Hierarchical Roofline Performance Analysis for Deep Learning Applications
Roofline 模型是劳伦斯伯克利国家实验室在2008年提出的一个性能模型,后续很多工作亦出自该实验室。考虑到分层 Roofline 这一概念已在先前的 Hierarchical Roofline analysis for GPUs: Accelerating performance optimization for the NERSC-9 Perlmutter system 和 Hierarchical Roofline Analysis: How to Collect Data using Performance Tools on Intel CPUs and NVIDIA GPUs 中提出,这篇文章主要是将其应用到了深度学习领域。
而在 NVIDIA GPU 上进行分层 Roofline 分析所依赖的两大工具分别为:
- Empirical Roofline Toolkit (ERT) 测试体系结构指标,用于机器表征;
- Nsight Compute 收集度量值,进行应用程序表征。
Introduction
Roofline 模型是一个直观的性能模型,可以提供有关应用程序性能、性能瓶颈和可能的优化机会的有价值见解。近年来,它提取关键计算特征并抽象出现代计算机体系结构复杂性的能力在传统高性能计算 (HPC) 和机器学习中广受欢迎。
Roofline 是一个面向吞吐量的模型,以计算能力、内存带宽和数据局部性的相互作用为中心。数据局部性表示为算术强度(AI),即数据从内存加载后的重用率,通常计算为执行浮点运算与数据移动的比率,即每个字节的 FLOP。持续性能 (GFLOP/s) 受两个方面的约束:
GFLOP/s ≤ min { Peak GFLOP/s Peak GB/s × Arithmetic Intensity \text{GFLOP/s} \leq \text{min}\begin{cases} \text{Peak GFLOP/s} \\ \text{Peak GB/s} \times \text{Arithmetic Intensity} \end{cases} GFLOP/s≤min{Peak GFLOP/sPeak GB/s×Arithmetic Intensity
Roofline 模型通常只关注内存层次结构中的一个级别,但近年来已扩展到完整内存系统,以帮助理解缓存复用和数据局部性,并提供对代码性能的更多见解。
为了促进 Roofline 研究,许多工具和工作流程如雨后春笋般涌现,例如,劳伦斯伯克利国家实验室开发的 Empirical Roofline Toolkit (ERT),用于更准确的机器表征,以及其他工具 、方法和工作流,用于更简化的应用程序性能数据收集:Roofline Performance Model、Toward Automated Application Profiling on Cray Systems、Timemory、Hierarchical Roofline analysis for GPUs。
在传统 HPC [8]、[9]、[Hierarchical Roofline analysis for GPUs]、[10]、[11]、[8 Steps to 3.7 TFLOP/s on NVIDIA V100 GPU]和机器学习 [Hierarchical Roofline analysis for GPUs]、[Performance analysis of deep learning workloads using roofline trajectories]、[Time-Based Roofline for Deep Learning Performance Analysis] 中,也对屋顶线的应用进行了一系列研究,以及将该模型扩展和细化到其他相关主题,如指令屋顶线、基于时间的屋顶线,屋顶线缩放轨迹、基于屋顶线的性能可移植性分析,以及能量和能源屋顶线。
Methodologies
在这一部分中,我们将讨论在 Empirical Roofline Toolkit (ERT) 上所做的扩展工作,以支持 NVIDIA GPU 上的多种数据精度(例如 FP16)和 Tensor Core 操作,以及在 Nsight Compute 中可用于衡量应用程序性能的指标集,如运行时间、持续吞吐量和内存层次结构中不同级别的数据移动。在 NVIDIA GPU 上进行分层 Roofline 分析过程中,这两个组件共同构成了收集用于机器和应用程序表征的完整数据的方法。
