Unity机器学习3 ML-Agents模仿学习(Imitation Learning)
Unity机器学习3 ML-Agents模仿学习(Imitation Learning)
上一章的例子中,机器通过自主学习不断强化训练来学习(Reinforcement Learning),随机移动来到目标球位置,相对来说比较简单,只是通过随机数来学习。如果是复杂一点的环境,可能耗费几百万Step也可能无法学习到。
本章将介绍让机器人通过模仿进行(Imitation Learning)学习,达到并超越。
这里我举例说明什么是模仿学习。
假如你家的小狗狗喜欢撕咬沙发,那么你告诉它不要咬他是听不懂的。你可以找一只仿真小狗玩具或者布偶,让布偶去撕咬沙发,然后你再用你沙包大的拳头揍布偶小狗,看看你家狗狗的反应,如果他明白了撕咬沙发会挨揍,那么他就达到了学习目的。
强化学习和模仿学习(Reinforcement Learning Vs Imitation Learning)
区别就好比上面的例子,强化学习就是让狗自己学会不咬沙发,听起来挺难的,不是吗?模仿学习就是用上面的布偶的办法或者其他一些有效的方法。
或者我们换一个例子:
让一个从来没玩过电子游戏的人玩游戏,他根本不知道手柄的按钮都是干什么的,按了遥感就移动了,按了旁边的按钮A就发射子弹了,这个就属于强化学习。而模仿学习就是有一个游戏高手在旁边指导,你觉得哪一个学习更加有效呢?
机器模仿学习就是要达到这样效率的学习方式。下面我们还是通过一个Demo来了解。
Demo编写
本章的例子我们编写一个喂食器,方块(agent)需要走到按钮处,踩下按钮,这样就会触发掉出一块糖,然后再去吃糖获得奖励。
我们先把场景梳理一遍。

和上一章场景类似
wall,四个面,BoxCollider我们不勾选IsTrigger,阻止agent掉落。
plane是地板。
foodSpawn是出现food的衍生器。

foodSpawn上需要挂一个脚本
using System.Collections;
using System.Collections.Generic;
using UnityEngine;
//UTF8 说明
public class FoodSpawn : MonoBehaviour
{
public GameObject prefab;
public bool hasFood;
GameObject food;
public Vector3 GetFoodAt()
{
if (food == null)
return Vector3.zero;
return food.transform.localPosition;
}
//投食
public void PutInFood()
{
hasFood = true;
food = GameObject.Instantiate(prefab);
food.name = "food";
food.SetActive(true);
food.transform.parent = transform.parent;
food.transform.localPosition = transform.localPosition;
}
//获取食物(被吃掉)
public void GetFood()
{
hasFood = false;
if (food != null)
GameObject.Destroy(food);
food = null;
}
}
food(灰色)是foodSpawn创建食物时候的prefab。
swith是方形的按钮。

using System.Collections;
using System.Collections.Generic;
using UnityEngine;
//UTF8 说明
public class FoodSwitch : MonoBehaviour
{
public FoodSpawn foodSpawn; //触发的食物衍生
public Renderer renderSwitch; //改变按钮颜色
public Material onMat; //按下的材质
public Material offMat; //关闭的材质
public bool isOn; //按钮是否打开
public void Clear()
{
isOn = false;
renderSwitch.material = offMat;
//让按钮还原高度
renderSwitch.transform.localPosition = new Vector3(0f, -0.5f, 0f);
//获得食物,并吃掉
foodSpawn.GetFood();
}
public void Switch(bool on)
{
if (!isOn && on)
{
isOn = true;
renderSwitch.material = onMat;
//让按钮按下去
renderSwitch.transform.localPosition = new Vector3(0f, -0.65f, 0f);
//投食
foodSpawn.PutInFood();
}
else if (isOn && !on)
{
isOn = false;
renderSwitch.material = offMat;
//让按钮还原高度
renderSwitch.transform.localPosition = new Vector3(0f, -0.5f, 0f);
//获得食物,并吃掉
foodSpawn.GetFood();
}
}
}
agent就是我们的ai,我们依旧编写一个FoodAgent,继承于FoodAgent,会自动添加BehaviorParameters脚本。我们还要添加一个DecisionRequester脚本。上一章我们都介绍过。

