.0), #裁剪的图里面有高和宽至少是原来的64%
ratio=(1.0, 1.0)),
torchvision.transforms.RandomHorizontalFlip(),
torchvision.transforms.ToTensor(),
# 标准化图像的每个通道
torchvision.transforms.Normalize([0.4914, 0.4822, 0.4465],
[0.2023, 0.1994, 0.2010])]) #对RGB的三个通道做Normalize
transform_test = torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize([0.4914, 0.4822, 0.4465],
[0.2023, 0.1994, 0.2010])])
"""读取由原图像组成的数据集"""
train_ds, train_valid_ds = [torchvision.datasets.ImageFolder(
os.path.join(data_dir, 'train_valid_test', folder),
transform=transform_train) for folder in ['train', 'train_valid']]
valid_ds, test_ds = [torchvision.datasets.ImageFolder(
os.path.join(data_dir, 'train_valid_test', folder),
transform=transform_test) for folder in ['valid', 'test']]
"""制作dataloader"""
train_loader, train_valid_loader = [torch.utils.data.DataLoader(
dataset, batch_size=100, shuffle=True, drop_last=True,num_workers=2)
for dataset in (train_ds, train_valid_ds)]
valid_loader = torch.utils.data.DataLoader(valid_ds, batch_size=10, shuffle=False,
drop_last=True,num_workers=2)
test_loader = torch.utils.data.DataLoader(test_ds, batch_size=100, shuffle=False,
drop_last=False,num_workers=2)
"""定义模型"""
from torchvision import models as models
net=models.resnet18(pretrained=True)
net.fc=torch.nn.Linear(512,10)
print(net)
"""权重初始化"""
import torch
import torch.nn.init as init
for name,module in net._modules.items() :
if (name=='fc'):
init.kaiming_uniform_(module.weight,a=0,mode='fan_in')
"""调用GPU"""
devices=torch.device("cuda:0" if torch.cuda.is_available() else"cpu")
# import torch.nn
# if torch.cuda.device_count()>1:
# model=torch.nn.DataParallel(model)
print(devices)
"""定义优化器"""
optimizer = torch.optim.SGD(net.parameters(), lr=1e-1, momentum=0.9,weight_decay=5e-4) #weight_decay为权重衰减
StepLR = torch.optim.lr_scheduler.StepLR(optimizer, step_size=5,gamma=0.65) #优化lr,每隔 lr_period个epoch就给当前的lr乘以lr_decay
"""定义准确率函数"""
import torch
def accuracy(pred,target):
pred_label=torch .argmax(pred,1) #返回每张照片10个预测值里面最大数的标签
correct=sum(pred_label==target).to(torch .float ) #如果这个标签等于真实标签,则将数值转化为个数,转化为float类型并返回给correct
return correct,len(pred)#返回正确的个数
acc={'train':[],"val":[]}
loss_all={'train':[],"val":[]}
celoss=nn.CrossEntropyLoss()
best_acc=0
"""训练和验证"""
net.to(devices)
for epoch in range(10):
print('epoch',epoch+1,'*******************************')
net.train()
train_total_loss,train_correctnum, train_prednum=0.,0.,0.
for images,labels in train_loader:
images,labels=images.to(devices),labels.to(devices)
outputs=net(images)
loss=celoss(outputs,labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_total_loss+=loss.item()
correctnum,prednum= accuracy(outputs,labels)
train_correctnum +=correctnum
train_prednum +=prednum
net.eval()
valid_total_loss,valid_correctnum, valid_prednum=0.,0.,0.
for images,labels in valid_loader:
images,labels=images.to(devices),labels.to(devices)
outputs=net(images)
loss=celoss(outputs,labels)
valid_total_loss += loss.item()
correctnum,prednum= accuracy(outputs,labels)
valid_correctnum +=correctnum
valid_prednum +=prednum
"""计算平均损失"""
train_loss = train_total_loss/len(train_loader)
valid_loss = valid_total_loss/len(valid_loader)
"""将损失值存入字典"""
loss_all['train'].append(train_loss )
loss_all['val'].append(valid_loss)
"""将准确率存入字典"""
acc['train'].append(train_correctnum/train_prednum)
acc['val'].append(valid_correctnum/valid_prednum)
# lr.append(lr)
print('Training Loss: {:.6f} \tValidation Loss: {:.6f}'.format(train_loss, valid_loss))
print('Training Acc: {:.6f} \tValidation Acc: {:.6f}'.format(train_correctnum/train_prednum,valid_correctnum/valid_prednum))
"""绘图"""
plt.xlabel('Epoch')
plt.xlim((0,9))
plt.ylabel('Loss Value')
plt.ylim((1,2.5))
plt.title('loss function')
plt.plot(loss_all['train'] ,color='orange')
plt.plot(loss_all['val'],color='blue' )
plt.show()
plt.ylim((0, 1))
plt.xlim((0, 9))
plt.plot(acc['train'] ,color='orange')
plt.plot(acc['val'],color='blue' )
plt.title('accuracy rate')
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.show()