ERT Extensions for Machine Characterization
劳伦斯伯克利国家实验室开发并维护了 Empirical Roofline Toolkit (ERT)。它由经过微调的微内核组成,用于测试计算机体系结构的各个方面,如内存带宽和计算吞吐量。通过与供应商的理论值或营销数字进行比较,可以更准确地理解该架构在实际功率、热约束和编程模型的编程环境中的性能。
ERT 本质上是一个 Python 脚本,它包裹一系列用 C++ 编写的微内核,并在不同体系结构上利用各种编程模型并行化。
例如,Intel CPU 上使用 OpenMP 和 MPI,NVIDIA GPU 上使用 CUDA,目前正在添加更多的微内核来支持 AMD 架构、IBM Power 处理器和 Intel GPU。这些微内核经过专门调整,以测试体系结构的不同方面,并为其上的实际应用程序提供上限,也就是说,如果这些内核无法达到一定的性能,那么现实生活中的大型复杂应用程序几乎没有希望实现这一目标。

为了捕获实际的最大带宽和最大浮点运算( floating-point operation,FLOP )速率,ERT 通过改变内核数据大小和每个内核中涉及的 FLOP 数量来运行一系列计算内核。它从可以放入 L1 缓存的少量数据开始,逐渐将数据大小增加到某个上限。这个上限大小应该至少大于最后一级缓存,以保证数据在板上内存层次结构的所有级别上移动。ERT 将 1 GB 设置为所有平台的默认上限。自然地,带宽峰值通常从每个内存加载和存储具有最小(一个) FLOP 的内核获得。相反,浮点峰值是在现代体系结构上充分利用 SIMD 或 SIMT 的结果。例如,在 AVX2 架构上,每个内存操作至少需要 2 个 FLOP 才能获得潜在的双精度峰值。需要注意的是,ERT 中的数据处理是针对每个目标体系结构精心设计的,例如,需要调整处理参数以获得正确的内存层次结构信息。为所有情况建立一个完美且准确的表征模型的想法是不现实的。
本文之前的 ERT 只支持双精度(FP64)的性能表征,在本节中,我们将详细介绍如何将其扩展到支持单精度(FP32),半精度(FP16)以及 NVIDIA GPU 上的 Tensor Core 操作。合成的 Roofline 天花板如图 1 所示,在 V100 GPU 上,FP64为7.7 TFLOP/s,FP32为15.2 TFLOP/s,CUDA 核上 FP16为29.2 TFLOP/s,Tensor 核上为103.7 TFLOP/s。
Single-Precision (FP32) and Half-Precision (FP16)
原始 ERT 是用 C 编写的,只支持双精度(FP64)测量。虽然通过在代码中用“单”替换“双”可以很容易地扩展到单精度(FP32),但需要工作来支持半精度(FP16)。出于可维护性和未来可扩展性的目的,我们用 C++ 重写了 ERT,并利用 C+ +模板来支持多种数据类型。

对于FP32,我们很容易得到15.2 TFLOP/s 的峰值性能,与宣传的 15.7 TFLOP/s 性能相差不到5%。
对于 FP16(在 CUDA Core 上),需要进行一些性能调整,详见表 Tab. I。简单的实现(v1) 只是将 h a l f half half 作为数据类型传递给模板化函数,这导致了与 FP32精度相似的性能,15.4 TFLOP/s。这是因为 V100 GPU 架构没有对 FP16 操作的硬件支持。每个 V100 流式多处理器(streaming multiprocessor,SM)包含 64 个 FP32 内核和 32 个 FP64 内核,但不包含 FP16 内核。通过使用标量 h a l f half half 数据类型,我们实际上只使用了 FP32 内核的一半来执行计算。为了高效地执行 FP16操作(即使使用 Tensor Core 也是一个不错的选择),在 CUDA Core 上,可以使用向量类型 h a l f 2 half2 half2 将两个 FP16值打包在一个 FP32寄存器中,并在一个 FP32指令中执行。在 ERT 中,我们使用内蕴函数实现了这一点,并在表 Tab. I 中获得了 20.1 TFLOP/s (v2)的改进性能。在现实生活中,以内蕴函数实现大规模应用程序是不可行的,但从实现上看,是为了尽可能地提高 Roofline 的上限。