因为更新了MLAgent版本,Actions的Continuous和Discrete可以混用了。可以看到和上一章有所不同,本章我们用离散的方法来进行。
我们先贴上完整代码
using System.Collections;
using System.Collections.Generic;
using UnityEngine;
using Unity.MLAgents;
using Unity.MLAgents.Actuators;
using Unity.MLAgents.Sensors;
public class FoodAgent : Agent
{
[SerializeField] FoodSwitch foodSwitch;
[SerializeField] FoodSpawn foodSpawn;
[SerializeField] Renderer plane;
float moveSpd = 3f;
Rigidbody rig;
private void Awake()
{
rig = GetComponent<Rigidbody>();
}
//当一段经历开始
public override void OnEpisodeBegin()
{
transform.localPosition = new Vector3(Random.Range(-9f, 0f), 0f, Random.Range(-4f, 4f));
foodSwitch.transform.localPosition = new Vector3(Random.Range(3f, 9f), 0f, Random.Range(-4f, 4f));
foodSpawn.transform.localPosition = new Vector3(Random.Range(-9f, 0f), 5f, Random.Range(-4f, 4f));
foodSwitch.Clear();
Debug.Log("经历开始");
}
//通过传感器把坐标传入监视
public override void CollectObservations(VectorSensor sensor)
{
sensor.AddObservation(foodSwitch.isOn ? 1 : 0);
Vector3 dir = (foodSwitch.transform.localPosition - transform.localPosition).normalized;
sensor.AddObservation(dir.x);
sensor.AddObservation(dir.z);
sensor.AddObservation(foodSpawn.hasFood ? 1 : 0);
if (foodSpawn.hasFood)
{
Vector3 dirfood = (foodSpawn.GetFoodAt() - transform.localPosition).normalized;
sensor.AddObservation(dirfood.x);
sensor.AddObservation(dirfood.z);
}
else
{
sensor.AddObservation(0f);
sensor.AddObservation(0f);
}
//Debug.Log("Observations : " );
}
//行动接收
public override void OnActionReceived(ActionBuffers actions)
{
float moveX = actions.DiscreteActions[0];
float moveZ = actions.DiscreteActions[1];
bool switchon = actions.DiscreteActions[2] == 1;
//Debug.Log("OnAction : " + moveX+","+ moveZ + ","+ switchon);
Vector3 addforce = Vector3.zero;
switch (moveX)
{
case 0:
addforce.x = 0f; break;
case 1:
addforce.x = -1f; break;
case 2:
addforce.x = 1f; break;
}
switch (moveZ)
{
case 0:
addforce.z = 0f; break;
case 1:
addforce.z = -1f; break;
case 2:
addforce.z = 1f; break;
}
rig.velocity = addforce * moveSpd + new Vector3(0f, rig.velocity.y, 0f);
//transform.localPosition += new Vector3(moveX, 0f, moveZ) * Time.deltaTime * moveSpd;
//Debug.Log(rig.velocity+","+ addforce);
if (switchon)
{
Collider[] colls = Physics.OverlapBox(transform.position, Vector3.one * 0.5f);
for (int i = 0; i < colls.Length; i++)
{
if (colls[i].name.Equals("switch"))
{
if (!foodSwitch.isOn)
{
foodSwitch.Switch(true);
AddReward(1f);
Debug.Log("AddReward - switch");
}
}
}
}
AddReward(-1f / MaxStep);
}
//启发
public override void Heuristic(in ActionBuffers actionsOut)
{
ActionSegment<int> actions = actionsOut.DiscreteActions;
switch (Mathf.RoundToInt(Input.GetAxisRaw("Horizontal")))
{
case -1:
actions[0] = 1; break;
case 0:
actions[0] = 0; break;
case 1:
actions[0] = 2; break;
}
switch (Mathf.RoundToInt(Input.GetAxisRaw("Vertical")))
{
case -1:
actions[1] = 1; break;
case 0:
actions[1] = 0; break;
case 1:
actions[1] = 2; break;
}
actions[2] = Input.GetKey(KeyCode.E) ? 1 : 0;
}
private void OnCollisionEnter(Collision collision)
{
if (collision.collider.name.Equals("food"))
{
AddReward(1f);
Debug.Log("AddReward - food");
Destroy(collision.collider.gameObject);
foodSwitch.Switch(false);
EndEpisode();
}
}
}
回合开始 - OnEpisodeBegin
在每次回合开始,我们把agent,switch,foodspawn都随机一个位置。
收集观察信息 - CollectObservations
我们需要传入6个数据,如下图,对应BehaviorParameters里的SpaceSize(6),这6个数据依次为:
开关的开关(开or关);
开关的位置(x , z);
食物是否投放;
食物衍生点(x , z) - 没有食物,x、z传入0f。
行动 - OnActionReceived

