【Roofline 推理速度】影响深度学习模型推理速度的因素及相关基础知识
文章目录
- 1 问题分析
- 2 计算平台角度分析
-
- 2.1 算力 π
- 2.2 带宽 β \beta β
- 2.3 计算强度上限 I m a x I_{max} Imax
- 3 模型自身的性能评价指标
-
- 3.1 计算量与参数量
- 3.2 访存量
- 3.3 模型的计算强度 I I I
- 3.4 模型的理论性能 P P P
- 3.5 内存占用
- 4 Roof-line Model
-
- 4.1 用来解决什么问题
- 4.2 Roof-line是什么
-
- 4.2.1 带宽瓶颈区域 Memory-Bound
- 4.2.2 计算瓶颈区域 Compute-Bound
- 4.3 Roof-line Model对比分析VGG和mobilenet
- 5 计算/访存 密集型算子
- 6 模型推理时间
- 7 影响模型推理性能的其他因素
- 8 模型设计的建议
- 9 感谢链接
先行感谢 深度学习模型大小与模型推理速度的探讨 和 Roofline Model与深度学习模型的性能分析 两篇文章的作者,本文只是对这两篇文章进行了简单整合。
1 问题分析
不知道大家有没有以下这些疑问:
- 模型计算量和参数量明明不大,推理速度却不快?
- 深度可分离卷积训练竟然比常规卷积要慢?
- 英伟达的开发板号称自己什么卷积都支持的好,地平线的开发板号称对深度可分离卷积的支持力度最好,难道卷积方式在不同开发板上表现也会不同?
回答: 模型的推理速度主要看两个方面,一个是模型本身,另一个是模型在什么计算平台上跑(CPU/GPU/BPU/NPU),模型和计算平台的"默契程度"综合决定模型的实际表现(FPS)。例如最常见的:GPU对常规卷积加速更多,CPU对深度可分离卷积支持效果更好。
那“默契程度”又体现在什么地方呢?
常常听到的计算量、参数量、访存量、内存占用、ddr的访问带宽又和哪些因素有关系呢?
进入正题:Roofline Model 提出 Operational Intensity(计算强度)的概念,并给出模型在计算平台上所能达到理论计算性能上限公式。
2 计算平台角度分析
2.1 算力 π
计算平台的算力,又称为计算平台的性能上限,指的是:一个计算平台每秒钟最多能完成的浮点运算数。单位是 FLOPS or FLOP/s。
2.2 带宽 β \beta β
计算平台的带宽上限,指的是:一个计算平台每秒钟最多能完成的“内存”交换量。单位是Byte/s。
2.3 计算强度上限 I m a x I_{max} Imax
计算平台的计算强度上限指的是:计算平台上,单位“内存”交换 最多用来进行多少次计算,也就是用计算平台的算力除以计算平台的带宽。单位是FLOPs/Byte。
I m a x = π β I_{max} = \frac{\pi}{\beta} Imax=βπ
“内存”:CPU的内存、GPU的显存
3 模型自身的性能评价指标
3.1 计算量与参数量
计算量,又称为浮点运算量,表示网络前向传播时需要进行的加法操作和乘法操作的次数,也即模型的时间复杂度。单位是FLOPs。
参数量是指参数的个数。
深度卷积神经网络中绝大部分的计算量和参数量均集中在卷积层和全连接层。
卷积层的计算量为:
![]()
3.2 访存量
访存量是指输入一个样本,模型完成一次前向传播过程中所发生的内存交换总量,也即模型的空间复杂度。
访存量是指模型前向推理时所需访问存储单元的字节大小,反映了模型对存储单元带宽的需求。
在理想情况下(即不考虑片上缓存),模型的访存量就是模型各层权重参数的内存占用(Kernel Mem)与每层所输出的特征图的内存占用(Output Mem)之和。单位是Byte(或者 KB/MB/GB)。
由于数据类型通常为float32 ,因此需要乘以四。
卷积层的访存量为:
B c o n v = K 1 × K 2 × C i n × C o u t + H o u t × W o u t × C o u t B_{conv} = K_1 × K_2 × C_{in} × C_{out} + H_{out} × W_{out} × C_{out} Bconv=K1×K2×Cin×Cout+Hout×Wout×Cout
3.3 模型的计算强度 I I I