表 Tab 1 中的其余三个版本 v3-v5 是一系列优化,这些优化已被证明有利于 ERT 的开发,并且有望在很大程度上有助于实际应用程序及其性能调整。在这三者中,用 u i n t 32 _ t {uint32\_t} uint32_t 数据类型替换 u i n t 64 _ t {uint64\_t} uint64_t 索引变量被证明可以带来最大的性能提升,从 20.1~TFLOP/s 到 28.2~TFLOP/s。这是由于 V100仅在硬件级别支持 INT32整数操作,并且对于第二个版本的 ERT(v2), u i n t 64 _ t {uint64\_t} uint64_t 和 u i n t 32 _ t {uint32\_t} uint32_t 之间存在常量类型转换。一个合理的猜测是 u i n t 64 _ t {uint64\_t} uint64_t 通过 FP64管道处理昂贵的运行时类型转换,而每个 SM 的 INT32 内核数量是 FP64 内核的两倍。
v4 中内联中间变量,v5 中将所有整数转换到 u i n t 32 _ t {uint32\_t} uint32_t,最终 ERT 的 FP16 CUDA Core性能达到了29.2 TFLOP/s,与理论峰值相当,如图 Fig. 1。
Tensor Core
NVIDIA Tensor Core 旨在加速矩阵-矩阵乘法运算,这代表了许多深度学习工作负载的数学性质,例如卷积神经网络(CNN)。
它们对 4 × 4 4\times4 4×4 矩阵进行操作,可以极其高效地执行下面的矩阵乘法和累加。
D = A × B + C D = A\times B + C D=A×B+C
其中 A A A 和 B B B 是 FP16类型的矩阵, C C C 和 D D D 是 FP16或 FP32矩阵。V100具有80个 SM 和8个张量核,在1.312 GHz 时钟频率下,其理论张量核峰值可以计算为
80 × 8 × 1.312 × 4 3 × 2 = 107.479 TFLOP/s 80\times 8\times 1.312\times 4^{3}\times 2 = 107.479 \textrm{~TFLOP/s} 80×8×1.312×43×2=107.479 TFLOP/s
为了对 V100 上的 Tensor Core 进行压力测试,我们实现了基于通用矩阵-矩阵乘法 (GEMM) 的 ERT,其中 α \alpha α 和 β \beta β 是常数系数: D = α ∗ A × B + β ∗ C D = \alpha * A\times B + \beta * C D=α∗A×B+β∗C
通常,在 Tensor Core 上编程一般有两种方式,使用 CUDA 中的 WMMA (Warp Matrix Multiply Accumulate) API ,或者 cuBLAS、cuDNN 等库。CUDA 中的nvcuda::wmma命名空间提供专用的矩阵加载、乘法、累加和存储操作,并允许在 Tensor Cores 上直接编程。另一方面,cuBLAS 和 cuDNN 库使用户远离低级 CUDA 编程,并为 GEMM 和其他操作提供了非常通用、高度优化的高级用户 API。
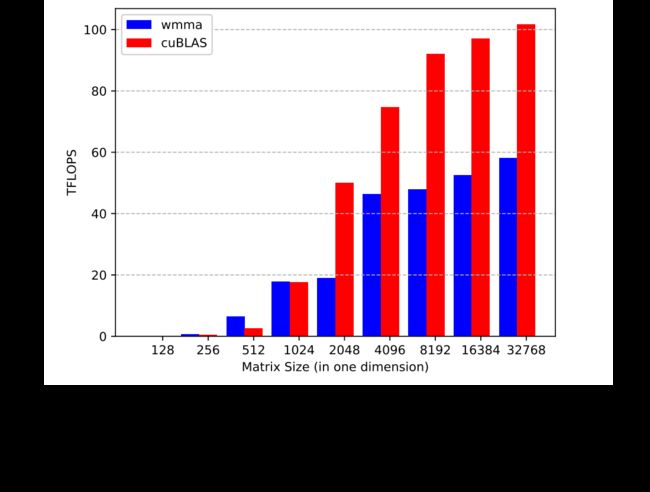
对于等式4中给定的 GEMM,假设 A A A 矩阵大小为 M × N M \times N M×N, B B B 为 N × K N\times K N×K, C C C 和 D D D 为 M × K M\times K M×K,若 M = N = K M=N=K M=N=K,则在该内核中执行的 FLOP 总数可计算为 M 3 × 2 M^{3}\times 2 M3×2。这是一个不包含常数效率乘法的估计,这些乘法通常在 CUDA 核心上执行,而不是在 Tensor 核心上执行,并且可以忽略不计。使用运行时 t t t,那么对于图 Fig. 2中给定的矩阵大小,可以估计内核的 FLOP/s 性能为 ( M 3 × 2 ) / t (M^{3}\times 2)/t (M3×2)/t。