我们再来巩固下上一章的内容,这里也比较容易和SpaceSize混淆。
注意我们在BehaviorParameters里因为配置了3个离散数据(Discrete Branches)。
分支0代表了moveX,可能出现三种情况(0,1,2),所以是3;
分支1代表了moveZ,同上;
分支2代表了是否按下了按钮。
代码中获得了上面的数据后,把moveX,moveZ传给了刚体进行物理移动。
swithon获得到按下按钮后,判断agent附近是否有按钮,如果有就按下按钮,这时候会有一个食物创建出来,并进行奖励。
函数最后有一个AddReward(-1f / MaxStep); 这个是为了让机器用最少的步数来学习。
吃掉食物 - OnCollisionEnter
这里检测到如果agent碰到了food就给予奖励,并删除food对象,并自动跳起食物开关。
启发 - Heuristic
这样所有的逻辑就通了,我们再来编写一个启发,来验证我们脚本是否正常执行。
首先通过判断左右是否按下传入第一个参数。
然后通过判断上下是否按下传入第二个参数。
最后通过判断是否按下了E传入第三个参数。
这样就模拟了机器的3个行动指令。
测试运行
到这里所有代码准备完毕了,我们来测试是否通畅。我们把BehaviorType调整到Heuristic Only,点击运行。
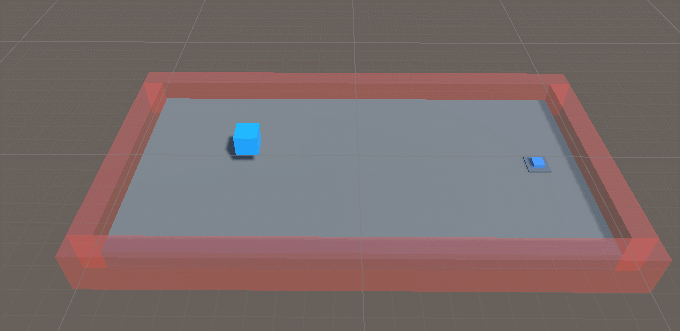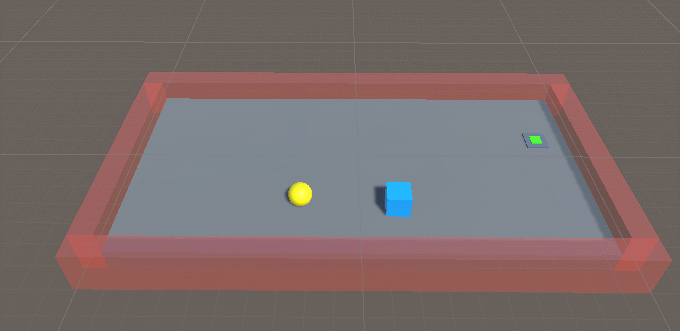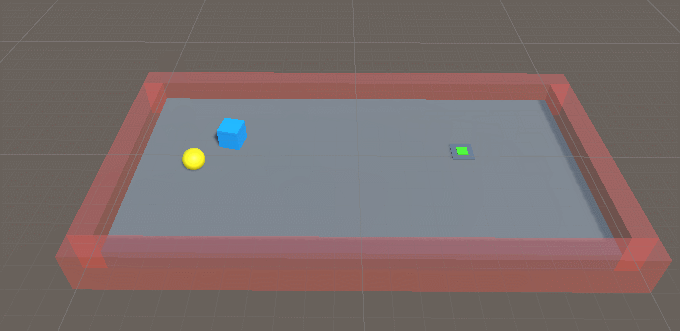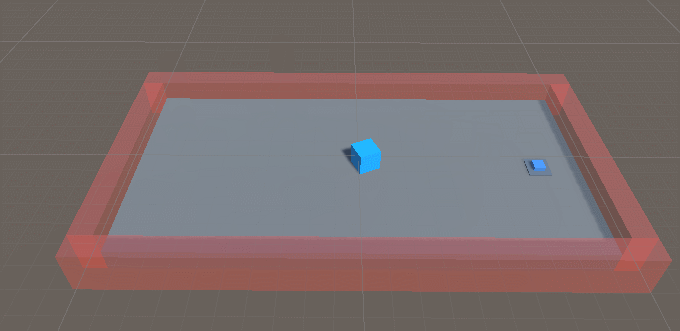
运行良好。
机器自主学习
首先我们也单独配置一个yaml。我们可以把上一节的movetarget.yaml复制一份,改为food.yaml
behaviors:
FoodAgent:
trainer_type: ppo
hyperparameters:
batch_size: 10
buffer_size: 100
learning_rate: 3.0e-4
beta: 5.0e-4
epsilon: 0.2
lambd: 0.99
num_epoch: 3
learning_rate_schedule: linear
beta_schedule: constant
epsilon_schedule: linear
network_settings:
normalize: false
hidden_units: 128
num_layers: 2
reward_signals:
extrinsic:
gamma: 0.99
strength: 1.0
max_steps: 500000
time_horizon: 64
summary_freq: 10000
注意,这里要修改behaviors的名字为FoodAgent,要和BehaviorParameters里的名字对应,也就是yaml文件的第二行。
然后我们开始mlagent的运行环境
进入项目目录输入
venv\scripts\activate
mlagents-learn config/food.yaml --run-id=foodtest1