模型的计算强度,又称为计算访存比、计算密度:模型的计算量除以模型的访存量。表示模型在计算过程中,每Byte内存交换用于进行多少次浮点运算。单位是FLOPs/Byte。
I = F B I = \frac{F}{B} I=BF
模计算强度越大,其内存使用效率越高。
3.4 模型的理论性能 P P P
理论上,模型在计算平台上所能达到的每秒浮点运算次数。单位是 FLOPS or FLOP/s。使用Roof-line Model来衡量。
3.5 内存占用
内存占用是指模型运行时,所占用的内存/显存大小。一般需要关注的是最大内存占用。注意,内存占用 ≠ 访存量。
内存占用大小除了受模型本身影响外,还受软件实现的影响。
例如,有的框架为了保证推理速度,会将模型中每一个 Tensor 所需的内存都提前分配好,因此内存占用为网络所有 Tensor 大小的总和。更多的框架会提供 lite 内存模式,即动态为 Tensor 分配内存,以最大程度节省内存占用(当然可能会牺牲一部分性能)。
内存占用不会直接影响推理速度,往往算作访存量的一部分。但在同一平台上有多个任务并发的环境下,如推理服务器、车载平台、手机 APP,往往要求内存占用可控。可控一方面是指内存/显存占用量,如果占用太多,其他任务就无法在平台上运行;另一方面是指内存/显存的占用量不会大幅波动,影响其他任务的可用性。
4 Roof-line Model
4.1 用来解决什么问题
模型在一个计算平台的限制下,到底能达到多快的浮点计算速度。
具体来说:Roof-line Model模型解决的是:计算量为A且访存量为B的模型在算力为C且带宽为D的计算平台所能达到的理论性能上限E是多少的问题。
4.2 Roof-line是什么
Roof-line,指的是由计算平台的算力和带宽上限这两个参数所决定的“屋顶”形态,如下图所示。
- 算力决定“屋顶”的高度(绿色线段)
- 带宽决定“房檐”的斜率(红色线段)


图中展现出两个瓶颈区域:
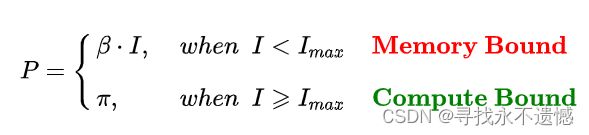
4.2.1 带宽瓶颈区域 Memory-Bound
当模型的计算强度 I I I小于计算平台的计算强度上限 I m a x I_{max} Imax 时,此时模型位于“房檐”区间,模型理论性能 P P P的大小完全由计算平台的带宽上限 β \beta β(房檐的斜率)以及模型自身的计算强度 I I I所决定。
这时候就称模型处于 Memory-Bound 状态。
在模型处于带宽瓶颈区间的前提下,计算平台的带宽 β \beta β越大(斜率越大,房檐越陡),或者模型的计算强度 I I I越大,模型的理论性能 P P P可呈线性增长。
4.2.2 计算瓶颈区域 Compute-Bound
不管模型的计算强度 I I I 有多大,它的理论性能 P P P最大只能等于计算平台的算力 π \pi π。
当模型的计算强度 I I I 大于计算平台的计算强度上限 I m a x I_{max} Imax 时,模型在当前计算平台处于 Compute-Bound状态,即模型的理论性能 P P P 受到计算平台算力 π \pi π 的限制,无法与计算强度 I I I 成正比。
这并不是一件坏事,因为此时,模型已经充分利用了计算平台的全部算力。
可见,计算平台的算力 π \pi π 越高,模型进入计算瓶颈区域后的理论性能 P P P 也就越大。
4.3 Roof-line Model对比分析VGG和mobilenet
- VGG
VGG计算强度 I v g g I_{vgg} Ivgg很大,以VGG-16为例,一次前向传播的计算量达到 15 GFLOPs,如果包含反向传播,则需要再乘二。
访存量是 Kernel Memory 和 Output Memory 之和再乘以四,大约是 600MB。因此 VGG16 的计算强度就是 25 FLOPs/Byte。
- mobilenet
MobileNet 由于使用了深度可分离卷积,其计算量约为 0.5 GFLOPs(VGG16 则是 15 GFLOPs),其访存量只有 74 MB(VGG16 则是约 600 MB)。
但是,由于计算量和访存量都下降了,而且相比之下计算量下降的更厉害,因此 MobileNet 的计算强度只有 7 FLOPs/Byte。