显然,随着矩阵规模的增大,WMMA 和 cuBLAS 方法的性能也会增加。在最大值为 M = N = K = 32768 M=N=K=32768 M=N=K=32768 时,我们从 cuBLAS 方法得到了理论峰值的96.5%处的103.7 TFLOP/s,以及 WMMA 方法的58 TFLOP/s,理论峰值的54%。这主要是由于 cuBLAS 中的优化,例如共享内存的使用、数据填充(以避免共享内存中的 bank 冲突)、高度调优的线程块大小、分片大小和其他参数。
对于本文的其余部分,我们将使用103.7 TFLOP/s 作为 Tensor Core 峰值;然而,58 TFLOP/s 的性能为在 Tensor Core 上使用 WMMA 编程的用户提供了一个经验上界。
Nsight Compute Metrics for Application Characterization
随着开发人员工具链的变化,在 NVIDIA GPU 上进行 Roofline 分析的应用程序表征方法也在不断发展。Hierarchical Roofline analysis for GPUs 第一个提出基于 nvprof 的方法,然后在 roofline-on-nvidia-gpus 中开发了基于 Nsight Compute 的方法,并在 Hierarchical Roofline Analysis 中简要介绍。在本文中,我们将详细讨论 Nsight Compute 度量如何用于 NVIDIA GPU 上的层次 Roofline 分析,并演示其在分析深度学习应用程序方面的有效性。
Nsight 分析工具包正在取代 nvprof 成为 NVIDIA GPU 开发人员新的性能工具套件。它由 Nsight Systems、Nsight Compute 和 Nsight Graphics 三个组件组成,其中前两个与科学应用程序和机器学习应用程序开发最相关。 Nsight Systems 可以提供系统层面的应用性能可视化,并帮助用户识别诸如 GPU上 的并行度不足、不必要的设备-主机数据传输和低效的内核同步等问题,而 Nsight Compute 则更为深入,并允许收集更详细的性能指标,如 warp 发射统计、指令管道利用率和内存访问模式。
在两代开发者工具之间,nvprof 和 Nsight Compute 有一些主要区别。
- nvprof 使用 CUPTI,而 Nsight Compute 基于 PerfWorks,后者是一个新的性能指标收集框架。
- Nsight Compute 中的度量比 nvprof 中的度量更加细微,Nsight Compute 将一些指标分解为多个子项。
- Nsight Compute 中的命名和组织约定也更结构化,使用诸如单元、子单元、接口、计数器名称、汇总度量和子度量等组件来区分不同的度量。
- Nsight Compute 对收集多个度量时使用的内核重放以及分析开销进行了更优化,以提供更快、更准确的硬件和软件计数器测量。
要在 NVIDIA GPU 上构建分层 Roofline,需要收集以下数据:内核运行时间、每个内核执行的 FLOP 总数以及在内存层次结构的每个层次上读取和写入的字节数。通过 Nsight Compute,我们可以使用以下命令收集表 Tab. II 中列出的度量。
nv-nsight-cu-cli --metrics metric ./application
Kernel Run Time
如 TABLE II 所示,我们利用度量sm_cycle_elapsed.avg得到经过的cycles总数及其子度量per_second来获得rate(每秒周期数),以此计算内核执行时间:
t i m e = c y c l e s r a t e \mathrm{time} = \frac{\mathrm{cycles}}{\mathrm{rate}} time=ratecycles
FLOPs
在统计内核中执行的 FLOP 数量时,Nsight Compute 没有像 nvprof 中的flop_count_dp那样提供统一的度量。而是对于每种浮点精度(FP64、FP32和 FP16),根据指令类型:加法、乘法和融合乘加(FMA)将测量分成三个度量。注意每个 FMA 被认为是两个 FLOP,对于每个数据精度,FLOP总数可计算为 a d d + 2 × f m a + m u l \mathrm{add} + 2\times \mathrm{fma} + \mathrm{mul} add+2×fma+mul。此外,从度量的命名可以看出,这些 FLOP 中只计算非谓词线程,即不包括掩码操作。