我们把Unity的Behavior Type改回Default进入学习模式。
点击开始运行。

我们从GIF中可以看到,还算运气好,agent机器人按照随机的这种运行模式,进入了开关范围并按下了开关,黄色的Food也掉落了下来,但是agent并没有跑向food,因为所有的机器逻辑都是随机的,如果场景再更加复杂,只靠随机数来让机器学习,那么可能等到下班或者退休了。
所以这才开始进入本章的主题-模仿学习(Imitation Learning)
模仿学习(Imitation Learning)的学习录制
我会点击agent对象,添加新的脚本Demonstration Recorder(示范录制)

我们勾选Record复选框。
这里的名字随意,我这里还命名成FoodAgent,目录是Recorders。
我们把BehaviorType改为Heuristic Only。 这样我们再次运行起来后会把我们的Heuristic保存起来,作为训练人工智能的学习“影片”。我们点击运行后,进行几次操作后关闭游戏,就会生成一个demo文件。后面机器模仿学习会使用到。

我们把这个文件放入assets里看看

它会告诉您您玩了多少集以及您积累了多少奖励。
因为我们有两次奖励,所以MeanReward大概在1.9以上是比较高的奖励了。
录制使用和yaml配置
为了让机器学习使用这个FoodAgent.demo,我们需要修改yaml配置文件。
如下:
behaviors:
FoodAgent:
trainer_type: ppo
hyperparameters:
batch_size: 10
buffer_size: 100
learning_rate: 3.0e-4
beta: 5.0e-4
epsilon: 0.2
lambd: 0.99
num_epoch: 3
learning_rate_schedule: linear
beta_schedule: constant
epsilon_schedule: linear
network_settings:
normalize: false
hidden_units: 128
num_layers: 2
reward_signals:
extrinsic:
gamma: 0.99
strength: 1.0
gail:
strength: 0.1
demo_path: Recorders/FoodAgent.demo
behavioral_cloning:
strength: 0.1
demo_path: Recorders/FoodAgent.demo
max_steps: 500000
time_horizon: 64
summary_freq: 10000
在reward_signals里添加gail。
Gail - 模仿
GAIL (Generative Adversarial Imitation Learning) 代表模仿,是一种模仿学习算法,它使用对抗模仿学习,类似于 GAN(Generative Adversarial Networks)。
我们需要配置几个主要的gail参数:
strength
如果你想他做出和你的模仿相同的举动,可以设置strength为1.0,但是我们可以希望agent变得比你的操作做的更好、更加聪明,所以推荐strength占比不要太高。
demo_path
就是我们的模仿文件,这里填写路径和文件名Recorders/FoodAgent.demo
behavioral_cloning (BC) - 行为克隆
行为克隆behavioral_cloning (BC) 训练代理的神经网络以精确模仿一组演示中显示的动作。它基本上是一种完全复制所展示的任何内容的代理。这仅对最基本的 AI 代理有用。我们显然不会使用 BC,因为我们的代理和方块在随机位置生成。这使得代理无法正确执行任务,因为每个场景都是新的。
如果您想使用预先录制的演示帮助您的代理学习(尤其是在奖励稀少的环境中),除了获得外在奖励外,您通常可以同时启用低强度的 GAIL 和BC。因此,我们将使用 代表“生成对抗模仿学习”的GAIL。使用这种方法,有效地使用了两个神经网络。
behavioral_cloning:
strength: 0.1
demo_path:Recorders/FoodAgent.demo
这个行为克隆。他获得了和你一样的行为,然后和gail结合产生了和你相似的行为。
这里注意,最好格式全部使用空格,如果有tab,会提示报错,用过python的语法的朋友应该都了解。
self.get_mark())
yaml.scanner.ScannerError: while scanning for the next token
found character '\t' that cannot start any token
in "config/food.yaml", line 24, column 7
或者有其他错误提示。直到正常启动看到Unity的文字logo。
具体的配置可以参考这里。
关于BC(behavioral_cloning)和Gail可以看这里。
机器模仿学习
我们可以复制多个ground组,让很多agent一起学习。如图:

我们关闭DemonstrationRecorder的Record的勾。
我们再次调整HavroralType为default。
运行机器学习环境
mlagents-learn config/food.yaml --run-id=foodtest9

这样就开始群体训练了。
这里我发现有时很卡,看了下参数,可以把下面两个批次处理数量改大一些。
hyperparameters:
batch_size: 1024
buffer_size: 8192
训练了一下午,发现机器会越来越笨。再次阅读文档,调整了参数。
behaviors:
FoodAgent:
trainer_type: ppo
hyperparameters:
batch_size: 1024
buffer_size: 8192
learning_rate: 3.0e-4
beta: 5.0e-4
epsilon: 0.2
lambd: 0.99
num_epoch: 3
learning_rate_schedule: linear
beta_schedule: constant
epsilon_schedule: linear
network_settings:
normalize: false
hidden_units: 128
num_layers: 2
behavioral_cloning:
demo_path: Recorders/FoodAgent.demo
strength: 0.5
steps: 150000
reward_signals:
extrinsic:
strength: 1.0
gamma: 0.99
curiosity:
strength: 0.02
gamma: 0.99
encoding_size: 256
gail:
strength: 0.01
gamma: 0.99
encoding_size: 128
demo_path: Recorders/FoodAgent.demo
max_steps: 5000000
time_horizon: 64
summary_freq: 10000
yaml重要参数说明
文档里说到最好gail的strength小于0.1,看到官方的例子,都是0.01,我也改小了。
“gamma”决定了agent是应该寻求即时奖励还是追求从长远来看将获得更多奖励的策略。较低的值会导致前者,而较高的值(如 0.99)将寻找可以长期获得回报的东西。
“batch_size”和“buffer_size”确定代理在更新策略并继续梯度下降之前应该使用多少经验,以减少梯度下降期间的体验,但在更新策略时提供更多体验。这些 必须是彼此的倍数,否则数学不成立。
“beta”值。这会影响代理将采取的随机操作的数量。较高的值使其更随机。让我们将其设置为 0.003,因为如果代理找到了最大化奖励的路径,则任务不一定需要很大的偏差。
“max_steps”值从 500,000 增加到 5,000,000,以便为我们提供更多空间让代理训练。
该配置文件包含所谓的“超参数(hyperparameters)”,它们是一组特殊的参数,可以在最细粒度的级别上影响神经网络。
hidden_units-值是神经网络中将使用的神经元数量。
num_layers-是我们要使用的神经元层数。显然,这两个值越大,训练时间就越长,但如果你正在训练一个复杂的代理,你可能需要额外的神经元,以提高精度。
增加成功绿色提示
我给界面上显示了两个时间,左边的是当前时间,右边的是最短吃到食物的时间,如果在一个合理范围内(允许比最短时间大greenrange(5秒)时长)plane就是绿色的,如果超出了最大时间一段范围就变成灰色。
最后的代码:
using System.Collections;
using System.Collections.Generic;
using UnityEngine;
using Unity.MLAgents;
using Unity.MLAgents.Actuators;
using Unity.MLAgents.Sensors;
public class FoodAgent : Agent
{
[SerializeField] FoodSwitch foodSwitch;
[SerializeField] FoodSpawn foodSpawn;
[SerializeField] Renderer plane;
[SerializeField] TextMesh text;
float moveSpd = 3f;
Rigidbody rig;
float btime;
float greentime = 1000f; //当前最快结束的
float usetime;//本次用时
const float greenrange = 5f; //比最快值长,也是绿色
private void Awake()
{
rig = GetComponent<Rigidbody>();
}
//当一段经历开始
public override void OnEpisodeBegin()
{
btime = Time.time;
transform.localPosition = new Vector3(Random.Range(-9f, 0f), 0f, Random.Range(-4f, 4f));
foodSwitch.transform.localPosition = new Vector3(Random.Range(3f, 9f), 0f, Random.Range(-4f, 4f));
foodSpawn.transform.localPosition = new Vector3(Random.Range(-9f, 0f), 5f, Random.Range(-4f, 4f));
foodSwitch.Clear();
Debug.Log("经历开始");
}
//通过传感器把坐标传入监视
public override void CollectObservations(VectorSensor sensor)
{
sensor.AddObservation(foodSwitch.isOn ? 1 : 0);
Vector3 dir = (foodSwitch.transform.localPosition - transform.localPosition).normalized;
sensor.AddObservation(dir.x);
sensor.AddObservation(dir.z);
sensor.AddObservation(foodSpawn.hasFood ? 1 : 0);