- 总结
MobileNet 更适合运行在嵌入式平台之上。
嵌入式平台本身的计算强度上限就很低,可能比 MobileNet 的计算强度还要小,因此 MobileNet 运行在这类计算平台上时,它可能就不再位于 Memory-Bound 区域,而是进入了 Compute-Bound 区域。
此时 MobileNet 和 VGG16 一样可以充分利用计算平台的算力,自身的计算量与内存消耗又都更小,自然“占便宜”。
5 计算/访存 密集型算子
网络中的算子可以根据计算密度进行分类。一般而言,
Conv、FC、Deconv 算子属于计算密集型算子;
ReLU、EltWise Add(Elementwise:逐元素)、Concat(合并) 等属于访存密集型算子。
同一个算子也会因参数的不同而导致计算密度变化,甚至改变性质。
比如在其他参数不变的前提下,增大 Conv 的 group,或者减小 Conv 的 input channel 都会减小计算密度。
算子的计算密度越大,越有可能提升硬件的计算效率,充分发挥硬件性能。
注意: 不同的硬件平台峰值算力和内存带宽不同,导致同一个模型在平台 1 上可能是计算密集的,在平台 2 上可能就变成了访存密集的。
6 模型推理时间
按照 RoofLine 模型,算子实际的执行时间如下:

对于访存密集型算子,推理时间跟访存量呈线性关系;
对于计算密集型算子,推理时间跟计算量呈线性关系。
全局上,计算量和推理时间并非具有线性关系。
计算量并不能单独用来评估模型的推理时间,还必须结合硬件特性(算力&带宽),以及访存量来进行综合评估。
7 影响模型推理性能的其他因素
RoofLine 模型可以用来评估程序的性能上界,但是实际能达到的性能还会受到硬件限制、系统环境、软件实现等诸多因素的影响,距离性能上界有一定距离。
更多内容,欢迎查看原文:深度学习模型大小与模型推理速度的探讨
8 模型设计的建议
- 了解目标硬件的峰值算力和内存带宽,最好是实测值,用于指导网络设计和算子参数选择。
- 明确测试环境和实际部署环境的差异,最好能够在实际部署环境下测试性能,或者在测试环境下模拟实际部署环境。
- 针对不同的硬件平台,可以设计不同计算密度的网络,以在各个平台上充分发挥硬件计算能力(虽然工作量可能会翻好几倍)
- 除了使用计算量来表示/对比模型大小外,建议引入访存量、特定平台执行时间,来综合反映模型大小。
==========================================================================================
- 对于低算力平台(CPU、低端 GPU 等),模型很容易受限于硬件计算能力,因此可以采用计算量低的网络来降低推理时间。
- 对于高算力平台(GPU、DSP 等),一味降低计算量来降低推理时间就并不可取了,往往更需要关注访存量。单纯降低计算量,很容易导致网络落到硬件的访存密集区,导致推理时间与计算量不成线性关系,反而跟访存量呈强相关(而这类硬件往往内存弱于计算)。相对于低计算密度网络而言,高计算密度网络有可能因为硬件效率更高,耗时不变乃至于更短。
- 面向推理性能设计网络结构时,尽量采用经典结构,大部分框架会对这类结构进行图优化,能够有效减少计算量与访存量。例如 Conv->BN->ReLU 就会融合成一个算子,但 Conv->ReLU->BN 就无法直接融合 BN 层。
- 算子的参数尽量使用常用配置,如 Conv 尽量使用 3x3_s1/s2、1x1_s1/s2 等,软件会对这些特殊参数做特殊优化。
- CNN 网络 channel 数尽量选择 8 的倍数,很多框架的很多算子实现在这样的 channel 数下效果更好(具体用多少不同平台不同框架不太一样)。
- 框架除了计算耗时外,也处理网络拓扑、内存池、线程池等开销,这些开销跟网络层数成正比。因此相比于“大而浅”的网络,“小而深”的网络这部分开销更大。一般情况下这部分开销占比不大。但在网络算子非常碎、层数非常多的时候,这部分开销有可能会影响多线程的扩展性,乃至于成为不可忽视的耗时因素。
9 感谢链接
再次感谢两位大佬!
https://zhuanlan.zhihu.com/p/411522457
https://zhuanlan.zhihu.com/p/34204282