对于 Tensor Core,我们使用sm__inst_executed_pipe_tensor.sum指标来计算 warp 指令的数量,并且 Tensor Core FLOPs 总数为
F L O P t c = I n s t t c × 512 \mathrm{FLOP_{tc}} = \mathrm{Inst_{tc}}\times 512 FLOPtc=Insttc×512
Bytes
表 TABLE II 中列出了用于测量内存层次结构每个级别上的数据移动的指标。

对于设备内存(或 HBM)、L2缓存和 L1缓存,最新的 Nsight Compute 为它们提供了统一的字节度量,以方便测量。请注意,当前 L1指标中不包括共享内存事务。
由于分析开销,建议限制一次运行 Nsight Compute 的内核数量,并且只要应用程序的执行是确定的,这些度量也可以在单独的运行中收集。
另请注意,从 2020.1.0 开始,Nsight Compute 将多流执行串行化,因此可能会忽略由于内核重叠导致的某些性能提升;然而,本文的性能分析在理解内核级的应用性能方面仍然具有洞察力。
Experimental Setup
Hardware and Software Configuration
本文的结果是从美国劳伦斯·伯克利国家实验室(LBNL)国家能源研究科学计算中心(NERSC)的 Cori 超级计算机,特别是其 GPU 分区得到的。GPU 分区主要用于 NERSC 百亿亿级科学应用程序 (Exascale Science Application Program,NESAP) 中的 GPU 移植、基准测试和测试工作。每个节点包含两个 Intel Xeon Gold 6148 Skylake CPU、384GiB DDR4 内存和 8 个 NVIDIA V100 GPU。每个 GPU 具有 16GiB 的 HBM2 内存和 80 个 SM,节点上的 GPU 以“混合立方体网格”拓扑相互连接。
在软件方面,我们使用了 climate-seg-benchmark 的 TensorFlow 1和 PyTorch 实现,以及 CUDA 10.2.89、cuDNN 7.6.5、Nsight Compute 2020.1.0、Python 3.7、PyTorch 1.5.0和 TensorFlow 1.15.0 用于本研究。
DeepCAM Benchmark
DeepCAM 是从2018年戈登·贝尔获奖项目 Exascale Deep Learning for Climate Analytics 中提取的深度学习基准,用于气候图像中极端天气模式的检测、分类和定位。它有 TensorFlow 和 PyTorch 两种不同的实现,PyTorch 版本被选为 MLPerf HPC 基准测试套件。本文将使用上一章节中所介绍的方法来比较这两种实现的性能。为了确保公平的比较,我们已将参数调整为尽可能接近,例如,编码器-解码器结构中的层数、层参数、优化算法、步速、批量大小、批范数的使用以及自动混合精度(Automatic Mixed Precision,AMP)设置。
DeepCAM 模型是一种用于语义分割的深度神经网络,具有基于 DeepLabv3+ 的编码器-解码器架构。 编码器是一个具有多孔空间金字塔池化的 ResNet-50 网络。 解码器是一个九层网络,具有卷积层和反卷积层,以及来自编码器输入和中间的两个跳跃连接。
为了分析代码,在 Nsight Compute 中禁用了profile-from-start选项,并使用 CuPy 显式地限制分析区域仅包括迭代循环。为了在分析期间具有相对稳定的运行时行为,我们还在目标分析循环之前设置了一个具有 5 次迭代的预热循环。在每次执行过程中,我们只收集一个度量,以最小化分析开销,开销变化可能由于 TensorFlow 运行时自动调优而导致随机算法选择。为了解决这个问题,使用 NVIDIA TensorFlow Determinism 来消除这种不确定性。
如果未另行说明,TensorFlow DeepCAM 实现的默认设置为启用 AMP,而 PyTorch DeepCAM 的 AMP 优化级别为O1。
源代码和完整的原始结果可在 DeepCAM 获得。
Results