if (foodSpawn.hasFood)
{
Vector3 dirfood = (foodSpawn.GetFoodAt() - transform.localPosition).normalized;
sensor.AddObservation(dirfood.x);
sensor.AddObservation(dirfood.z);
}
else
{
sensor.AddObservation(0f);
sensor.AddObservation(0f);
}
//Debug.Log("Observations : " );
}
//行动接收
public override void OnActionReceived(ActionBuffers actions)
{
float moveX = actions.DiscreteActions[0];
float moveZ = actions.DiscreteActions[1];
bool switchon = actions.DiscreteActions[2] == 1;
//Debug.Log("OnAction : " + moveX+","+ moveZ + ","+ switchon);
Vector3 addforce = Vector3.zero;
switch (moveX)
{
case 0:
addforce.x = 0f; break;
case 1:
addforce.x = -1f; break;
case 2:
addforce.x = 1f; break;
}
switch (moveZ)
{
case 0:
addforce.z = 0f; break;
case 1:
addforce.z = -1f; break;
case 2:
addforce.z = 1f; break;
}
rig.velocity = addforce * moveSpd + new Vector3(0f, rig.velocity.y, 0f);
//transform.localPosition += new Vector3(moveX, 0f, moveZ) * Time.deltaTime * moveSpd;
//Debug.Log(rig.velocity+","+ addforce);
if (switchon)
{
Collider[] colls = Physics.OverlapBox(transform.position, Vector3.one * 0.5f);
for (int i = 0; i < colls.Length; i++)
{
if (colls[i].name.Equals("switch"))
{
if (!foodSwitch.isOn)
{
foodSwitch.Switch(true);
AddReward(1f);
Debug.Log("AddReward - switch");
}
}
}
}
AddReward(-1f / MaxStep);
}
//启发
public override void Heuristic(in ActionBuffers actionsOut)
{
ActionSegment<int> actions = actionsOut.DiscreteActions;
switch (Mathf.RoundToInt(Input.GetAxisRaw("Horizontal")))
{
case -1:
actions[0] = 1; break;
case 0:
actions[0] = 0; break;
case 1:
actions[0] = 2; break;
}
switch (Mathf.RoundToInt(Input.GetAxisRaw("Vertical")))
{
case -1:
actions[1] = 1; break;
case 0:
actions[1] = 0; break;
case 1:
actions[1] = 2; break;
}
actions[2] = Input.GetKey(KeyCode.E) ? 1 : 0;
}
private void OnCollisionEnter(Collision collision)
{
if (collision.collider.name.Equals("food"))
{
AddReward(1f);
Debug.Log("AddReward - food");
Destroy(collision.collider.gameObject);
foodSwitch.Switch(false);
//计算用时
float nowtime = Time.time;
usetime = nowtime - btime;
if (usetime < greentime)
{
greentime = usetime;
}
if (usetime - greenrange < greentime)
{
isgreen = true;
//如果比最短时间大一定数值还是允许是绿色的。
plane.material.color = Color.green;
}
EndEpisode();
}
}
bool isgreen;
private void Update()
{
usetime = Time.time - btime;
text.text = ((int)usetime).ToString()+"/" +((int)greentime).ToString();
if (isgreen)
{
//如果是绿色的,检测超时就改为灰色
if (usetime - greenrange > greentime)
{
//如果比最短时间大一定数值还是允许是绿色的。
plane.material.color = Color.gray;
isgreen = false;
}
}
}
}

上面的GIF是最终效果,开始很长一段时间agent都吃不到食物,甚至开关都找不到,一旦成功了,后面会越来越聪明了。调整yaml参数会让你的agent学习事半功倍。我们看到右边的数字基本都在3-5秒左右。
我们成功获得了AI文件后。

复制FoodAgent.onnx到项目里,并且挂到Model里,并设置InerenceOnly,我们看看训练的成果吧。

好了,本章的模仿学习就到这里了。
下一章我们可能会做一个更加复杂的机器学习的例子。
本章源码demo2
引用:
MLAgent
CodeMonkey
GameDev Academy