在本节中,我们将首先在 DeepCAM 基准测试中应用 Nsight Compute 方法,并讨论其性能影响。在下面的 Roofline 图表中,每个内核由三个空心圆圈表示( 蓝色代表 L1 ,红色代表 L2 ,绿色代表 HBM),并且圆的大小与内核的运行时间成正比。请注意,我们预设了最小圆圈大小,以使所有内核在图上可见,因此大内核和小内核之间的实际运行时间差可能会更为明显。此外,同一个内核可能有很多次调用,这些 Roofline 图表上显示的数据是同一个内核的所有这些调用的总计。应该期望分别在 L1、L2和 HBM 天花板附近出现蓝色、红色和绿色圆圈,以显示高内存利用率。彼此靠近的圆圈三元组表示“流式”数据访问模式,并指示缓存位置不佳。右上角的圆显示出优于其他圆的性能。
在接下来的章节中,我们将讨论在 TensorFlow 和 PyTorch 实现中,前向和后向传递方式的性能差异,以及 NVIDIA Automatic Mixed Precision 包和 zero-AI 内核对性能的影响。注意,TensorFlow DeepCAM 的后向传递包含梯度计算和梯度更新,而 PyTorch DeepCAM 的后向传递只包含梯度计算(其“optimizer”是梯度更新步骤)。
The TensorFlow version of DeepCAM
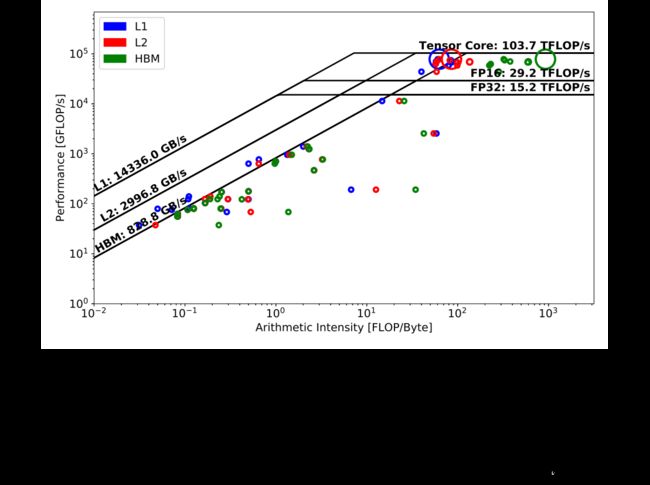
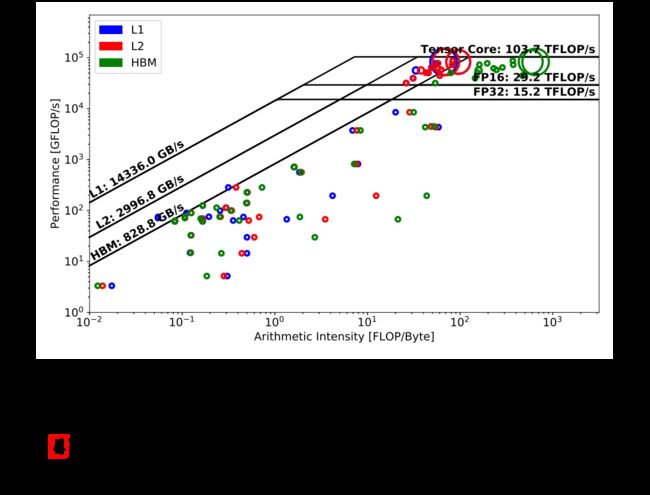
图 Fig. 3 显示了 TensorFlow 版本的 DeepCAM 在其前向传递中的分层 Roofline。Tensor Core 天花板下的三个大圆圈代表的主要计算内核表明它具有非常高的 Tensor Core 利用率,而余下众多圆圈要么不使用 Tensor Core,要么受带宽限制。
这个主要内核的 L1圆圈(蓝色)与其 L2圆圈(红色)略微重叠,表明 L1缓存局部性相对较低;然而,它的 L2和 HBM 圈之间的巨大差距表明 L2 缓存未命中很少发生,并且内核受益于高 L2数据局部性。至于其余的内核,它们的 L1、L2 和 HBM 内核通常彼此接近,这意味着所有级别的内存层次结构的数据局部性都很差(“流式”操作)。

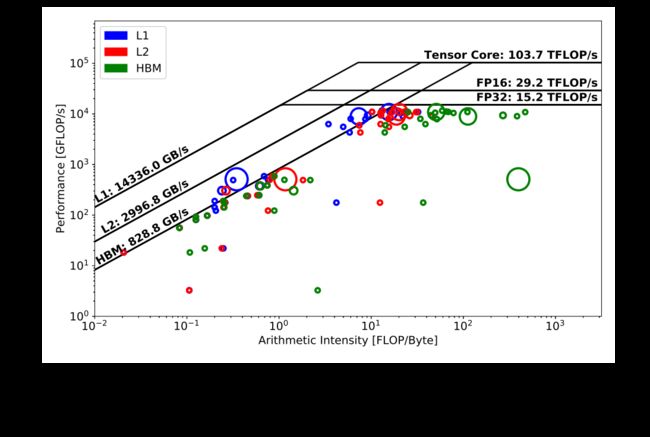
图 Fig. 4显示了 TensorFlow DeepCAM 的相应反向传递。在反向传递计算中没有像前向传递那样出现一个单一的主要内核,而是存在两个非常耗时的内核。显然,这两个内核都需要比前向传递中的主内核更长的运行时间(注意大小),这意味着后向传递比前向传递具有更多的计算密集型核,并且通常更耗时。与在前向传递中少数使用 Tensor Core 的内核相比,我们可以发现更多内核在后向传递中从 Tensor Core 管道中受益,因为它们位于半精度峰值之上。另一个观察结果是,与前向传递相比,后向传递涉及更多的内核调用。总体而言,我们可以得出结论,无论是前向传播还是后向传播,主要计算内核都是计算密集型的,并且针对底层架构进行了高度优化。
The PyTorch version of DeepCAM
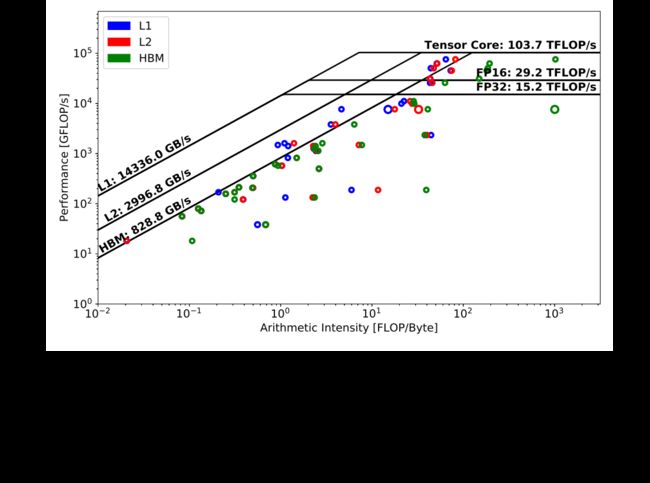
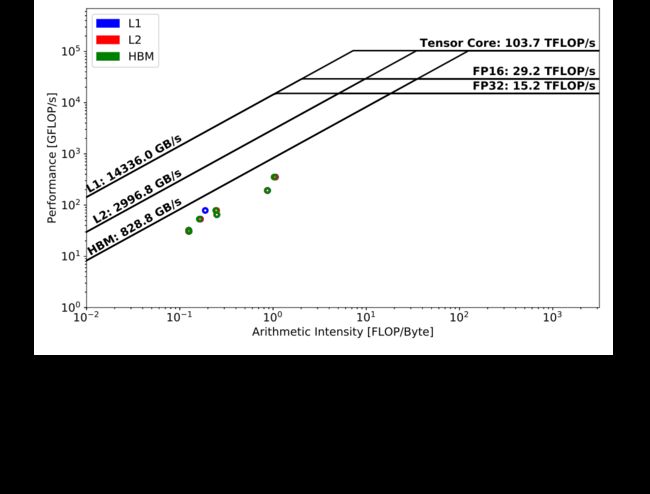
与 TensorFlow 结果(图 Fig. 3)相比,在 PyTorch 前向传递(图 Fig. 5)中没有发现占主导地位的内核(内核运行时间明显大于其他内核)。排名第一的内核略低于单精度性能峰值,并且基于不同内存层次结构之间的符号距离,它比 TensorFlow 中的主导内核具有更好的缓存利用率(即使它运行在 CUDA Core 上)。此外,与 TensorFlow 类似,在 DeepCAM 的 PyTorch 实现中,大量琐碎的内核瓶颈是 HBM。
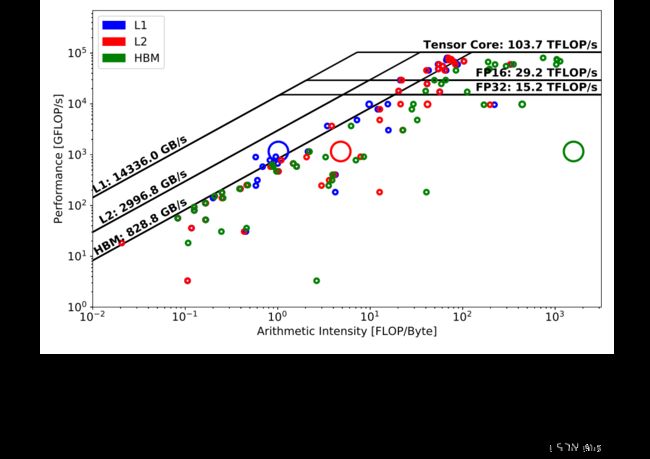
图 Fig. 6显示了默认配置下 PyTorch DeepCAM 在反向传播中的性能。令人惊讶的是,最耗时的内核没有使用 Tensor Core,仅提供大约 1 TFLOP/s 的性能。 然而,从圆圈的大小来看,这个实现的整体运行时间仍然低于 TensorFlow 案例,这要归功于其他内核或内核整体执行中的优化。
与 TensorFlow 相比,PyTorch 在分析模型时具有更大的灵活性,并且“optimizer”步骤可以很容易地与反向传播中的梯度计算步骤分开。优化步骤主要是用新计算的梯度更新模型参数,通常算术强度较低。
图 Fig. 7证实了这一点,其中所有的“optimizer”内核都受内存限制,并且具有比图 Fig. 5或图 Fig. 6中的一些内核更低的 FLOP/s 性能。需要注意的是,在这个过程中涉及到2709次内核调用,尽管只有几个圈是可见的。这些内核调用具有非常相似的算术强度和性能,因此是重叠的。
Automatic Mixed Precision
NVIDIA 开发的自动混合精度 (Automatic Mixed Precision,AMP) 包致力于通过将部分单精度数据转换为半精度数据来减少数据移动并提高计算吞吐量,从而加速深度学习过程。它支持某些模型参数的自动类型转换,还实现了诸如损失缩放等方案,以确保数值的正确性和准确性。通过手动挑选合适的变量并显式对它们进行类型转换,我们在 TensorFlow 中手动实现了一个 FP16 版本的 DeepCAM。图 Fig. 8表明,该实现的反向传递性能非常接近启用 AMP 的 FP32 DeepCAM(如图 Fig. 4所示),证明 AMP 包无需了解网络细节就能有效地应用类型转换并利用低精度操作来提高性能。
AMP 为 TensorFlow 和 PyTorch 提供了实现,对于 PyTorch,有更详细的优化级别,而不仅仅是开启或关闭。 根据 AMP 文档,PyTorch 的O0级别用于建立自动混合精度加速的稳定基线;O1遵循保守的类型转换,并且高度保留数值属性;而02实现了更积极的 FP32 到 FP16 转换,需要特别注意模型收敛问题。
我们的默认设置是O1,PyTorch DeepCAM 在此设置下的反向传递性能显示在图 Fig. 6中。从图 Fig. 9中的O0优化级别,到图 Fig. 6中的O1,内核运行时间大大减少,许多内核已转移到 Tensor Core 上执行,提供了更高的计算吞吐量并证明了O1优化级别的有效性。
Zero-AI kernels
传统的 HPC 应用中用户通常完全控制内核调用,而基于 Python 的高级深度学习框架往往会隐式地调用许多辅助内核,用于数据转换或设备-主机的转移。表 TABLE III 显示了这些内核调用占调用总数的比例。大约 40-50% 的调用是针对此类零 AI 内核的,其中不执行浮点运算。如果这些内核与其他内核执行完全重叠,这可能不会在不经意间影响总体性能,但在现实中很难做到这一点。随着硬件的不断发展,新的计算机架构倾向于提供越来越高的 FLOP/s 性能和带宽,但内核启动开销的渐进式改进较少。为避免成为开销限制,建议这些深度学习应用程序通过与非零 AI 内核融合或重叠来尽可能避免此类“隐式”零 AI 内核。

Overall Performance
尽管在实现上存在细微差别(即使我们试图进行逐个比较),TensorFlow DeepCAM 和 PyTorch DeepCAM 这两种代码实现了相似的运行时间和收敛性能。 前几小节在分层 Roofline 上对这两种实现进行了深入分析,发现与 PyTorch 相比,TensorFlow 更倾向于使用 Tensor Core,如图 Fig. 3-6中最耗时内核的位置所示。这两个框架在 L1、L2和 HBM 级别上具有相似的缓存使用模式,PyTorch 具有稍多的高 AI 内核,分布在图 Fig. 5和 Fig. 6上的 100 FLOPs/Byte 和 1000 FLOPs/Byte 范围内。
总体而言,TensorFlow DeepCAM 和 PyTorch DeepCAM 中启动的内核数量相似,TensorFlow 使用的零 AI 内核数量是 PyTorch 的两倍以上,表 Tab. III 中分别为2137个和1046个。这些零 AI 内核可能已经在多个流上启动并与计算内核重叠,但是,减少它们可以进一步改善启动开销和整体运行时间。这些内核主要用于将数据从一种精度转换为另一种精度,或用于重排数据布局。它们可以融合或在主机上完成(与 GPU 计算异步)以节省运行时间。
另一个需要注意的是,NVIDIA AMP 包已被证明是非常有效的,通过对比 TensorFlow 的图 Fig. 4和 Fig. 8,以及 PyTorch 的图 Fig. 6和 Fig. 9。
参考资料:
- CS Roofline Toolkit
- Hierarchical Roofline Analysis on GPUs
- Performance Analysis with Roofline on GPUs
- Performance Analysis of GPU-Accelerated Applications using the Roofline Model
- Short Introduction to the Roofline Model
- GTC Silicon Valley-2019 ID:S9624,Performance Analysis of GPU-Accelerated Applications using the Roofline Model
- 自然科学类论文中出现的「regime」是什么意思?
- Amdahl 定律
- NERSC/Roofline-on-NVIDIA-GPUs
- 斯坦福CS217(六)Roof-line和TPU性能
- A Systematic Methodology for Analysis of Deep Learning Hardware and Software Platforms
- Benchmarking TPU, GPU, and CPU Platforms for Deep Learning
- 论文阅读:cuDNN: Efficient Primitives for Deep Learning
- Kernel Profiling Guide
- Perfworks: A Library for GPU Performance Analysis
- Exascale Deep Learning for Climate Analytics
- Machine Learning benchmarking at NERSC
- GTC Silicon Valley-2019 ID:S9412:Exascale Deep Learning for Climate Analytics
- Roofline Analysis Part 2 – Fast Insights to Optimized Vectorization & Memory
- Using the Roofline Modelautomation in Intel® Advisor to boost your application performance
- Application optimization with Cache-aware Roofline Model and Intel oneAPI tools
- Roofline Resources for Intel® Advisor Users
- Intel® Advisor
- Running a Roofline Analysis with Intel Advisor
- What is a Roofline Model?
- Collect Data on the Command Line
- IDEAS-ECP Webinar: Using the Roofline Model and Intel Advisor Webinar
- Roofline Performance Model
- Roofline Analysis on NVIDIA GPUs
- NERSC Staff Publications & Presentations
- Metrics and Design of an Instruction Roofline Model for AMD GPUs
- NERSC/timemory
- Timemory: Modular Performance Analysis for HPC
- An Empirical Roofline Methodology for Quantitatively Assessing Performance Portability
- An Instruction Roofline Model for GPUs
- Time-Based Roofline for Deep Learning Performance Analysis
- Roofline Analysis at NERSC
- Roofline Model Toolkit: A Practical Tool for Architectural and Program Analysis